Thursday, August 4th 2022

Potential Ryzen 7000-series CPU Specs and Pricing Leak, Ryzen 9 7950X Expected to hit 5.7 GHz
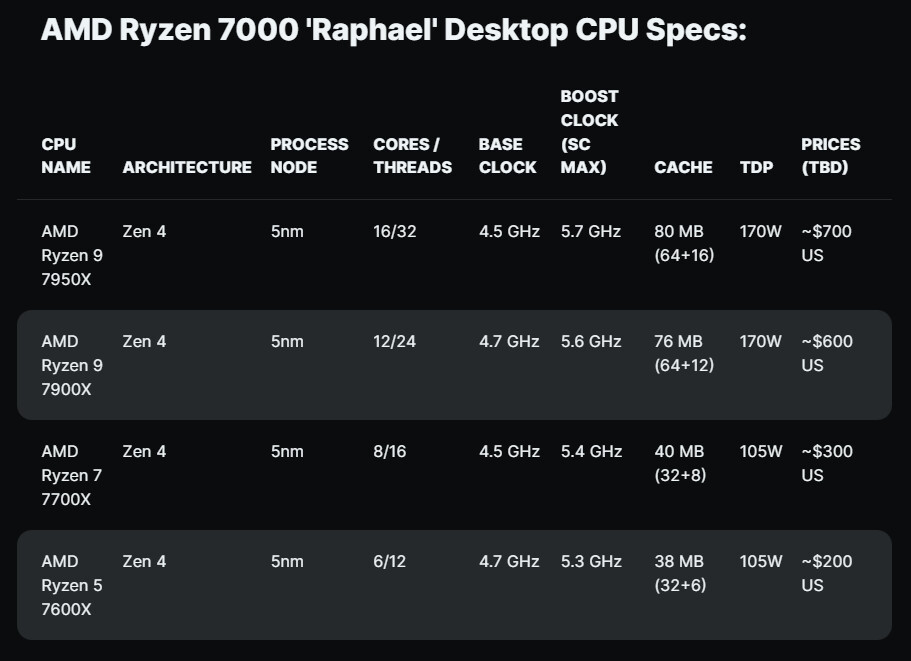
It's pretty clear that we're getting very close to the launch of AMD's AM5 platform and the Ryzen 7000-series CPUs, with spec details and even pricing brackets tipping up online. Wccftech has posted what the publication believes will be the lineup we can expect to launch in just over a month's time, if rumours are to be believed. The base model is said to be the Ryzen 5 7600X, which the site claims will have a base clock of 4.7 GHz and a boost clock of 5.3 GHz. There's no change in processor core or thread count compared to the current Ryzen 5 5600X, but the L2 cache appears to have doubled, for a total of 38 MB of cache. This is followed by the Ryzen 7 7700X, which starts out a tad slower with a base clock of 4.5 GHz, but it has a slightly higher boost clock of 5.4 GHz. Likewise here, the core and thread count remains unchanged, while the L2 cache also gets a bump here for a total of 40 MB cache. Both these models are said to have a 105 W TDP.
The Ryzen 9 7900X is said to have a 4.7 GHz base clock and a 5.6 GHz boost clock, so a 200 MHz jump up from the Ryzen 7 7700X. This CPU has a total of 76 MB of cache. Finally the Ryzen 9 7950X is said to have the same base clock of 4.5 GHz as the Ryzen 7 7700X, but it has the highest boost clock of all the expected models at 5.7 GHz, while having a total of 80 MB cache. These two SKUs are both said to have a 170 W TDP. Price wise, from top to bottom, we might be looking at somewhere around US$700, US$600, US$300 and US$200, so it seems like AMD has adjusted its pricing downwards by around $100 on the low-end, with the Ryzen 7 part fitting the same price bracket as the Ryzen 7 5700X. The Ryzen 9 7900X seems to have had its price adjusted upwards slightly, while the Ryzen 9 7950X seems to be expected to be priced lower than its predecessors. Take these things with the right helping of scepticism for now, as things can still change before the launch.
Source:
Wccftech
The Ryzen 9 7900X is said to have a 4.7 GHz base clock and a 5.6 GHz boost clock, so a 200 MHz jump up from the Ryzen 7 7700X. This CPU has a total of 76 MB of cache. Finally the Ryzen 9 7950X is said to have the same base clock of 4.5 GHz as the Ryzen 7 7700X, but it has the highest boost clock of all the expected models at 5.7 GHz, while having a total of 80 MB cache. These two SKUs are both said to have a 170 W TDP. Price wise, from top to bottom, we might be looking at somewhere around US$700, US$600, US$300 and US$200, so it seems like AMD has adjusted its pricing downwards by around $100 on the low-end, with the Ryzen 7 part fitting the same price bracket as the Ryzen 7 5700X. The Ryzen 9 7900X seems to have had its price adjusted upwards slightly, while the Ryzen 9 7950X seems to be expected to be priced lower than its predecessors. Take these things with the right helping of scepticism for now, as things can still change before the launch.
277 Comments on Potential Ryzen 7000-series CPU Specs and Pricing Leak, Ryzen 9 7950X Expected to hit 5.7 GHz
Zen4 pricing does look ok if it turns out to be true. Hopefully it will.
Regarding the rest of what you said, 1p core absolutely creams a zen 3 core at same wattage in every workload. The difference is so vast that not even zen 4 can close it. Therefore it stands to reason that a 16p core intel would have no problem with power or heat
You have a 5800x. Choose a benchmark - the best case scenario for zen 3 - choose a power limit , again , the best case scenario for zen 3 and upload yours score. Ill upload my score at the same benchmark and same power limit with 8 GC cores, I guarantee you zen 3 will get creamed. Especially if we run performance normalized, for example in CBR23 8zen 3 cores need more than double the wattage (and probably some ln2 cooling) to tie the performance of 8gc cores at 65w.
Rather than testing at the manufacturer-specified power limits, you are arguing for testing at an arbitrary lower limit, but crucially one that is very close to AMD's spec, while very far from Intel's spec. You see how that is problematic, right? How that inherently biases the testing towards one manufacturer? You can keep talking as if iso power = a level playing field all you like, but that isn't reality - reality is that chips come with manufacturer specified power limits, which differ from chip to chip, and any test setting that isn't this number is thus either a reduction or increase from this, and a different reduction or increase between various SKUs. You can't simply ignore the stock setting and say "this is a level playing field because the number is the same". Testing both at 125w, as you are doing, is a whopping 50% (125W) reduction for the Intel chip, while it's a 15% reduction for the AMD chip (19W). Is that a level playing field? No.
Now, is this unfair? Yes, because of architectural differences and how voltage/frequency scaling works. As you yourself keep bringing up regardless of its relevance to what we're discussing, DVFS curves are precisely that - curves. The higher you push an implementation of an architecture, the more voltage and power you need. Which of course means that conversely, the more you drop the power level from a high point on that curve, the better efficiency you will get out at the end. So, by implementing different changes from stock, you are inherently privileging Intel in your comparisons.
Of course, you can argue that Intel's stock config is dumb. Which it is. But that doesn't change the fact that the stock power limit is an inherent trait of the CPU as purchased. It is a configurable one, true, but it is still an inherent trait of the product, and ignoring it doesn't make that any less true.
As for per-core efficiency between Zen3 and ADL: you're just plain wrong there, sorry. Let's take a look at Anandtech's ST testing in SPEC, which is a relatively diverse set of workloads and about as accepted of an industry standard as you get for general computational performance for a CPU:
ADL at its stock clocks (which they measured to 71W over idle in another workload, but might of course be somewhat lower in this, as power is inherently workload-dependent) beats peak Zen3 (5950X) by either 16% or 12% in integer workloads and either 6% or 4% in floating point workloads depending on whether you look at the DDR4 or DDR5 results. You can see detailed per-workload scores in the article here. If you're curious about what the SPEC workloads are, you can read more about them here - it's a pretty good mix of consumer-relevant workloads and more scientific/industry-oriented ones.
Now, there's the question of power. Neither of these chips come close to their stock power limits in ST testing - as I said, the 12900K peaks at 71W with one core active; the 5950X peaks at 49W package power for the same. Sadly we don't have specific power numbers for each of these tests, which introduces a lot of error into any estimates made based on what we have. Still, unless the workload Anandtech uses for power testing happens to be an extreme outlier on Alder lake, ADL needs approximately ~45% more power for (best case) 16% more performance. Yes, this is at an extreme, stupid power level. But it also directly disproves your statement thatThis is, again, pure, unadulterated nonsense. ALD is barely faster than Zen3 at much higher clocks and power levels. Dropping those clocks will inevitably mean a drop in performance, and even if ADL at stock is pushed way past its efficiency sweet spot (which it is!), you're still not going to match that stock Zen3 ST efficiency without incurring a noticeable performance penalty. That's just reality.
Does that mean there aren't workloads where ADL wins out in ST efficiency? Obviously not! It's not a terrible architecture at all - it just has some weird and contradictory characteristics. But the claims you're making here are just plain nonsense. They bear no relation to reality.
And it makes sense, adl is way wider than zen 3, way bigger die with more performance. Its not surprising at all that its faster / more efficient than zen 3.Yes it does change the fact cause we are talking about a theoretical 16p core. Nothing is stopping intel from keeping or reducing the power limit when if it decides to release such a CPU. Intel can decide what that inherent value they want their CPU to have, therefore that's not whats stopping them fromr eleasing a 16p core CPU. In fact they could release one with a 130w power limit that would cream both the 5950x and the 12900k. That's all im saying
Also according to anandtech, this is the power consumption under spec
In SPEC, in terms of package power, the P-cores averaged 25.3W in the integer suite and 29.2W in the FP suite, in contrast to respectively 10.7W and 11.5W for the E-cores, both under single-threaded scenarios. Idle package power ran in at 1.9W.
Side note though. Bro, you're quite pent up about Intel losing their dominance or whatever. It's good that both companies are at each other's throats when it comes to this, it means cheaper hardware for us! If Alder Lake hadn't come out, AMD would never back down from their earlier excuses and statements on 300 series boards, would not have released SKUs such as the 5600, 5700X or 5800X3D, and if it didn't perform like it does (remember Rocket Lake), they would happily ask $1750 for the 5950X.
I remember the days that I needed to buy a Core i7 Extreme to get the best performance, and nowadays the maximum performance spot for gaming is actually a little below the halo part (that being the 5800X3D currently), and you will do GREAT with a chip like the 5600X or the 12600K. I can't say that I miss having to spend $999 on a processor at all, even if it means losing the "wow cool my rig is preposterous" factor out there. :oops:
Of course, there's also the question of architectural changes needed to implement 16 P cores - most likely that would mean moving to either a dual ring bus or mesh, as AFAIK Intel has never used a single ring bus above 10 cores/stops (the groups of 4 E cores have a single ring bus stop). Which would harm efficiency as more power would need to be used for uncore, bringing the base power requirements closer to Zen3. Of course a mesh or dual ring bus would also affect core-to-core latencies and task scheduling, though a single, 16-core ring bus would likely cause untenable levels of core-to-core latency. Either way, scaling isn't entirely simple.If I had the time to do something like this in a meaningful amount of workloads (and had access to SPEC or something similar, but unfortunately I don't have $1250 to spare) I'd be down to do a comparison, though these being extremely different systems that'd still be rather problematic. We wouldn't be able to normalize for software or anything else really, unless you also wanted us to reinstall Windows for this. The point being: there's a reason why reviewers exist, as they have access, time, equipment and means to do things most end users don't. Beyond that, thankfully we have good reviews to base our predictions and speculations on, like the ones linked above.
ADL is definitely a wide core, but its actual, real-world performance still isn't vastly ahead of the somewhat narrower Zen3 - as shown in the benchmarks posted and linked above. It's faster, but only because it also clocks notably higher.AFAIK we haven't been talking about a theoretical 16 P-core CPU all this time? Either way, yes, there is something stopping Intel from reducing its power limits overall: competitive positioning. The 12900K needs its stupid high power limit to be clearly faster than the 5950X (and it still isn't so across the board, but in most cases). Whether they could release a 16 P-core CPU for LGA1700 and have it deliver competitive performance at 250W is ... well, something we can speculate on, but from my perspective there are too many unknowns to this to draw hard conclusions, as discussed above. It's not as simple as "twice the CPU cores of a 12900K, done". Heck, with a die that large (that would be, what, 300, 350mm²?), there's even a question of whether they could fit that on the LGA1700 package and connect all the I/O and power to it properly - there needs to be room to route traces through the package for everything, and a larger die makes that more difficult. Not saying it's impossible, just that it's another unknown. As for releasing a 130W 16 P-core CPU that would beat the 5950X? Keep dreaming. That just isn't happening, even if Intel wasn't forced by competition from AMD to push their CPUs to the max.I don't agree here - it has four distinct benefits as I see it: increased core counts without ballooning area and thus cost; increased performance in anything nT like tile-based renderers or video encoding; lower power general purpose, low-performance usage; allowing for efficient background processing of relatively heavy tasks like video encoding without throttling the main P cores too hard. The latter is the least likely, as it's extremely dependent on a good scheduler, but both of the former three are real benefits today.Here I truly agree with you though. That AMD stepped up their game with Ryzen was truly needed, but we were also seeing AMD grow into a too-comfortable leadership position with Zen3, and ADL delivered a much-needed kick in the rear to keep them accountable. Not that the chip shortage helped, but that's not the fault of anybody specific - AMD just did what corporations do: squeezed money out of it. We definitely can't attribute the 5800X3D to ADL though - the vias to connect 3D V-cache to Zen3 are there on all Zen3 dice, so that has been the plan from day one. The timing just worked out for AMD - and it's of course possible that they may not have released a relatively affordable "flagship killer" gaming CPU with that cache, but rather pushed it towards workstations or just made it very expensive if ADL hadn't been as fast.
Still, it's pretty clear that fevgatos is for some reason extremely defensive of Intel and ADL. I'm not going to speculate as to the reasons, but this kind of behaviour just doesn't help anyone. I can agree that discussions of ADL have tended towards too much of "OMG what a power hog", but ... well, it is. It's still good, and underclocks and undervolts well, but it is a power hog at stock. From my perspective, it looks like they're trying to add nuance to the discussion but the only thing they're able to do is present even more biased, absurd statements in the opposite direction of other people. Which utterly fails to add nuance, but instead foments polarization and just breeds conflict. Either way, not a good approach.
All of this hype is nonsense. The price increases will be there and so is the increase of wattage as well. Before I even think of building a new rig and that is what is going to happen to most of us I want to see the REAL overall cost of performance vs wattage over the previous generations components.
Because it looks like a X670 is going to be double the price of a X570 which was 50% over the X370. I have the X370 and X570 mb in question so I know the cost increases there.
This is where AMD is going to make their money. Selling the MB chipsets to their partners.
So, in short, ADL is quite wide, and specifically due to that it is a power hog at high clocks in heavy workloads. When the GC architecture was first discussed, people expressed concerns about the power hungry nature of expanding an X86 decoder beyond being 4-wide - and that's likely part of what we're seeing here. As instruction density rises, power consumption skyrockets, and ADL needs that 250W power budget to beat - or even keep up with! - Zen3 in low threaded applications. Remember, the 12900K reaches 160W with just 4 P-cores active, and creeps up on 200W with six of them active. None of which are at that 5.2GHz clock, of course.
Now, I spotted something looking back at the AT review that I missed yesterday: they note that in their SPEC testing, they saw 25-30W/core for ADL - which is obviously much better than 55-60W. They put this down to most SPEC workloads having much lower instruction density than POV-Ray, which they use for power testing. Still, assuming that ADL sees that 50% power drop in SPEC compared to POV-Ray and Zen3 sees none (which is quite unlikely!), that's still a 25-50% power consumption advantage per core for AMD. Which is somewhat offset by AMD's ~10W higher uncore power, but that ADL advantage disappears once you exceed two cores active due to Zen3's lower per core power.
Going back to the ST/MT comparison and clock/power scaling for ADL: Extrapolating from Anandtech's per core load testing, and assuming uncore under load is 23W (78W package power minus their low 1c estimate of 55W): 2P = 44W/c, 3P =36.7W/c, 4P =34W/c, 5P = 30,4W/P, 6P = 29W/c, 7P = 27.3W/c, 8P = 27W/P. That last number is, according to the same AT test, at around 4.7GHz. Which is definitely a lot better than 55W/core! But it's still 28% higher than Zen3's 21W (technically 20.6W) @ 4.9GHz. Now, ADL at 5.2GHz wins in SPEC ST by up to 16% (116% score vs. Zen3's 100%), with a 3% clock advantage (5.2 v 5.05GHz). Dropping its clocks to 4.7GHz, assuming a linear drop in performance, would drop that 16% advantage to a 4.8% advantage - and still at a presumable power disadvantage - or at best roughly on par. Sadly we don't have power scaling numbers per core for SPEC, but it's safe to assume that it doesn't see the same dramatic drop as POV-Ray, simply because it doesn't start as high.
And, crucially, all of this is comparing against Zen3's peak 1c power - and it too drops off noticeably as thread counts increase, with small clock speed losses. The 5950X maintains 20W/c up to 4 active cores, then drops to <17W at 5 cores (@4.675GHz), and ~14-15W at 8c active (@4.6GHz). Zen3 also shows massive efficiency scaling at lower clocks too, going as low as ~8W/core @4ghz (13 cores active) or ~6W/core @ 3.775 (16 cores active).
If we graph out the respective clock/power scaling seen here, we get these two graphs (with the caveat that we don't have precise frequency numbers for ADL per core, and I have instead extrapolated these linearly between its 5.2GHz spec and the 4.7GHz seenin AT's 8P-core power testing):
What do we see there? That Zen3's power is still dropping quite sharply at 16t active (3.775GHz), while ADL's P cores are flattening out in terms of power draw even at just 8 P cores active. We obviously can't extrapolate a line directly from these graphs and towards zero clock speed and expect it to match reality, but it still says something about the power and clock scaling of these two implementations - and it demonstrates how Zen3 scales very well towards lower power. As an added comparison, look at EPYC Milan: the core (not including IF/uncore) power of the 64-core 7763 is just 164W in SPECint, translating to a staggeringly low 2.6W/core, presumably at its 2450MHz base clock.
It is entirely possible - even essentially establlished knowledge, given the much better efficiency of lower spec ADL chips like the 12300 - that ADL/GC sees a downward step or increased drop in power/clock at some lower clock than what the 12900K reaches at 8 P cores active, but there's still no question that Zen3 scales far better than ADL towards lower clocks, an advantage somewhat offset by its higher uncore power, but nowhere near completely. ADL still has a slight IPC advantage, and wins out in ST applications that can take advantage of its high per-core boost even for lower spec chips + its low latencies. And it doesn't suffer as badly power-wise in less instruction dense workloads overall. But that doesn't make it more efficient than Zen3 - that simply isn't the case.And I don't care much about your pulled-from-thin-air numbers that do not account for the increased interconnect complexity and resultant core-to-core latency increase for such a larger die, or the other changes necessary for that implementation. Nor do you seem to grasp the issue of using CB as a single point of reference to somehow be the be-all, end-all reference point for performance. It's a single tiled rendering benchmark, with all the peculiarities and characteristics of such a workload - and isn't applicable to other nT workloads, let alone general workloads.You mean the up-to-60c, 350W TDP, perennially delayed datacenter CPU that Intel still hasn't released any actual specs for? Yeah, that seems like a very well functioning and unproblematic comparison, sure."Huge"? It's a 15% drop (or the 5800X runs 18% faster, depending on what's your baseline). It's clearly notable, but ... so what? Remember, at that point the 5800X runs literally twice the power per core compared to the 5950X. As seen above, Zen3 scales extremely well with lower clocks, and doesn't flatline until very low clocks. ADL, on the other hand, seems to flatline (at least for a while) in the high 4GHz range.
Heck, if you want to provide more data to challenge what I'm taking from AT's testing: run POV-Ray at your various power limits and record the clock speeds. CB is far, far less instruction dense than POV-Ray (in other words: it's a much lighter and lower power workload) and would thus let a power limited ADL CPU clock far higher, so you can't use your CB numbers as a counterpoint to AT's POV-Ray numbers.Oh, man, this made me laugh so hard. "You don't need an industry standard benchmark with a wide variety of different real-world tests baked in, there are hundreds of single, far less representative workloads you can try." Like, do you even understand what you are saying here? Cinebench is one test. SPEC2017 is twenty different tests (for ST, 23 for nT). SPEC is a widely recognized industry standard, and includes rendering workloads, compression workloads, simulation workloads, and a lot more. What you mentioned were, let's see, a rendering workload, a rendering workload, a rendering workload, and a compression workload. Hmmmmm - I wonder which of these gives a more representative overview of the performance of a CPU?
Come on, man. Arguing for CB being a better benchmark than SPEC is like arguing that a truck stop hot dog is a better meal than a 7-course Michelin star restaurant menu. It's not even in the same ballpark.As I said, I would if I had time and we had the ability to normalize for all the variables involved - storage speed, cooling, other software on the system, etc. Sadly I don't have that time, and certainly don't have the spare hardware to run a new Windows install or reconfigure my cooling to match your system, etc. We do not have what is necessary to do a like-for-like, comparable test run - and running a single benchmark like you're arguing for wouldn't be a represenative view of performance anyhow. So, doing so would at best result in rough ballpark results with all kinds of unkown variables. Hardly a good way of doing a comparison.
I dont really get why you are doing extrapolations when we have the CPUs and we can test them. Regarding zen 3 scaling better, that's absolutely false, and you can see that from the 12400. It's basically the worst GC core bin (it comes from a different die btw)and it ties the 5600x in performance / watt. Actually according to igorslab testing, the 12400 can get up to 65% more efficient than the 5600x. That's by far the worst P core binned part...im quoting from igorslab
Once again, you can put the score in relation to the power consumption in order to map the efficiency. The Core i9-12400 is even 64 percentage points more efficient than the Ryzen 5 5600X!
If you put power consumption and performance under full load into relation, then the Core i5-12400 only has to admit defeat to the Core i9-12900KF, which is the winner in the 125 watt limit. The Ryzen 5 5600X lands significantly further behind.
www.igorslab.de/en/intel-core-i5-12400-in-the-workstation-test-how-does-real-work-without-taped-e-cores-part-2/9/
Also TPUP does some single thread consumption tests. The 5950x needs 45w over idle for the single core test, while the 12900k only needs 36w. Even from anandtech in the Povray test, 8 GC cores at 4.9 ghz result in 240w package power - 30w per core. How much wattage do 8 zen 3 cores need at 4.9ghz and what is the performance at that point??
Since usiname offered to run some tests with his zen 3, suggest to him the best case scenario for zen 3, since you dont like cinebench. Im pretty sure 8gc cores will cream 8 zen 3 cores even in that best case scenario.
I dont get what the problem is with sapphire rapid? Yet, it got delayed for 2023, so what? It will have a 16P core part that we can compare directly with the 5950x and youll realise that zen 3 loses the efficiency war - and actually the difference is that vast that not even zen 4 can close it.
www.techpowerup.com/forums/threads/cinebench-r23-efficiency-race.297551/#post-4809252
$300 usd is decent for the 7700x if it holds true. However I could get a 5700x for $220 usd, plus cheaper DDR4..................guess just play the waiting game.
Cine is fine but all it does is show your Cinema4D performance, imo
The point being: I'm leaning on SPEC because it's a trustworthy, somewhat representative (outside of gaming) CPU test suite, and is the closest we get to an industry standard. And, crucially, because we have a suite of high quality reviews using it. I do not rely on things like CB as, well, the results are pretty much useless. Which chip is the fastest and/or most efficient shows us ... well, which chip is the fastest and most efficient in cinebench. Not generally. And the point here was something somewhat generalizeable, no? Heck, even GeekBench is superior to CB in that regard - at least it runs a variety of workloads.... I have explained that, at length? If you didn't grasp that, here's a brief summary: because we have absolutely zero hope of approaching the level of control, normalization and test reilability that good professional reviewers operate at.And, once again, you take a result from a single benchmark and present it as if it is a general truth. I mean, come on: you even link to the source showing how that is for a single, specific workload - and a relatively low intensity, low threaded one at that. Which I have acknowledged, at quite some length, is a strength of ADL.
These results fall perfectly in line with the fact that MCM Zen3 suffers in efficiency at lower power levels due to the relatively high power consumption of through-package IF. This is established knowledge at this point. This doesn't mean the ADL core is more efficient, it shows that the full ADL package is more efficient at low power levels - like I've highlighted several times above. MCM Zen3 simply can't scale that low due to the high uncore power from IF.1: TPU does power measurements at the wall, meaning full system power including every component + PSU losses. This introduces a lot of variability and room for error - IMO this is a severe weakness of TPU's testing methodology (but understandable due to the equipment costs of doing proper hardware power measurements). This is especially problematic for any low load scenario.
2: You are pretty much repeating back to me what I have already been saying: Zen3 has a high uncore power due to IF, and thus has a disadvantage at very low thread counts despite the cores themselves consuming far less power. Put it this way: That AMD 45W increase is something like 24W uncore + 21W core, while the Intel increase is more like 10W uncore + 26W core. Of course the addition of the system generally consuming more power when under load than at idle (RAM, I/O, cooling fans, etc. - at wattage deltas this low, everything matters), plus the effects of PSU efficiency and VRM efficiency all make these results essentially indistinguishable.
3: While the scores are very close, it's worth mentioning that the 5950X is faster than the 12900K in SuperPi. Though the usefulness of this ancient benchmark is... well, debatable for modern CPUs. Still - slightly higher power, slightly faster - things start evening out.Have you been paying attention at all? Whatsoever? I'm not interested in best case scenarios. I'm interested in actually representative results, that can tell us something resembling truth about these CPUs. I mean, the fact that you're framing it this way in the first place says quite a bit about your approach to benchmarks: you're looking to choose sides, rather than looking for knowledge. That's really, really not how you want to approach this.
And, again, unless it wasn't clear: there is no single workload that gives a representative benchmark score for a CPU. None. Even something relatively diverse with many workloads like SPEC (or GeekBench) is an approximation at best. But a single benchmark only demonstrates how the CPU performs in that specific benchmark, and might give a hint as to how it would perform in very similar workloads (i.e. 7zip gives an indication of compression performance, CB gives an indication of tiled renderer performance, etc.) - but dependent on the quirks of that particular software.
This is why I'm not interested in jumping on this testing bandwagon: because testing in any real, meaningful way would require time, software and equipment that likely none of us have. You seem to have either a woefully lacking understanding of the requirements for actually reliable testing, or your standards for what you accept as trustworthy are just far too low. Either way: this needs fixing.Sapphire Rapids has been delayed ... what is it, four times now? Due to hardware errors, security errors, etc.? Yeah, that's not exactly a good place to start for a high performance comparison. When it comes out, it won't be competing against Zen3, it'll be competing against Zen4 - EPYC Genoa.
As for your fabulations about what a 16c SR CPU will perform like at 130W or whatever - have fun with that. I'll trust actual benchmarks when the actual product reaches the market. From what leaks I've seen so far - which, again, aren't trustworthy, but they're all we have to go by - SR is a perfectly okay server CPU, but nothing special, and nowhere near the efficiency of Milan, let alone Genoa.
And, crucially, SR will be a mesh fabric rather than a ring bus, and will have larger caches all around, so it'll behave quite differently from MSDT ADL. Unlike AMD, Intel doesn't use identical core designs across their server and consumer lineups - and the differences often lead to quite interesting differences in performance scaling, efficiency, and performance in various specific workloads.This is part of the problem: The IOD is obviously a part of the CPU, so for any actual real-world CPU power consumption it needs to be included. But unlike the cores, it's a static load, so it doesn't scale with threads - leading to a higher baseline power for MCM Zen3. Meaning that MCM Zen3 will fall behind in efficiency at low power and threading (unless you're running a high power limit ADL in a very instruction heavy workload), but thanks to its much lower power individual cores will quickly overtake ADL as thread counts increase. All the while, @fevgatos mashes everything into a single, amorphous blob, failing to make crucial distinctions and generally being far too vague both in what specifically they're debating. Is it architectural efficiency? Is it efficiency of a specific CPU in a specific workload? Is it ST, MT or nT efficiency? Is it efficiency at a range of power levels, or at one or a few arbitrarily chosen power levels? And if the latter, what are the grounds for choosing these?Exactly. It's a hot dog. It might be a great hotdog, but it does not represent food in general.
Regarding SR, you are missing the point. It doesn't matter at all what it will be competing against, the argument I made was that 16GC cores would wipe the 5950x off the face of the Earth in terms of efficiency, the same way 8 GC cores wipe the 5800x. So when SR will be released and what it will be facing when it does is completely irrelevant to the point im making.