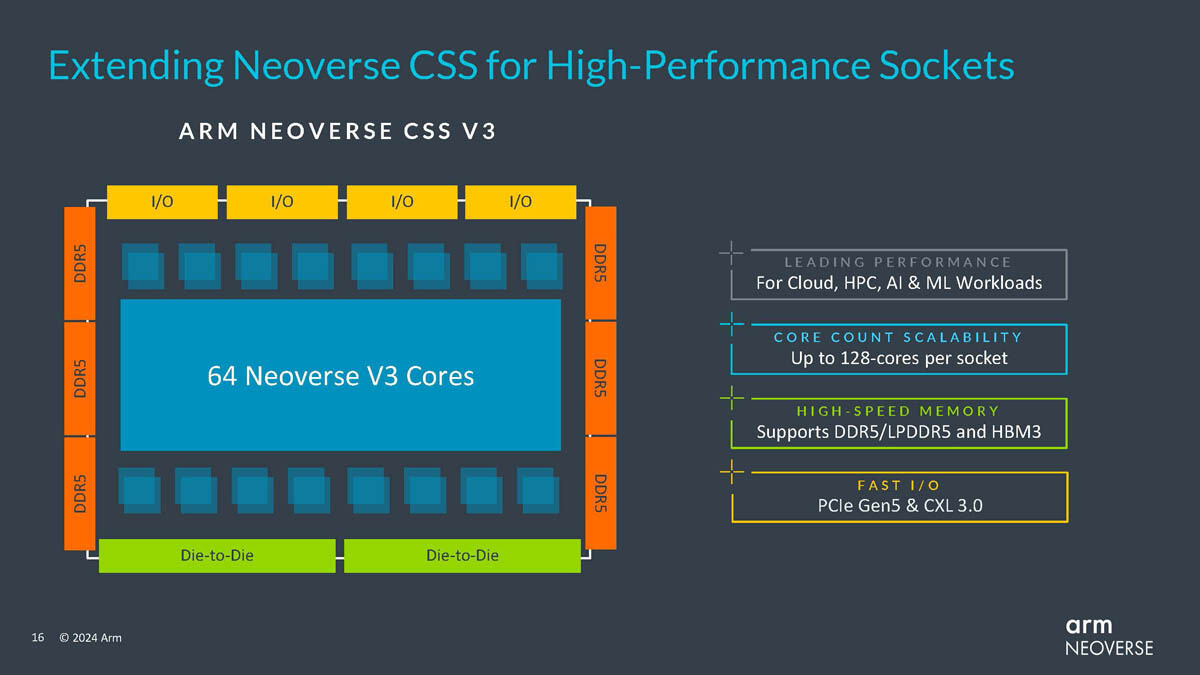
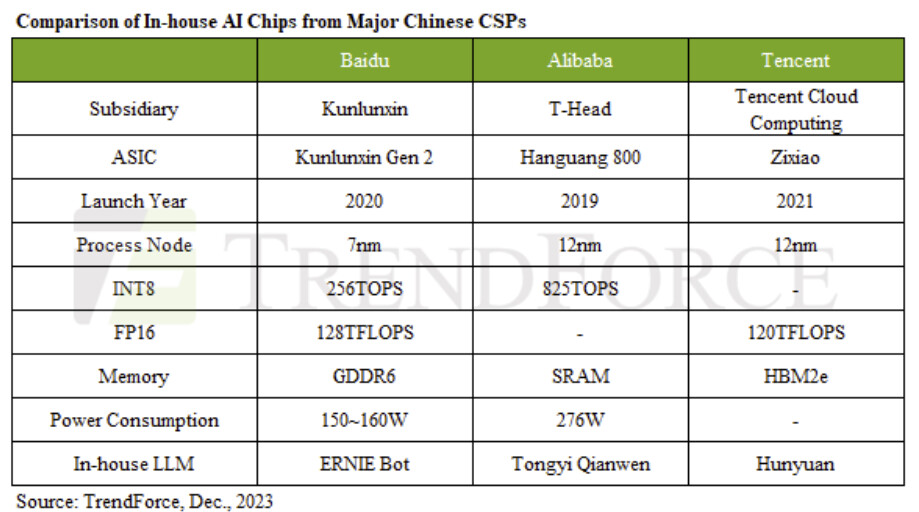
Global Top 10 Foundries Q4 Revenue Up 7.9%, Annual Total Hits US$111.54 Billion in 2023
The latest TrendForce report reveals a notable 7.9% jump in 4Q23 revenue for the world's top ten semiconductor foundries, reaching $30.49 billion. This growth is primarily driven by sustained demand for smartphone components, such as mid and low-end smartphone APs and peripheral PMICs. The launch season for Apple's latest devices also significantly contributed, fueling shipments for the A17 chipset and associated peripheral ICs, including OLED DDIs, CIS, and PMICs. TSMC's premium 3 nm process notably enhanced its revenue contribution, pushing its global market share past the 60% threshold this quarter.
TrendForce remarks that 2023 was a challenging year for foundries, marked by high inventory levels across the supply chain, a weak global economy, and a slow recovery in the Chinese market. These factors led to a downward cycle in the industry, with the top ten foundries experiencing a 13.6% annual drop as revenue reached just $111.54 billion. Nevertheless, 2024 promises a brighter outlook, with AI-driven demand expected to boost annual revenue by 12% to $125.24 billion. TSMC, benefiting from steady advanced process orders, is poised to far exceed the industry average in growth.
TrendForce remarks that 2023 was a challenging year for foundries, marked by high inventory levels across the supply chain, a weak global economy, and a slow recovery in the Chinese market. These factors led to a downward cycle in the industry, with the top ten foundries experiencing a 13.6% annual drop as revenue reached just $111.54 billion. Nevertheless, 2024 promises a brighter outlook, with AI-driven demand expected to boost annual revenue by 12% to $125.24 billion. TSMC, benefiting from steady advanced process orders, is poised to far exceed the industry average in growth.