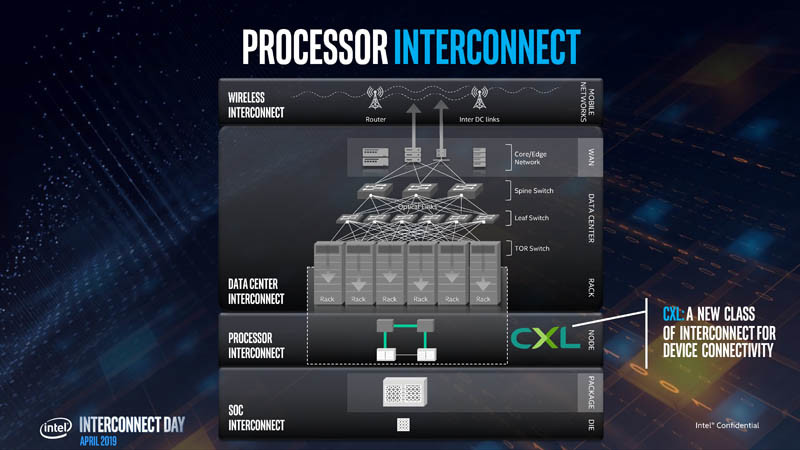
BittWare Announces PCIe 5.0/CXL FPGA Accelerators Featuring Intel Agilex M-Series and I-Series to Drive Memory and Interconnectivity Improvements
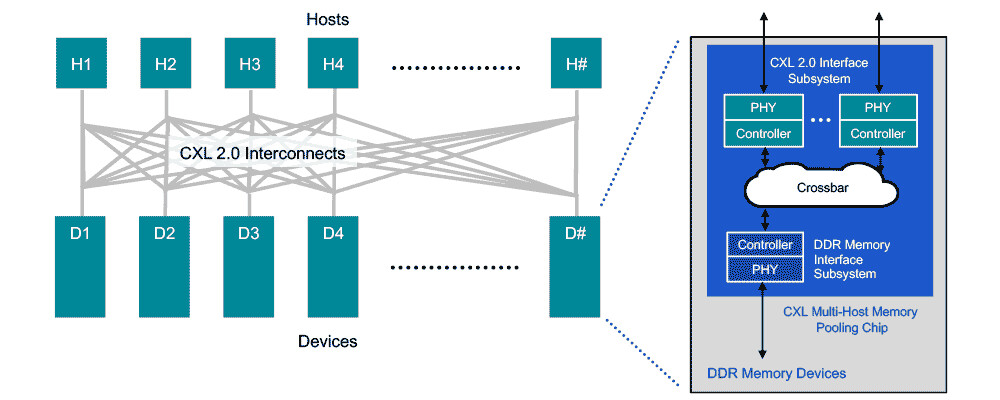
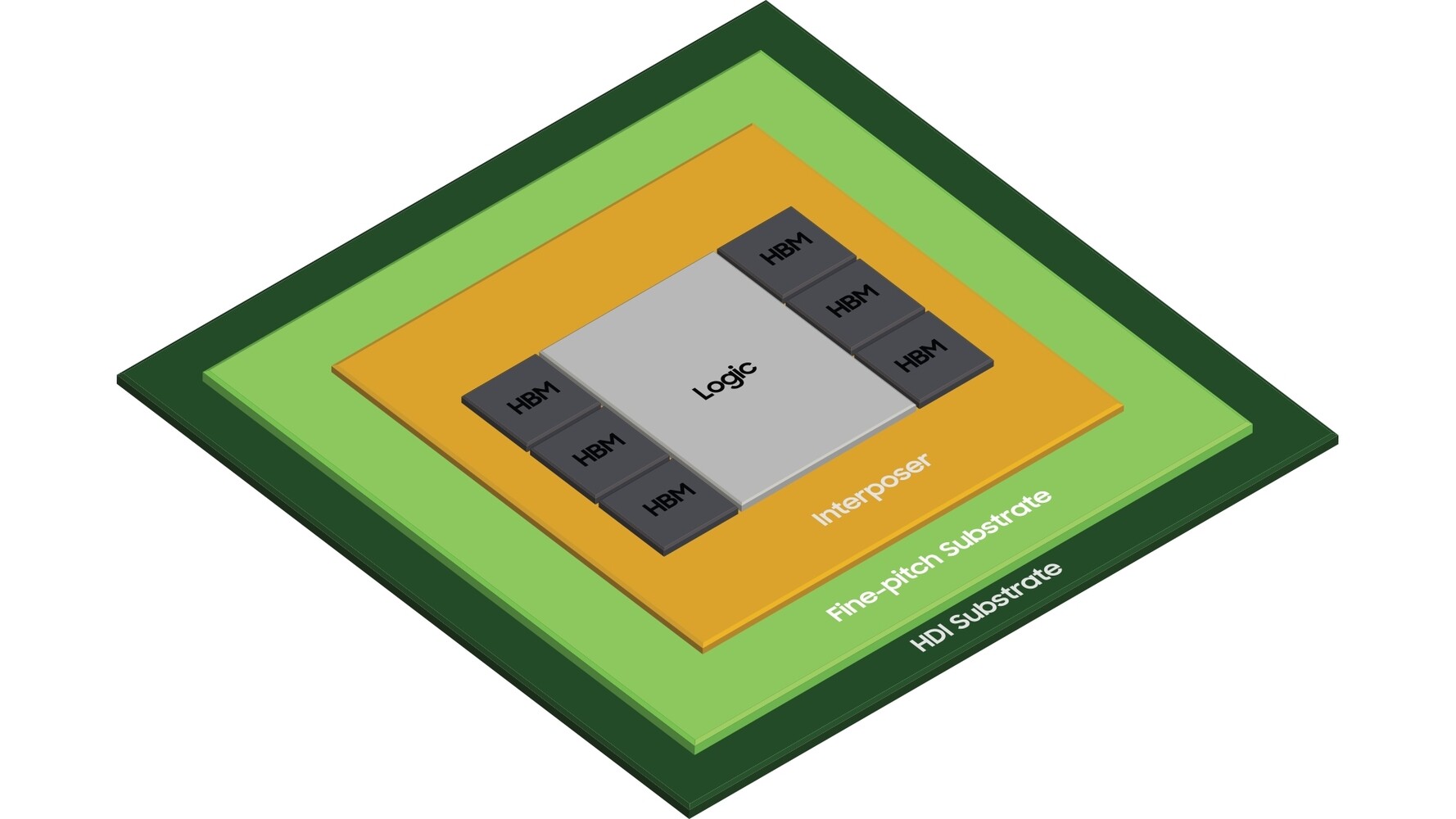
BittWare, a Molex company, a leading supplier of enterprise-class accelerators for edge and cloud-computing applications, today introduced new card and server-level solutions featuring Intel Agilex FPGAs. The new BittWare IA-860m helps customers alleviate memory-bound application workloads by leveraging up to 32 GB of HBM2E in-package memory and 16-lanes of PCIe 5.0 (with CXL upgrade option). BittWare also added new Intel Agilex I-Series FPGA-based products with the introduction of the IA-440i and IA-640i accelerators, which support high-performance interfaces, including 400G Ethernet and PCIe 5.0 (CXL option). These newest models complement BittWare's existing lineup of Intel Agilex F-Series products to comprise one of the broadest portfolios of Intel Agilex FPGA-based offerings on the market. This announcement reinforces BittWare's commitment to addressing ever-increasing demands of high-performance compute, storage, network and sensor processing applications.
"BittWare is excited to apply Intel's advanced technology to solve increasingly difficult application problems, quickly and at low risk," said Craig Petrie, vice president, Sales and Marketing of BittWare. "Our longstanding collaboration with Intel, expertise with the latest development tools, including OneAPI, as well as alignment with Molex's global supply chain and manufacturing capabilities enable BittWare to reduce development time by 12-to-18 months while ensuring smooth transitions from proof-of-concept to volume product deployment."
"BittWare is excited to apply Intel's advanced technology to solve increasingly difficult application problems, quickly and at low risk," said Craig Petrie, vice president, Sales and Marketing of BittWare. "Our longstanding collaboration with Intel, expertise with the latest development tools, including OneAPI, as well as alignment with Molex's global supply chain and manufacturing capabilities enable BittWare to reduce development time by 12-to-18 months while ensuring smooth transitions from proof-of-concept to volume product deployment."