Tuesday, January 11th 2022

AMD's Lisa Su Confirms Zen 4 is Using Optimised TSMC 5 nm Node, 2D and 3D chiplets
Anandtech asked AMD during a meeting at CES about the production nodes used to make its chips at TSMC and the importance of leading edge nodes for AMD to stay competitive, especially in light of the cost of using said nodes. Lisa Su confirmed in her answer to Anandtech that AMD is using an optimised high-performance 5 nm node for its upcoming Zen 4 processor chiplets, which there interestingly appears to be both 2D and 3D versions of. This is the first time we've heard a mention of two different chiplet types using the same architecture and it could mean that we get to see Zen 4 based CPUs with and without 3D cache.
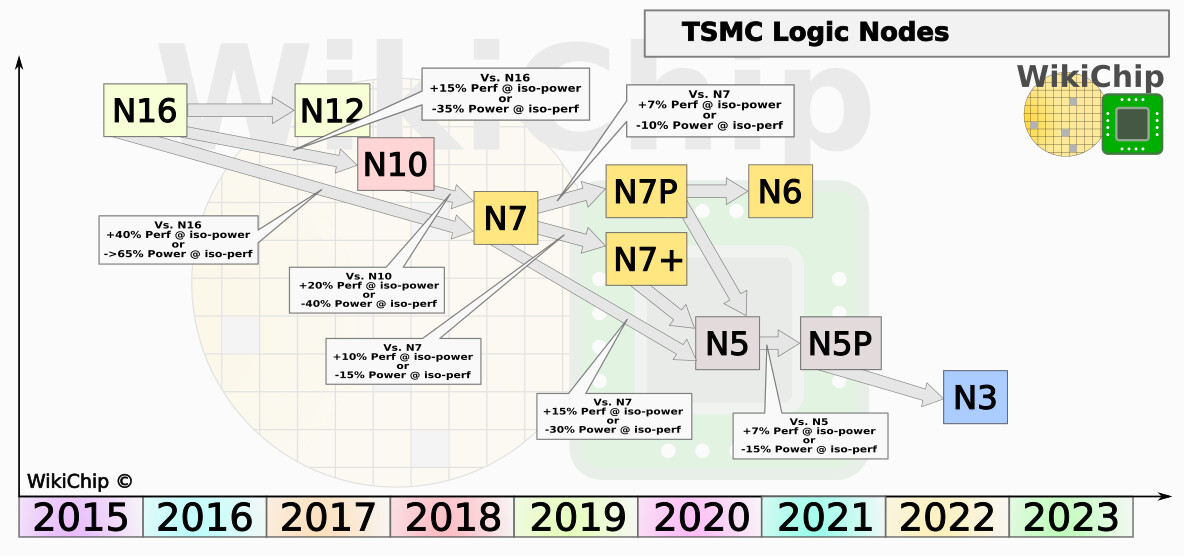
What strikes us as a bit odd about the Anandtech article, is that they mention the fact that several of TSMC's customers are already making 4 nm and soon 3 nm chips and are questioning why AMD wouldn't want to be on these same nodes. It seems like Anandtech has forgotten that not all process nodes are universally applicable and just because you can make one type of chip on a smaller node, doesn't mean it'll be suitable for a different type of chip. For the longest of times, mobile SoCs or other similar chips seem to always have been among the first things being made on new nodes, with more complex things like GPUs and more advanced CPUs coming later, to tweaked versions of the specific node. The fact that TSMC has no less than three 7 nm nodes, should be reason enough to realise that the leading edge node might not be the ideal node for all types of chips.
 In related news, TSMC is said to have accepted advanced payments of US$5.44 billion from at least 10 of its clients, of which AMD, Apple, Nvidia and Qualcomm are all mentioned. The payments have been done to secure production capacity, although for exactly how long time into the future isn't clear. TSMC saw advanced payments of US$3.8 billion in the first three quarters of last year and it's likely that these kinds of deals will continue as long as there's more demand than supply.
In related news, TSMC is said to have accepted advanced payments of US$5.44 billion from at least 10 of its clients, of which AMD, Apple, Nvidia and Qualcomm are all mentioned. The payments have been done to secure production capacity, although for exactly how long time into the future isn't clear. TSMC saw advanced payments of US$3.8 billion in the first three quarters of last year and it's likely that these kinds of deals will continue as long as there's more demand than supply.
Sources:
Anandtech, @dnystedt, WikiChip
What strikes us as a bit odd about the Anandtech article, is that they mention the fact that several of TSMC's customers are already making 4 nm and soon 3 nm chips and are questioning why AMD wouldn't want to be on these same nodes. It seems like Anandtech has forgotten that not all process nodes are universally applicable and just because you can make one type of chip on a smaller node, doesn't mean it'll be suitable for a different type of chip. For the longest of times, mobile SoCs or other similar chips seem to always have been among the first things being made on new nodes, with more complex things like GPUs and more advanced CPUs coming later, to tweaked versions of the specific node. The fact that TSMC has no less than three 7 nm nodes, should be reason enough to realise that the leading edge node might not be the ideal node for all types of chips.

28 Comments on AMD's Lisa Su Confirms Zen 4 is Using Optimised TSMC 5 nm Node, 2D and 3D chiplets
If the desktops are going to be divided w/wo Vcache, I'm really curious if it will be the entire lineups or other differentiation.
I wonder how Zen4 APUs would work with 3D cache.
A CCD to CCD link would probably help there but that is added cost and added complexity. There would be also the challenge of knowing what is in the second CCD and when to access it directly. AMD have pattern on that and is working on resolving this issue as it will become more and more a problem.
But we never know, maybe the price of the added cache will drop rapidly and it might be just few more bucks. Then yes, we will probably see a dual CCD with 3d v-cache. After all, AMD is supposedly producing a lot of those for the big cloud provider right now. This should reduce the cost in the end for consumers as production scale up.
The best scenario i think would be a 8 core CCD paired with something like Navi 24 (but with all video encoder/decoder please). Each could have a 64 MB of cache and i suspect that could make this APU way enough for good 1080p gaming. At the price of all GFX card, they could probably price it in a way that make sense.
-AM5 socket will likely persist longer than socket 1700, dont have to constantly replace motherboard every year to use new CPUs
-Zen4 process node advantage over intel, means less power, and maybe more performance without hybrid core weirdness and the half baked win11
-Intel is still stuck on 8 core CPUs, PCores are still 8 Cores, just getting more eCores in RL, do i need those on desktop, personally would rather have all PCores and more of them, but intel can't pull that off in a reasonable power and thermal budget. The eCores for multi thread aren't impactful for *my* workloads, i do realize many want them for their particular use cases.
Its too bad about HEDT, x299 hasn't been updated and left for dead, TR hasn't been updated either. Miss those PCIe lanes. If mainstream had a segment with even just 16 more CPU PCIe lanes....
On the other hand, there are cost optimisations that can be done too. Two dies (CCD + cache) have a better yield than a single bigger one. Cache die, they said, is made on a process optimised for its purpose. Also, *maybe* AMD can use the exact same cache die (6nm) for Zen 3 and Zen 4. It's often said that SRAM scales poorly when going to finer nodes, so they could possibly calculate that going to 5nm is not worth the cost.So they could price it in any way they desire and it would still be competitive?Chipmakers can't afford to use non-optimised processes. Every 0.1% of yield gained or lost is many million $ gained or lost. So you can believe it when they say that.
But the main point is on desktop, the main type of workload that benefits from larger cache is gaming (and maybe compression/decompression). For gaming, it's always best to run the game inside a Single CCD as much as possible so the game won't benefits from the larger cache on the second CCD. So having an extra cache on another core that could use TDP and lower the overall clock could lead to slower performance too. Well it may just not be worth the cost. Although they could still do it for people that just want to buy the top of the top.
Right now, it's as fast to access RAM than having to do another lookup on the next CCD so if the data is not in the local L3, it just grab it from RAM. It's really only for core to core communication that a cache access will be made on the second CCD.That seems a bit arbitrary. I really doubt that the current manufacturing process for stacked tie is the best it will ever be and no cost reduction and volume saving can be made.That is true, but 2 die without vcache will have better yield than 2 die with since there will always be some level of defect.Up to a certain point. But a decent APU could be sold in this market around 400-600$ without too much problem. There would also be a very good market for SFF desktop or "console like PC" if it can do up to 1440p, it could cost even higher.
I guess the Lost in your name means you are truly lost, thinking yourself as a know-it-all.
OptaneEmpire strikes back ;)It is different, but I just couldn't resist...
Also single die cpus can be split into 2 SKUs, with and without extra cache.
L1 and L2 cache exist for a reason. L3 cache can be made as arbitrarily complex as they want. As long as L3 cache is faster than DDR4 / DDR5, then it does the job.
IIRC, L3 cache even operates on its own clock: the Infinity Fabric clock instead of the core-clock on Zen+ processors. In Intel processors, L3 cache is also on its own clock IIRC. L3 is already incredibly complex with very high latency characteristics.Latency wise, that's correct. This is a big weakpoint of the multiple-die approach AMD has made, and why its so important for AMD to increase the size of its cache. In effect, an Intel chip with 40MB of L3 cache could have (in some use cases) better performance than AMD's 2x32MB of L3 cache. Since the "other 32MB" sits on another core that's slower than main-RAM / DDR4/5, the other 32MBs doesn't help.
Only in "fully parallel" situations (where the other socket is working on a completely different problem with no sharing of data) does the other 32MB help. Fortunately, that's called "Virtual Machines" today, so AMD EPYC / Zen works out for many people's problems. I expect the video-game market to be better on the "Intel-style 40MB L3" cache scenario, rather than "32x2 MB L3 cache".
Of course, AMD can fix that by just making every die have +64MB of L3 cache (96MB total per die). Its brute force and inelegant, but you can hardly disagree with the results or theory.
At least that's my theory anyway
3DV for some number of skus not requiring an IO chiplet. ie..6 and 8 core. Multi-chiplet skus will all be non-3DV
If you read the comments on Anandtech, their own readers are pretty much saying the exact same thing.
You're having a go at me without knowing anything about me. I've been writing about this stuff for over 20 years, I've been to Intel's fabs, I've been to GloFo fab conferences and I've met the people that started a lot of the tech sites that carry their names to this day, but are no longer working there themselves. But yeah, I'm the one that's lost and that is a know-it-all, because I'm just some random person on a forum... Honestly dude, maybe at least check up on who you're having a go at first.
You don't have to agree with my thoughts on what Ian wrote, but as I said, he should really know better in this case, as low power nodes aren't suitable for making desktop CPUs and GPUs and that's common industry knowledge that he also has.Most important, maybe not, but it's obviously a top three factor, since the most important one is being that the foundry has a suitable node for your chip design, since you always have a design target and changing that design target is apparently a 6-12 month job in most cases. Then there's allocation, as if you get none, you're not making any chips. After that, cost I would say. Qualcomm is actually quite far behind on the nodes, as they went with Samsung something or the other at 8 nm or below, whereas Apple is at TSMC's 4 nm and supposedly on whatever node TSMC is working on next, since Apple is pretty much paying for TSMC's push towards smaller and smaller nodes. Samsung is going to be behind MediaTek if they really are going to be on the 3 nm node this year.
It's also not really about a "flashy node", most of these companies can't advanced their products without a node shrink. That's actually what was quite impressive with Nvidia, they managed to squeeze out a lot of extra performance while being stuck on the same node for three generations (Fermi, Kepler and Maxwell), something that is quite rare. It goes to show that some companies are capable of making do with what's available. Obviously Intel was stuck for a very long time, but then again, we didn't see nearly as good performance advances from them as Nvidia managed.
As mentioned above, AMD has to wait because they need to be on what used to be called a high power version of the node, as the low power versions used for MCUs and ARM/RISC-V/MIPS based SoCs, are not suitable for desktop CPUs and GPUs. This has been the case for as long as I've been writing about this stuff, which is as I mentioned, over 20 years by now.Will we even get quad core Zen 4 based CPUs?