Tuesday, March 27th 2018

NVIDIA Announces the DGX-2 System - 16x Tesla V100 GPUs, 30 TB NVMe Memory for $400K
NVIDIA's DGX-2 is likely the reason why NVIDIA seems to be slightly less enamored with the consumer graphics card market as of late. Let's be honest: just look at that price-tag, and imagine the rivers of money NVIDIA is making on each of these systems sold. The data center and deep learning markets have been pouring money into NVIDIA's coffers, and so, the company is focusing its efforts in this space. Case in point: the DGX-2, which sports performance of 1920 TFLOPs (Tensor processing); 480 TFLOPs of FP16; half again that value at 240 TFLOPs for FP32 workloads; and 120 TFLOPs on FP64.
NVIDIA's DGX-2 builds upon the original DGX-1 in all ways thinkable. NVIDIA looks at these as readily-deployed processing powerhouses, which include everything any prospective user that requires gargantuan amounts of processing power can deploy in a single system. And the DGX-2 just runs laps around the DGX-1 (which originally sold for $150K) in all aspects: it features 16x 32GB Tesla V100 GPUs (the DGX-1 featured 8x 16 GB Tesla GPUs); 1.5 TB of system ram (the DGX-1 features a paltry 0.5 TB); 30 TB NVMe system storage (the DGX-1 sported 8 TB of such storage space), and even includes a pair of Xeon Platinum CPUs (admittedly, the lowest performance increase in the whole system).

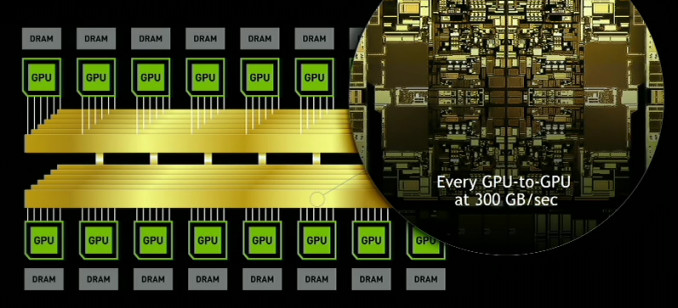
 The DGX-2 has been made possible by NVIDIA's deployment of what it's calling their NVSwitch, which enables 300 GB/s chip-to-chip communication at 12 times the speed of PCIe. Paired with the company's NVLink2, this enables sixteen GPUs to be grouped together in a single system, for a total bandwidth going beyond 14 TB/s. NVIDIA is touting this as a 2 Petaflop-capable system, which isn't that hard to imagine with all of the underlying hardware - it does include 81,920 CUDA cores, and 10,240 Tensor processing cores (which are what NVIDIA uses to achieve that 2 Petaflop figure, if you were wondering. The DGX-2 consumes power that is adequate to its innards - some 10 KW of power in operation, and the whole system weighs 350 pounds.
The DGX-2 has been made possible by NVIDIA's deployment of what it's calling their NVSwitch, which enables 300 GB/s chip-to-chip communication at 12 times the speed of PCIe. Paired with the company's NVLink2, this enables sixteen GPUs to be grouped together in a single system, for a total bandwidth going beyond 14 TB/s. NVIDIA is touting this as a 2 Petaflop-capable system, which isn't that hard to imagine with all of the underlying hardware - it does include 81,920 CUDA cores, and 10,240 Tensor processing cores (which are what NVIDIA uses to achieve that 2 Petaflop figure, if you were wondering. The DGX-2 consumes power that is adequate to its innards - some 10 KW of power in operation, and the whole system weighs 350 pounds.
 Some of NVIDIA's remarks about this system follow:
Some of NVIDIA's remarks about this system follow:
NVSwitch: A Revolutionary Interconnect Fabric
NVSwitch offers 5x higher bandwidth than the best PCIe switch, allowing developers to build systems with more GPUs hyperconnected to each other. It will help developers break through previous system limitations and run much larger datasets. It also opens the door to larger, more complex workloads, including modeling parallel training of neural networks.
NVSwitch extends the innovations made available through NVIDIA NVLink, the first high-speed interconnect technology developed by NVIDIA. NVSwitch allows system designers to build even more advanced systems that can flexibly connect any topology of NVLink-based GPUs.
NVIDIA DGX-2: World's First Two Petaflop System
NVIDIA's new DGX-2 system reached the two petaflop milestone by drawing from a wide range of industry-leading technology advances developed by NVIDIA at all levels of the computing stack.
DGX-2 is the first system to debut NVSwitch, which enables all 16 GPUs in the system to share a unified memory space. Developers now have the deep learning training power to tackle the largest datasets and most complex deep learning models.
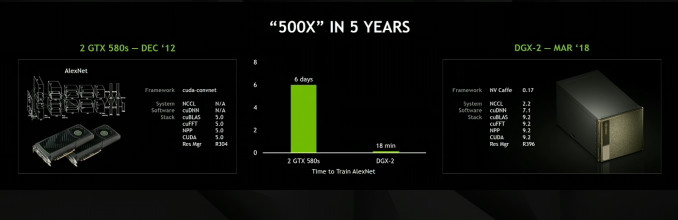
Combined with a fully optimized, updated suite of NVIDIA deep learning software, DGX-2 is purpose-built for data scientists pushing the outer limits of deep learning research and computing. DGX-2 can train FAIRSeq, a state-of-the-art neural machine translation model, in less than two days - a 10x improvement in performance from the DGX-1 with Volta, introduced in September.
Source:
AnandTech
NVIDIA's DGX-2 builds upon the original DGX-1 in all ways thinkable. NVIDIA looks at these as readily-deployed processing powerhouses, which include everything any prospective user that requires gargantuan amounts of processing power can deploy in a single system. And the DGX-2 just runs laps around the DGX-1 (which originally sold for $150K) in all aspects: it features 16x 32GB Tesla V100 GPUs (the DGX-1 featured 8x 16 GB Tesla GPUs); 1.5 TB of system ram (the DGX-1 features a paltry 0.5 TB); 30 TB NVMe system storage (the DGX-1 sported 8 TB of such storage space), and even includes a pair of Xeon Platinum CPUs (admittedly, the lowest performance increase in the whole system).



NVSwitch: A Revolutionary Interconnect Fabric
NVSwitch offers 5x higher bandwidth than the best PCIe switch, allowing developers to build systems with more GPUs hyperconnected to each other. It will help developers break through previous system limitations and run much larger datasets. It also opens the door to larger, more complex workloads, including modeling parallel training of neural networks.
NVSwitch extends the innovations made available through NVIDIA NVLink, the first high-speed interconnect technology developed by NVIDIA. NVSwitch allows system designers to build even more advanced systems that can flexibly connect any topology of NVLink-based GPUs.
NVIDIA DGX-2: World's First Two Petaflop System
NVIDIA's new DGX-2 system reached the two petaflop milestone by drawing from a wide range of industry-leading technology advances developed by NVIDIA at all levels of the computing stack.
DGX-2 is the first system to debut NVSwitch, which enables all 16 GPUs in the system to share a unified memory space. Developers now have the deep learning training power to tackle the largest datasets and most complex deep learning models.
Combined with a fully optimized, updated suite of NVIDIA deep learning software, DGX-2 is purpose-built for data scientists pushing the outer limits of deep learning research and computing. DGX-2 can train FAIRSeq, a state-of-the-art neural machine translation model, in less than two days - a 10x improvement in performance from the DGX-1 with Volta, introduced in September.
28 Comments on NVIDIA Announces the DGX-2 System - 16x Tesla V100 GPUs, 30 TB NVMe Memory for $400K
I belly laughed at this.
500x performance for 400x price, come one come all,this is once in a lifetime opportunity.
Yahoo Finance: Nvidia halts self-driving tests in wake of Uber accident
She was crossing from left to right. walked across a car lane before she got hit on the other car lane.
The car was equipped with 360 lidar with additonal lidar in the front and yet it failed to detect her in order to slow down or avoid.
Something obviously went wrong.
Something obviously went wrong. Come on, be a little less jaded Nvidia Master.
Cost? I will absolutely guarantee you that two full racks or 40 servers with top-end CPU, GPU, and some local storage would cost SIGNIFICANTLY more than 400k. I guarantee it. I couldn't find a single estimation, but AMD compares it original IBM's Roadrunner which cost around $100m, AMD would cost "much less", means at least few millions.
I'm not nVidia fanboi, but numbers don't stack well for AMD here. sorry.
FP16: 480 TFLOPs
FP32: 240 TFLOPs
FP64: 120 TFLOPs
Tensor (Deep Learning): 1.92 PFLOPs
Project 47 GPU Throughput:
FP16: 1.96 PFLOPs
FP32: 984 TFLOPs
you mean this
vs this
Also, nvidia has saturn V with 80 petaflops fp32 and 660 petaflops AI.
Do not live under the false impression that Nvidia has some sort of magic sauce that no one else can conjure up. It's just a lot of dedicated silicon designed for a specific set of tasks. I can guarantee you that in the majority of cases AMD's traditional system is faster and more cost effective while Nvidia's only truly crushes it under very , very specific scenarios. Notice how Jensen talks about this stuff pretty much exclusively within the context of CNNs and that sort of stuff because that's really the only area they've focused on.