Thursday, June 15th 2017

Intel Announces New Mesh Interconnect For Xeon Scalable, Skylake-X Processors
Intel's "Xeon Scalable" lineup is designed to compete directly with AMD's Naples platform. Naples, a core-laden, high performance server platform that relies deeply on linking multiple core complexes together via AMD's own HyperTransport derived Infinity Fabric Interconnect has given intel some challenges in terms of how to structure its own high-core count family of devices. This has led to a new mesh-based interconnect technology from Intel. When linking multiple core complexes together, Intel has traditionally relied on its QPI (Quick Path Interconnect) Interconnect, but it has its own limitations. For starters, QPI is a point to point technology, and it is inherently unsuitable for linking cores to cores in a mesh topology as is needed when random cores want to address each other. To work, you'd need to create a QPI link from every core to every other core on the chip, and that would be a waste of resources. Historically, to fill that gap Intel has used a "Ring bus." A ring bus functions similar to a token ring bus if you want to think of it in simple "old networking" terms. Basically, when data is transmitted, it must be passed around the bus like a token going from one speaker to the next. Each clock cycle, the bus can shift the data one way or another, but if you want to go say for example from one core to the farthest away one possible, latency suffers. In other words: This works fine for small dies, but as Intel seeks to create some true monsters, it's no longer enough.
When linking multiple core complexes together, Intel has traditionally relied on its QPI (Quick Path Interconnect) Interconnect, but it has its own limitations. For starters, QPI is a point to point technology, and it is inherently unsuitable for linking cores to cores in a mesh topology as is needed when random cores want to address each other. To work, you'd need to create a QPI link from every core to every other core on the chip, and that would be a waste of resources. Historically, to fill that gap Intel has used a "Ring bus." A ring bus functions similar to a token ring bus if you want to think of it in simple "old networking" terms. Basically, when data is transmitted, it must be passed around the bus like a token going from one speaker to the next. Each clock cycle, the bus can shift the data one way or another, but if you want to go say for example from one core to the farthest away one possible, latency suffers. In other words: This works fine for small dies, but as Intel seeks to create some true monsters, it's no longer enough.
There are some caveats to the above explanation (Intel's ring bus can have more than one "token" at a time in the analogy, and it's bidirectional, meaning data can travel both ways), but it still doesn't change the fact Intel is feeling this designs limits.
Enter the Mesh Interconnect:
Technically, this new Mesh Interconnect tech from Intel was introduced with the Xeon Phi Knight's Landing based products, but those are very exclusive, high end parts even for us mere enthusiast mortals. This launch represents the technology trickling down to a more mainstream market. To explain the tech, you simply have to forget everything you know about the ring bus chips used to use, and realize that now in the simplest chip implementations, each core has a direct "phone line" to every neighboring chip. It's a full mesh topology with all its benefits. In more complex arrangements, the "direct line to every chip" arrangement of course becomes uneconomical again, being it would require a harsh amount of resources for any chip maker to implement on massive chips the likes of which Naples and Xeon Scalable talk about. So instead, we go back to a simpler mesh topology, rows and columns.
Take this graphic, from Xeon Phi, to get an idea of how it works: Basically, it's a grid with a full XY routing system. This means rather than run around a huge bus-like circle, they can go through a much more compact "cube" topology and save time. In a simple 3x3 cube example, whereas it would take a total of 8 clock cycles on an equivalent ringbus for communications to reach the farthest core, the most it can take on a Mesh Interconnect based core is 4. (-X-X+Y+Y is how the worst case routing would look, if you've been following this in that level of detail).
Basically, it's a grid with a full XY routing system. This means rather than run around a huge bus-like circle, they can go through a much more compact "cube" topology and save time. In a simple 3x3 cube example, whereas it would take a total of 8 clock cycles on an equivalent ringbus for communications to reach the farthest core, the most it can take on a Mesh Interconnect based core is 4. (-X-X+Y+Y is how the worst case routing would look, if you've been following this in that level of detail).
If a lot of this goes over your head, don't worry, it's pretty technical low level stuff. The bottom line is Intel has an Interconnect that can compete roughly with AMD's Infinity Fabric in its own respect, and given Intel's larger core count on each die, AMD may be wise to keep a watchful eye on that fact.
The Mesh interconnect is scheduled to debut in the much more "mainstream" (if you can call them that) markets of Xeon Scalable and Skylake-X, due to launch soon this year.
Source:
Tomshardware.com

There are some caveats to the above explanation (Intel's ring bus can have more than one "token" at a time in the analogy, and it's bidirectional, meaning data can travel both ways), but it still doesn't change the fact Intel is feeling this designs limits.
Enter the Mesh Interconnect:
Technically, this new Mesh Interconnect tech from Intel was introduced with the Xeon Phi Knight's Landing based products, but those are very exclusive, high end parts even for us mere enthusiast mortals. This launch represents the technology trickling down to a more mainstream market. To explain the tech, you simply have to forget everything you know about the ring bus chips used to use, and realize that now in the simplest chip implementations, each core has a direct "phone line" to every neighboring chip. It's a full mesh topology with all its benefits. In more complex arrangements, the "direct line to every chip" arrangement of course becomes uneconomical again, being it would require a harsh amount of resources for any chip maker to implement on massive chips the likes of which Naples and Xeon Scalable talk about. So instead, we go back to a simpler mesh topology, rows and columns.
Take this graphic, from Xeon Phi, to get an idea of how it works:
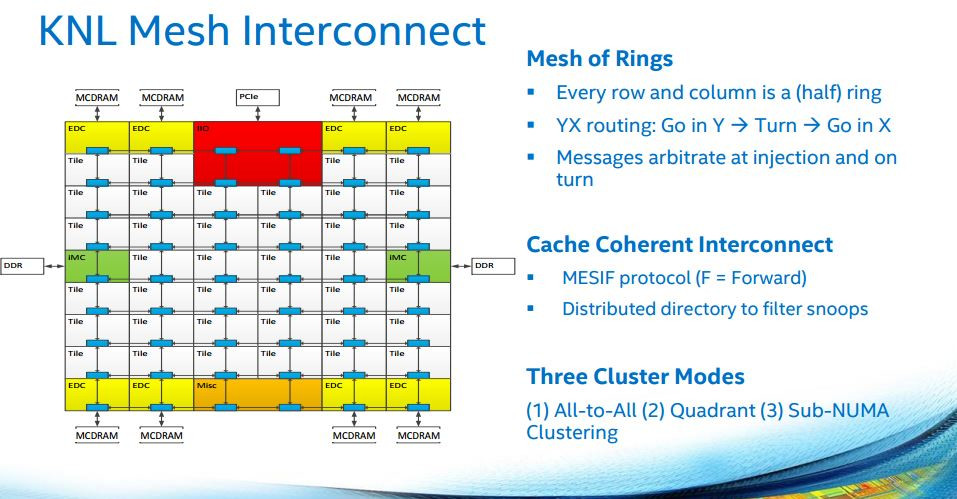
If a lot of this goes over your head, don't worry, it's pretty technical low level stuff. The bottom line is Intel has an Interconnect that can compete roughly with AMD's Infinity Fabric in its own respect, and given Intel's larger core count on each die, AMD may be wise to keep a watchful eye on that fact.
The Mesh interconnect is scheduled to debut in the much more "mainstream" (if you can call them that) markets of Xeon Scalable and Skylake-X, due to launch soon this year.
24 Comments on Intel Announces New Mesh Interconnect For Xeon Scalable, Skylake-X Processors
Their decisions sure are interesting. They could have done this years ago, but didn't. Now, it's all, "See, we have this stuff, too, look at us."
It must only be a matter of time (new architecture) until they direct copy and start slapping together MCMs, since yields are killing them on these large core counts.
Boss: Shit, AMD's new prcessors may screw up our financial report. Any ideas?
PR: more advertising? Pay editors and tech sites to spread FUD for AMD?
Management: Cut some jobs?
Engineers: Give us some resources so we can build better stuff?
Boss: Full on advertising mode PR team; and you can fire more engineers, management team. Let's take some bad Xeons and call them our I9
Wonder how much of the die is dedicated to cache coherency in this arrangement then? As thats Intel's biggest killer of clocks in high density parts.
WTF intel?!?!?!?!?!?!
Even in this article you'll find information that Intel has already used this tech in 2016.
You're such an Intel fanboy. Get a grip.
But they're obviously just parroting what AMD is doing at this point. You don't have to be a fanboy to see what's so obvious.
They are simply doing what they should have done years ago but didn't because the money was flowing in anyway.
Now they are investing money to make their product better and more competitive (with a very obvious and cheap way to rise performance).
Let's all rejoice AMD hit good and hard with a great product.
Mesh interconnect was already used in a 2016 Xeon Phi, but was merely a complicated technical feature - hidden deeply in the architecture documentation. Now they've pushed it into spotlight - exactly what AMD did with Infinity Matrix.
Personally, I'm not a huge fan of what's happening. I don't like the whole Ryzen marketing campaign (flashy, gaming-themed) and I really hope Intel will keep their cool, business-oriented image. But I guess this CPU segment is meant for geeks mostly (like people on TPU :) ) and they need to push some technical stuff to the surface. Enough to generate topics like this one, but not very technical, so that you don't have to be a physicist or electrical engineer to participate in a discussion.
To begin with, I like the fact that Intel kept the original name (mesh interconnect) from Xeons and didn't replace it with something more "sci-fi". Honestly, "Infinity Matrix" sounds like a weapon from Marvel Universe.Exactly. They used it in enterprise-grade systems and had a year for further improving. It should be relatively problem-free compared to Zen.
When will it be available in Xeon/Skylake-X mobos and actually ship?
We don't need more paper launches and I doubt many here will buy Knights Landing for gaming.
If it was ready, Intel would have announced it now.
Second most important question:
Will this obsolete X299 platform before it is even out?
Additionally, the nodes near the 'middle' of the mesh will have much more traffic going through them then any of the 'edge' nodes. When this scales large enough (100+) that effect will somewhat dissipate but for <20 cores it will probably be substantial.
My guess is they started working on this tech a few years ago when they realized they would need it, and they still won't have it perfected to the level AMD has it for another 2 years at least.
But support still need to be engineered and added to the OS.
Lets just repeat this once again, because it seems many of you didn't read the whole text (or previous comments).
You talk about this tech like if it was still being developed and a huge mystery. Mesh interconnect exists - Intel has already used it in their top CPUs. Now it's simply being implemented in cheaper models.Prepare to be surprised.
Whats going here?
In a mesh topology each node (core) communicates only with its neighbours. This solution uses a rectangular grid model, so each core has 4 neighbours.