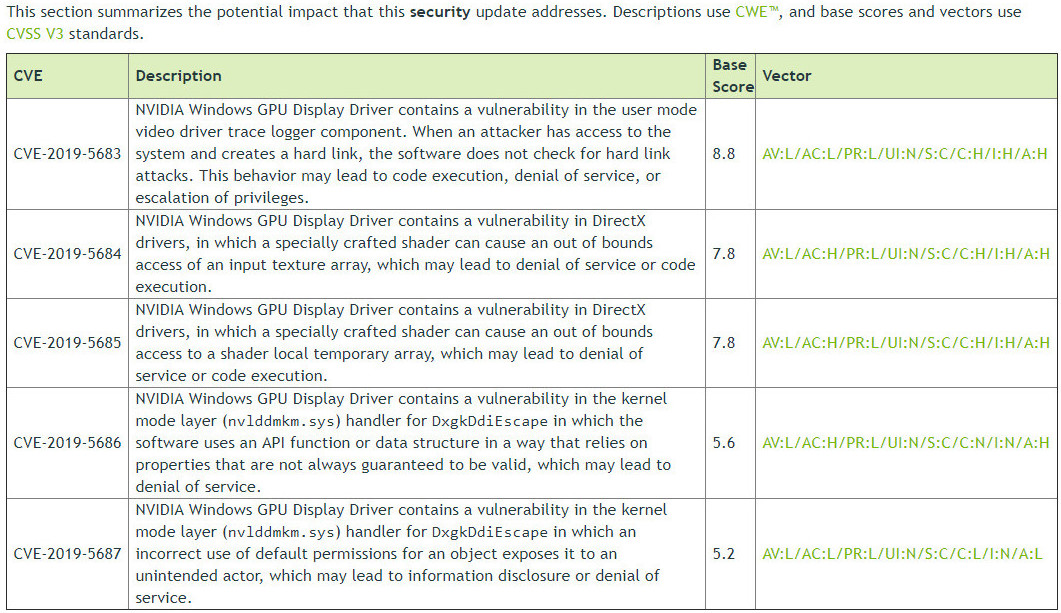
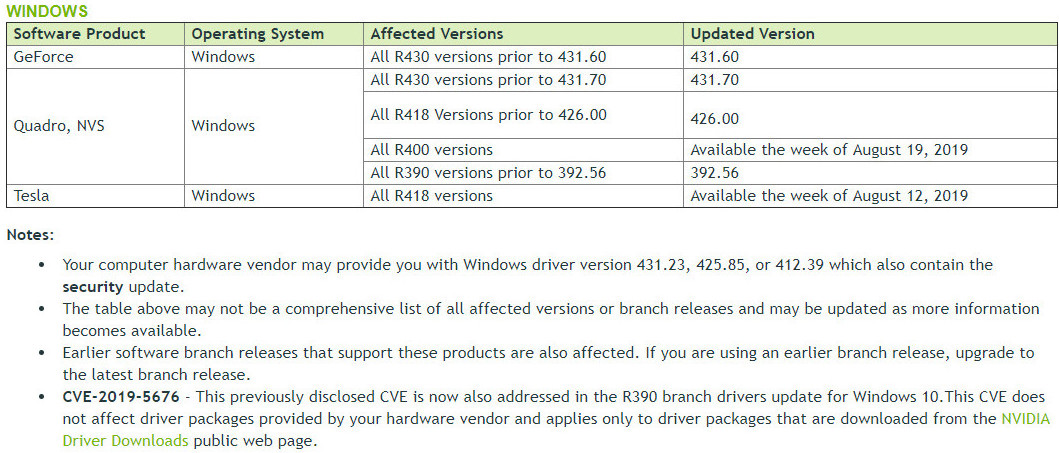
NVIDIA Unveils Tesla V100s Compute Accelerator
NVIDIA updated its compute accelerator product stack with the new Tesla V100s. Available only in the PCIe add-in card (AIC) form-factor for now, the V100s is positioned above the V100 PCIe, and is equipped with faster memory, besides a few silicon-level changes (possibly higher clock-speeds), to facilitate significant increases in throughput. To begin with, the V100s is equipped with 32 GB of HBM2 memory across a 4096-bit memory interface, with higher 553 MHz (1106 MHz effective) memory clock, compared to the 876 MHz memory clock of the V100. This yields a memory bandwidth of roughly 1,134 GB/s compared to 900 GB/s of the V100 PCIe.
NVIDIA did not detail changes to the GPU's core clock-speed, but mentioned the performance throughput numbers on offer: 8.2 TFLOP/s double-precision floating-point performance versus 7 TFLOP/s on the original V100 PCIe; 16.4 TFLOP/s single-precision compared to 14 TFLOP/s on the V100 PCIe; and 130 TFLOP/s deep-learning ops versus 112 TFLOP/s on the V100 PCIe. Company-rated power figures remain unchanged at 250 W typical board power. The company didn't reveal pricing.
NVIDIA did not detail changes to the GPU's core clock-speed, but mentioned the performance throughput numbers on offer: 8.2 TFLOP/s double-precision floating-point performance versus 7 TFLOP/s on the original V100 PCIe; 16.4 TFLOP/s single-precision compared to 14 TFLOP/s on the V100 PCIe; and 130 TFLOP/s deep-learning ops versus 112 TFLOP/s on the V100 PCIe. Company-rated power figures remain unchanged at 250 W typical board power. The company didn't reveal pricing.