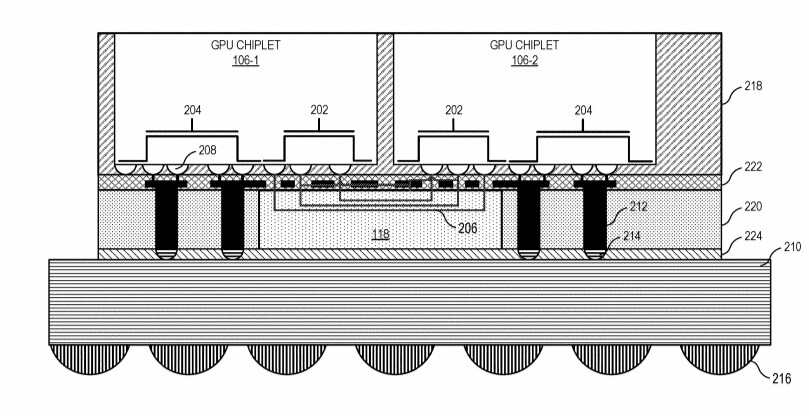
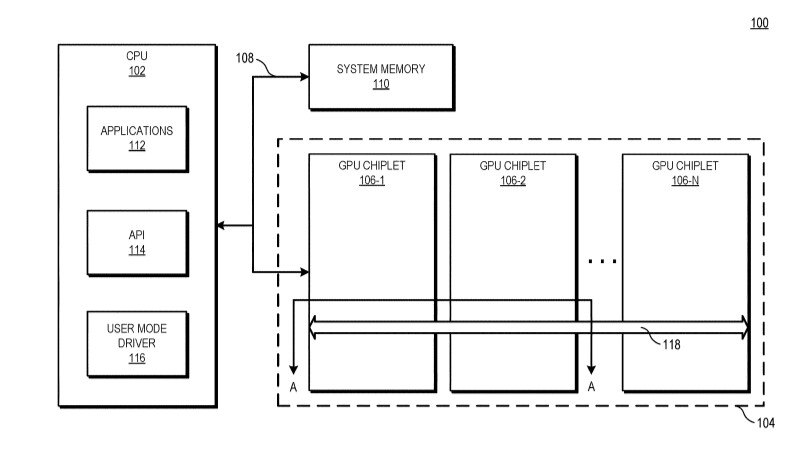
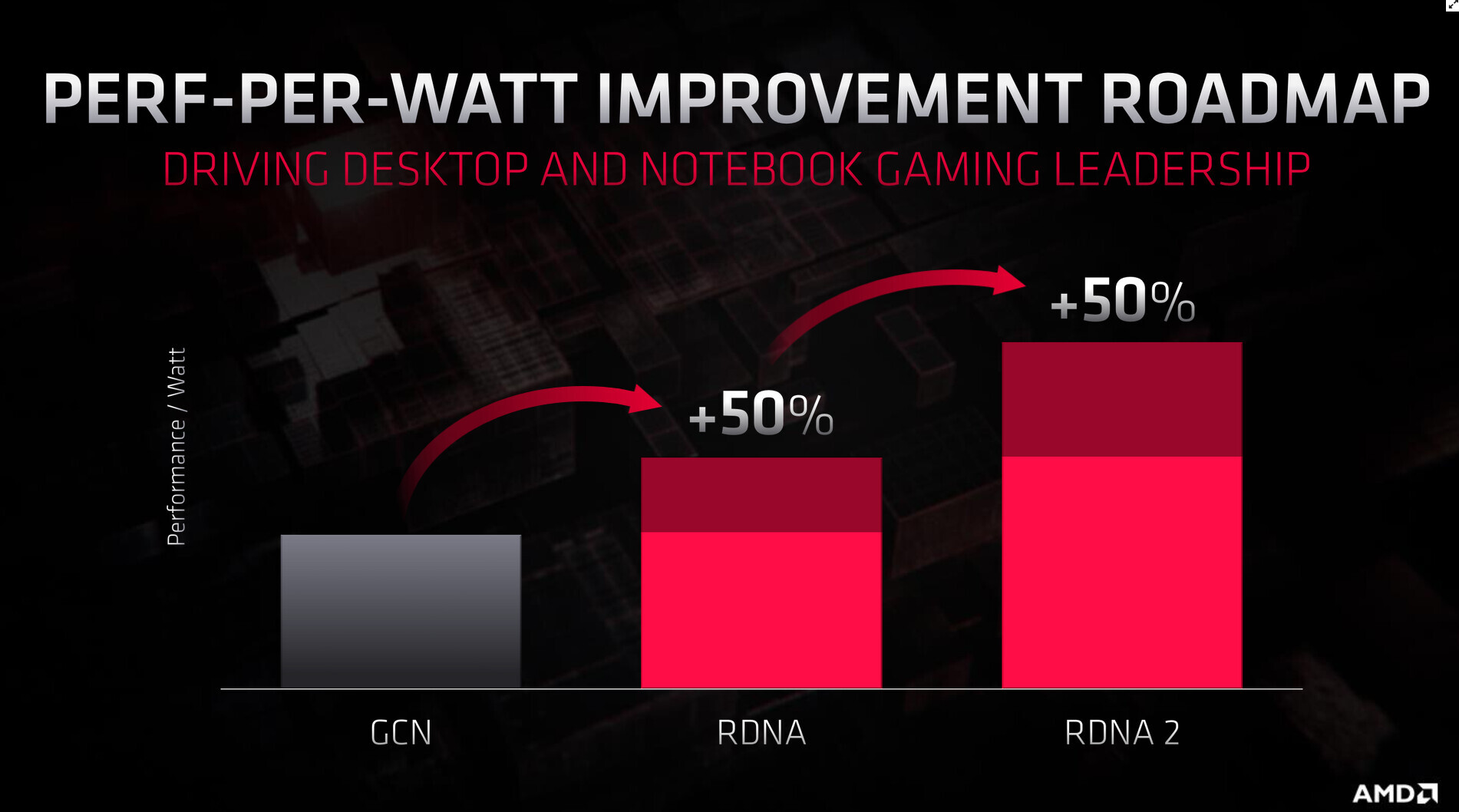
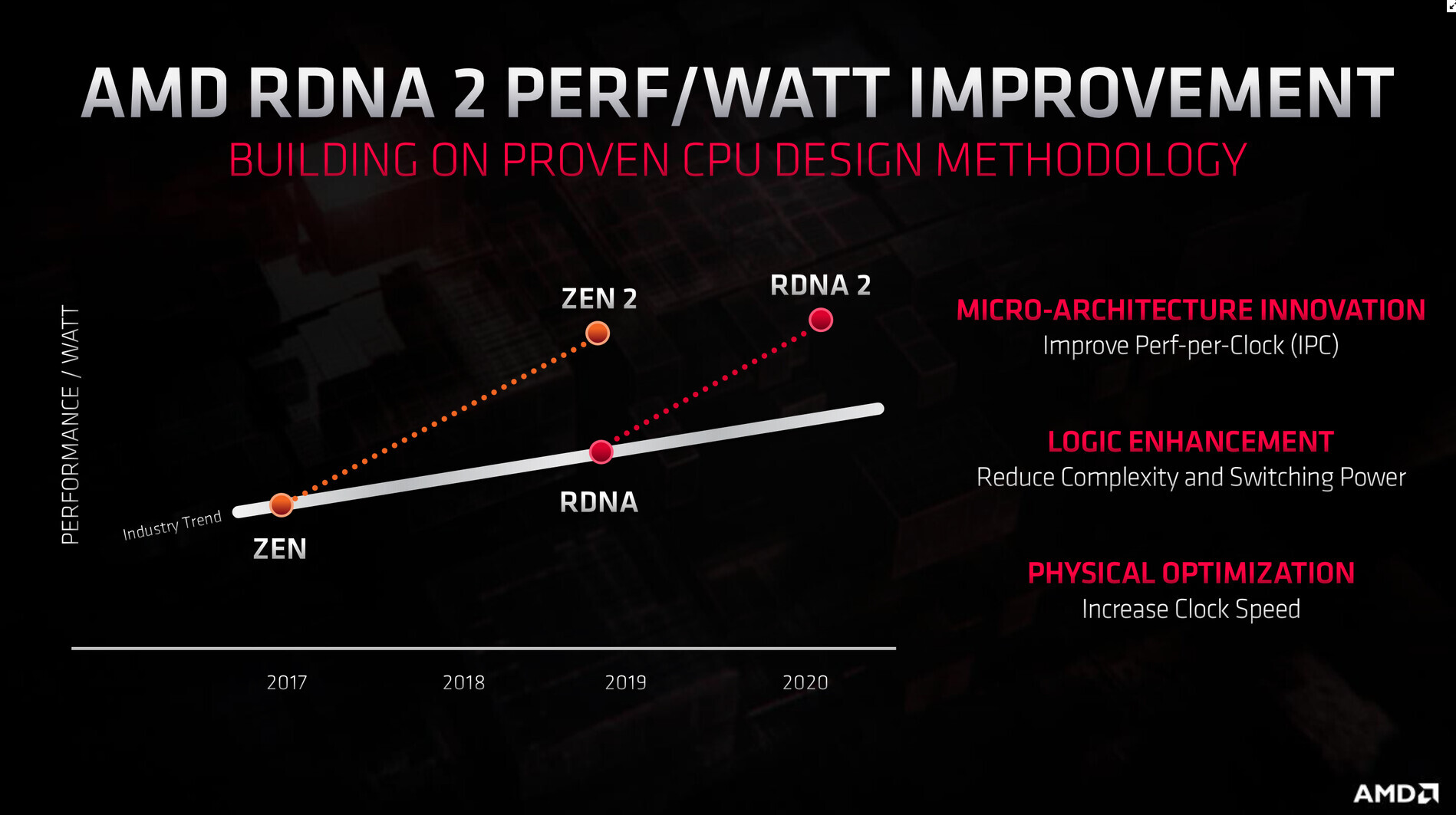
AMD "Navi 31" Rumored to Feature 384-bit GDDR6 Memory Interface
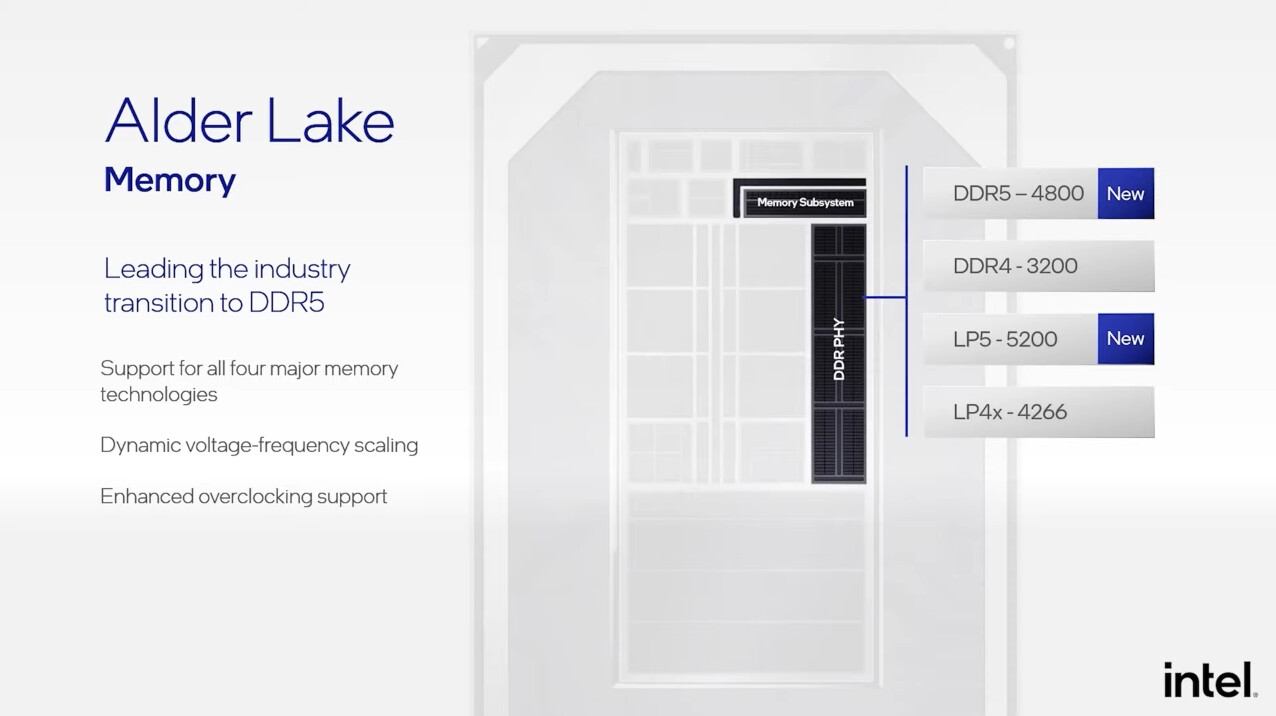
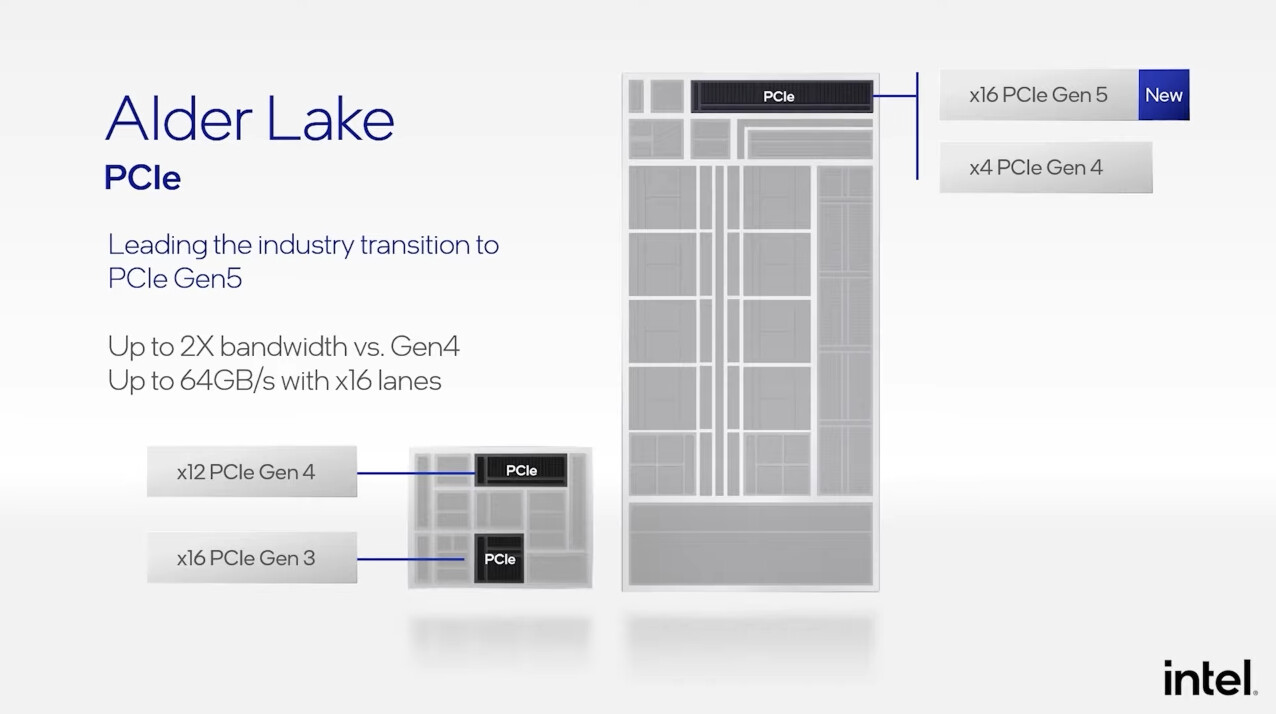
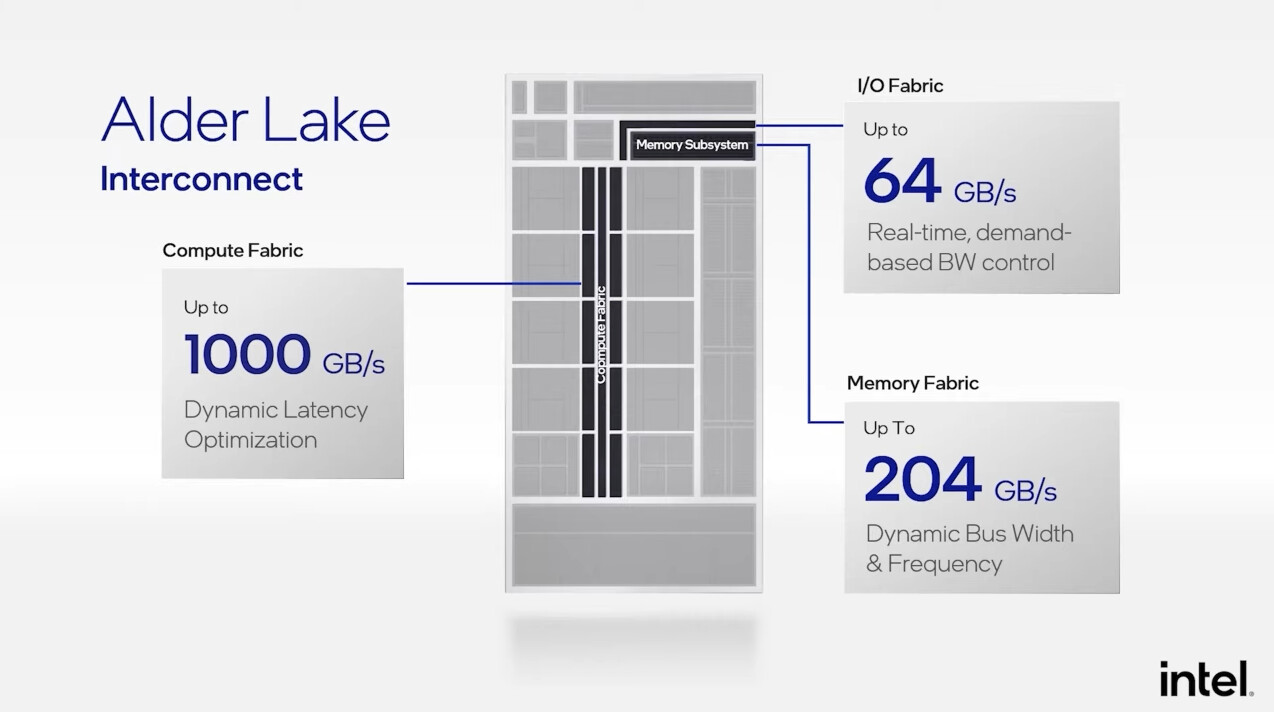
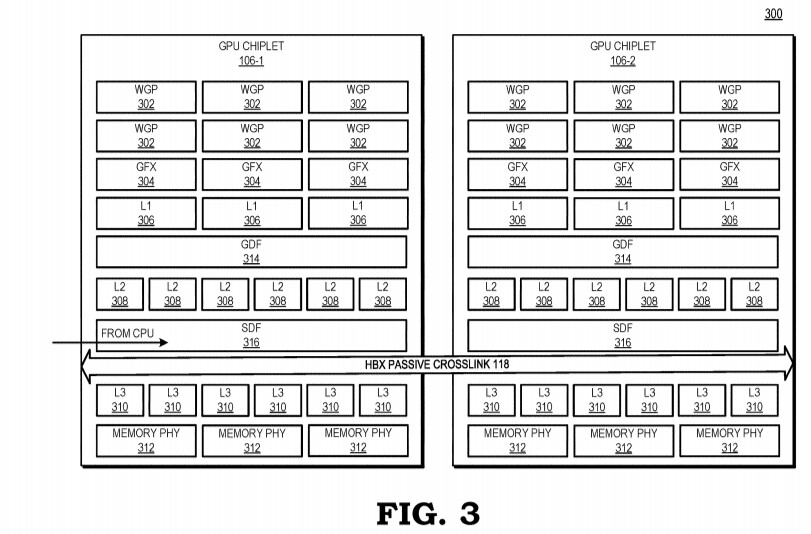
AMD has historically thrown brute memory bus width at solving memory-management problems in its graphics architectures, but the Infinity Cache technology launched with RDNA2 proved to be a game changer, as GPUs with narrow 256-bit memory interfaces could compete with NVIDIA's offerings that have 384-bit wide memory interfaces and faster GDDR6X memory types. It looks like the competition between NVIDIA "Ada" and AMD RDNA3 graphics architectures is about to heat up, as rumors are emerging of AMD giving its biggest next-gen ASIC, the "Navi 31," a 384-bit wide memory interface.
This 50 percent increase in memory bus width, runs in concert with two associated rumors—one, that the company will use faster 20 Gbps GDDR6 memory chips; and two, that AMD may increase the size of the on-die Infinity Cache memory. Samsung is already mass-producing 20 Gbps and 24 Gbps GDDR6 memory chips. These are regular GDDR6 memory chips with JEDEC-standard signaling, and not GDDR6X, an exclusive memory type innovated by NVIDIA and Micron Technology, which leverages PAM4 signaling to increase data-rates. A theoretical "Navi 31" with 20 Gbps GDDR6 memory speeds would enjoy 960 GB/s of memory bandwidth, a massive 87.5 percent bandwidth increase over the RX 6900 XT. The on-die Infinity Cache operates at speeds measured in several TB/s. The increased bus width could also signal an increase in memory sizes, with the RX 6950 XT successor featuring at least 24 GB of memory.
This 50 percent increase in memory bus width, runs in concert with two associated rumors—one, that the company will use faster 20 Gbps GDDR6 memory chips; and two, that AMD may increase the size of the on-die Infinity Cache memory. Samsung is already mass-producing 20 Gbps and 24 Gbps GDDR6 memory chips. These are regular GDDR6 memory chips with JEDEC-standard signaling, and not GDDR6X, an exclusive memory type innovated by NVIDIA and Micron Technology, which leverages PAM4 signaling to increase data-rates. A theoretical "Navi 31" with 20 Gbps GDDR6 memory speeds would enjoy 960 GB/s of memory bandwidth, a massive 87.5 percent bandwidth increase over the RX 6900 XT. The on-die Infinity Cache operates at speeds measured in several TB/s. The increased bus width could also signal an increase in memory sizes, with the RX 6950 XT successor featuring at least 24 GB of memory.