Chinese Tech Firms Reportedly Unimpressed with Overheating of Huawei AI Accelerator Samples
Mid-way through last month, Tencent's President—Martin Lau—confirmed that this company had stockpiled a huge quantity of NVIDIA H20 AI GPUs, prior to new trade restrictions coming into effect. According to earlier reports, China's largest tech firms have collectively spent $16 billion on hardware acquisitions in Q1'25. Team Green engineers are likely engaged in the creation of "nerfed" enterprise-grade chip designs—potentially ready for deployment later on in 2025. Huawei leadership is likely keen to take advantage of this situation, although it will be difficult to compete with the sheer volume of accumulated H20 units. The Shenzhen, Guangdong-based giant's Ascend AI accelerator family is considered to be a valid alternative to equivalent "sanction-conformant" NVIDIA products.
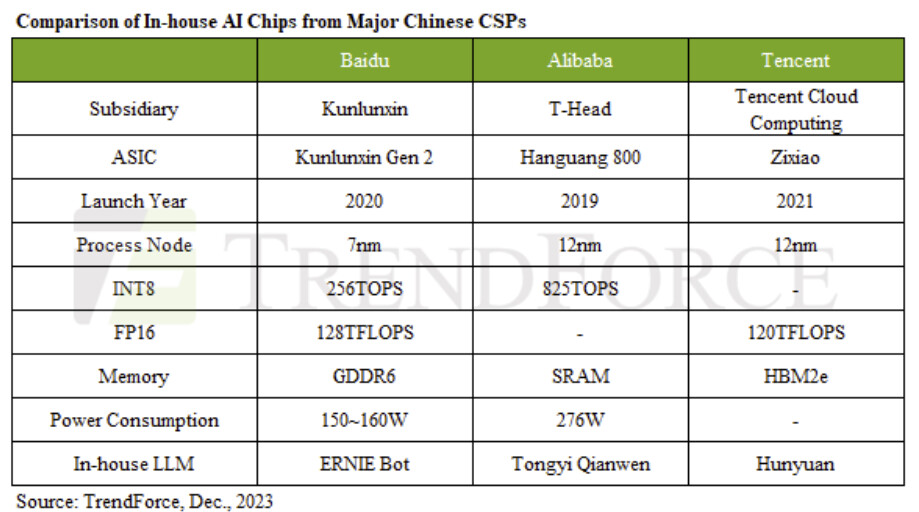
The controversial 910C model and a successor seem to be worthy candidates; as demonstrated by preliminary performance data, but fresh industry murmurs suggest teething problems. The Information has picked up inside track chatter from unnamed moles at ByteDance and Alibaba. During test runs, staffers noted the overheating of Huawei Ascend 910C trial samples. Additionally, they highlighted limitations within the Huawei Compute Architecture for Neural Networks (CANN) software platform. NVIDIA's extremely mature CUDA ecosystem holds a significant advantage here. Several of China's prime AI players—including DeepSeek—are reportedly pursuing in-house AI chip development projects; therefore positioning themselves as competing with Huawei, in a future scenario.


The controversial 910C model and a successor seem to be worthy candidates; as demonstrated by preliminary performance data, but fresh industry murmurs suggest teething problems. The Information has picked up inside track chatter from unnamed moles at ByteDance and Alibaba. During test runs, staffers noted the overheating of Huawei Ascend 910C trial samples. Additionally, they highlighted limitations within the Huawei Compute Architecture for Neural Networks (CANN) software platform. NVIDIA's extremely mature CUDA ecosystem holds a significant advantage here. Several of China's prime AI players—including DeepSeek—are reportedly pursuing in-house AI chip development projects; therefore positioning themselves as competing with Huawei, in a future scenario.