Intel Details its Ray Tracing Architecture, Posts RT Performance Numbers
Intel on Thursday posted an article that dives deep into the ray tracing architecture of its Arc "Alchemist" GPUs, which are particularly relevant with performance-segment parts such as the Arc A770, which competes with the NVIDIA GeForce RTX 3060. In the article, Intel posted ray tracing performance numbers that put it at-par with, or faster than the RTX 3060, which which it has traditional raster performance parity. In theory, this would make Intel's ray tracing tech superior to that of AMD RDNA2, because while the AMD chips have raster performance parity, their ray tracing performance do not tend to be at par with NVIDIA parts at a price-segment level.
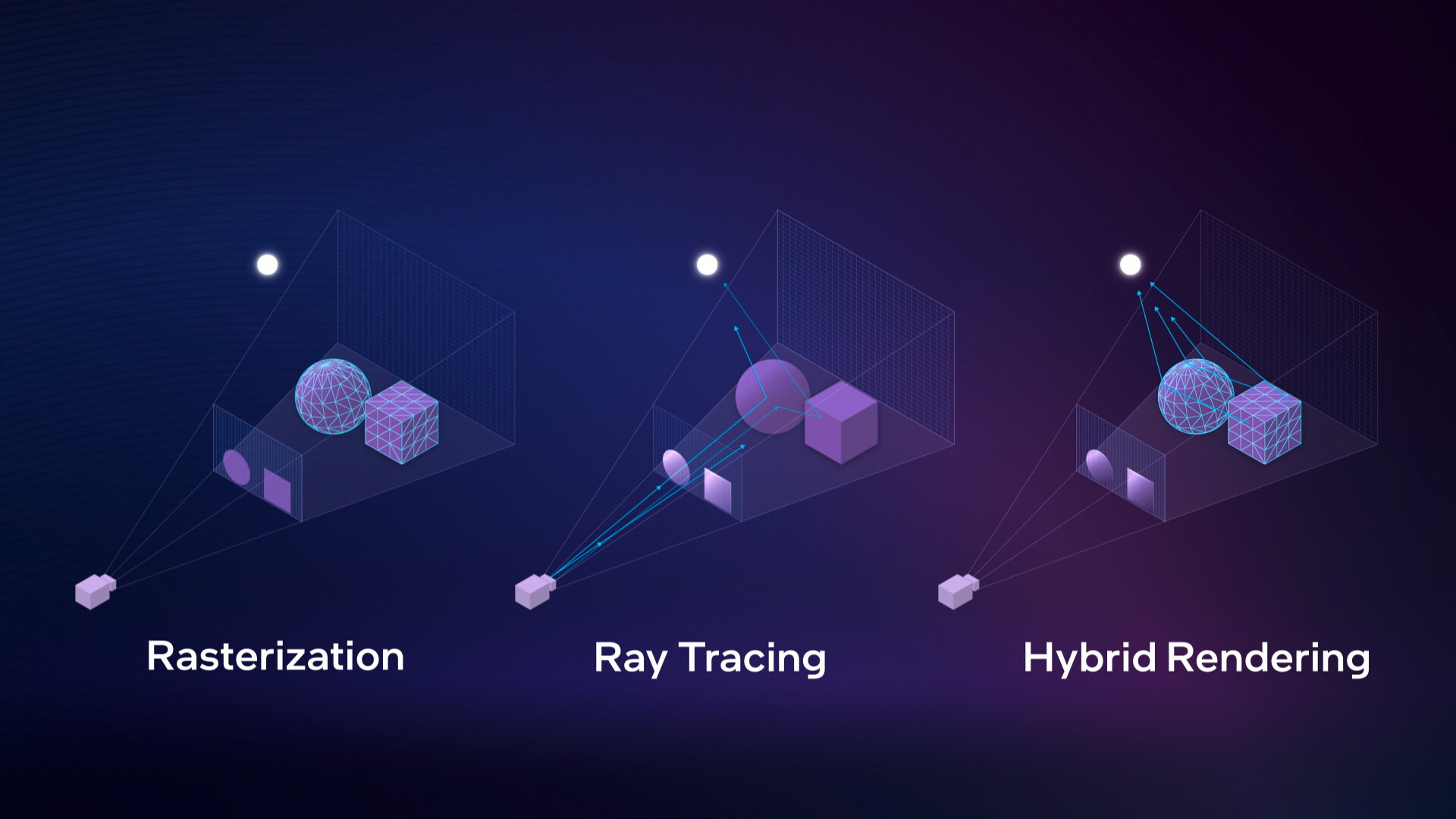
The Arc "Alchemist" GPUs meet the DirectX 12 Ultimate feature-set, and its ray tracing engine supports DXR 1.0, DXR 1.1, and Vulkan RT APIs. The Xe Core is the indivisible subunit of the GPU, and packs its main number-crunching machinery. Each Xe Core features a Thread Sorting Unit (TSU), and a Ray Tracing Unit (RTU). The TSU is responsible for scheduling work among the Xe Core and RTU, and is the core of Intel's "secret sauce." Each RTU has two ray traversal pipelines (fixed function hardware tasked with calculating ray intersections with intersections/BVH. The RTU can calculate 12 box intersections per cycle, 1 triangle intersection per cycle, and features a dedicated cache for BVH data.



The Arc "Alchemist" GPUs meet the DirectX 12 Ultimate feature-set, and its ray tracing engine supports DXR 1.0, DXR 1.1, and Vulkan RT APIs. The Xe Core is the indivisible subunit of the GPU, and packs its main number-crunching machinery. Each Xe Core features a Thread Sorting Unit (TSU), and a Ray Tracing Unit (RTU). The TSU is responsible for scheduling work among the Xe Core and RTU, and is the core of Intel's "secret sauce." Each RTU has two ray traversal pipelines (fixed function hardware tasked with calculating ray intersections with intersections/BVH. The RTU can calculate 12 box intersections per cycle, 1 triangle intersection per cycle, and features a dedicated cache for BVH data.