Friday, September 1st 2017

On AMD's Raja Koduri RX Vega Tweetstorm
In what is usually described as a tweetstorm, AMD's RTG leader Raja Koduri weighed in on AMD's RX Vega reception and perception from both the public and reviewers. There are some interesting tidbits there; namely, AMD's option of setting the RX vega parts at frequencies and voltages outside the optimal curve for power/performance ratios, in a bid to increase attractiveness towards the performance/$ crowds.
However, it can be said that if AMD had done otherwise, neither gamers nor reviewers would have been impressed with cards that potentially delivered less performance than their NVIDIA counterparts, while consuming more power all the same (even if consuming significantly less wattage). At the rated MSRP (and that's a whole new discussion), this RTG decision was the best one towards increasing attractiveness of RX Vega offerings. However, Raja Koduri does stress Vega's dynamic performance/watt ratios, due to the usage of specially defined power profiles.

 To our forum-walkers: this piece is marked as an editorial
To our forum-walkers: this piece is marked as an editorial
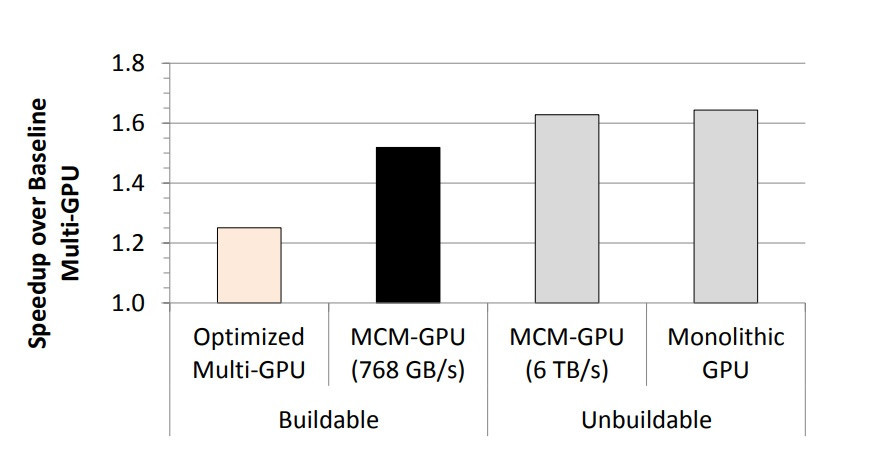
Raja also touched an interesting subject; namely, that "Folks doing perf/mm2 comparisons need to account for Vega10 features competing with 3 different competitive SOCs (GP100, GP102 and GP104)". This is interesting, and one of the points we have stressed here on TPU: AMD's Vega architecture makes great strides towards being the architecture AMD needs for its server/AI/computing needs, but it's a far cry from what AMD gamers deserve. it's always a thin line to be threaded by chip designers on which features and workloads to implement/improve upon with new architectures. AMD, due to its lack of a high-performance graphics chip, was in dire need of a solution that addressed both the high-performance gaming market and the server/computing market where the highest profits are to be made. This round, the company decided to focus its developments more towards the server side of the equation - as Raja Koduri himself puts it relative to Infinity Fabric: "Infinity fabric on Vega is optimized for server. It's a very scalable fabric and you will see consumer optimized versions of it in future." Likely, this is Raja's way of telling us to expect MCMs (Multi-Chip-Modules) supported by AMD's Infinity Fabric, much as we see with Ryzen. This design philosophy allows companies to design smaller, more scalable and cheaper chips, which are more resistant to yield issues, and effectively improve every metric, from performance, to power and yield, compared to a monolithic design. NVIDIA themselves have said that MCM chip design is the future, and this little tidbit by Raja could be a pointer towards AMD Radeon's future in that department.
This round, the company decided to focus its developments more towards the server side of the equation - as Raja Koduri himself puts it relative to Infinity Fabric: "Infinity fabric on Vega is optimized for server. It's a very scalable fabric and you will see consumer optimized versions of it in future." Likely, this is Raja's way of telling us to expect MCMs (Multi-Chip-Modules) supported by AMD's Infinity Fabric, much as we see with Ryzen. This design philosophy allows companies to design smaller, more scalable and cheaper chips, which are more resistant to yield issues, and effectively improve every metric, from performance, to power and yield, compared to a monolithic design. NVIDIA themselves have said that MCM chip design is the future, and this little tidbit by Raja could be a pointer towards AMD Radeon's future in that department.


 That Infinity Fabric is optimized for servers is a reflection of the entire Vega architecture; AMD's RX Vega may be gaming-oriented graphics cards, but most of the architecture improvements aren't capable of being tapped by already-existent gaming workloads. AMD tooled its architecture for a professional/computing push, in a bid to fight NVIDIA's ever-increasing entrenchment in that market segment, and it shows on the architecture. Does this equate to disappointing (current) gaming performance? It does. And it equates to especially disappointing price/performance ratios with the current supply/pricing situation, which the company still hasn't clearly and forcefully defined. Not that they can, anyway - it's not like AMD can point the finger towards the distributors and retailers that carry their products with no repercussion, now can they?
That Infinity Fabric is optimized for servers is a reflection of the entire Vega architecture; AMD's RX Vega may be gaming-oriented graphics cards, but most of the architecture improvements aren't capable of being tapped by already-existent gaming workloads. AMD tooled its architecture for a professional/computing push, in a bid to fight NVIDIA's ever-increasing entrenchment in that market segment, and it shows on the architecture. Does this equate to disappointing (current) gaming performance? It does. And it equates to especially disappointing price/performance ratios with the current supply/pricing situation, which the company still hasn't clearly and forcefully defined. Not that they can, anyway - it's not like AMD can point the finger towards the distributors and retailers that carry their products with no repercussion, now can they?


 Raja Koduri also addressed the current mining/gamer arguments, but in a slightly deflective way: in truth, every sale counts as a sale for the company in terms of profit (and/or loss, since rumors abound that AMD is losing up to $100 with every RX Vega graphics card that is being sold at MSRP). An argument can be made that AMD's retreating market share on the PC graphics card market would be a never-ending cycle of lesser developer attention towards architectures that aren't that prominent in their user bases; however, I think that AMD considers they're relatively insulated from that particular issue due to the fact that the company's graphics solutions are embedded into the PS4, PS4 Pro, Xbox One S consoles, as well as the upcoming Xbox One X. Developers code for AMD hardware from the beginning in most games; AMD can certainly put some faith in that as being a factor to tide their GPU performance over until they have the time to properly refine an architecture that shines at both computing and gaming environments. Perhaps when we see AMD's Navi, bolstered by AMD's increased R&D budget due to a (hopefully) successful wager in the professional and computing markets, will we see an AMD that can bring the competition to NVIDIA as well as they have done for Intel.
Raja Koduri also addressed the current mining/gamer arguments, but in a slightly deflective way: in truth, every sale counts as a sale for the company in terms of profit (and/or loss, since rumors abound that AMD is losing up to $100 with every RX Vega graphics card that is being sold at MSRP). An argument can be made that AMD's retreating market share on the PC graphics card market would be a never-ending cycle of lesser developer attention towards architectures that aren't that prominent in their user bases; however, I think that AMD considers they're relatively insulated from that particular issue due to the fact that the company's graphics solutions are embedded into the PS4, PS4 Pro, Xbox One S consoles, as well as the upcoming Xbox One X. Developers code for AMD hardware from the beginning in most games; AMD can certainly put some faith in that as being a factor to tide their GPU performance over until they have the time to properly refine an architecture that shines at both computing and gaming environments. Perhaps when we see AMD's Navi, bolstered by AMD's increased R&D budget due to a (hopefully) successful wager in the professional and computing markets, will we see an AMD that can bring the competition to NVIDIA as well as they have done for Intel.
Sources:
Raja Koduri's Twitter, via ETeknix
However, it can be said that if AMD had done otherwise, neither gamers nor reviewers would have been impressed with cards that potentially delivered less performance than their NVIDIA counterparts, while consuming more power all the same (even if consuming significantly less wattage). At the rated MSRP (and that's a whole new discussion), this RTG decision was the best one towards increasing attractiveness of RX Vega offerings. However, Raja Koduri does stress Vega's dynamic performance/watt ratios, due to the usage of specially defined power profiles.



Raja also touched an interesting subject; namely, that "Folks doing perf/mm2 comparisons need to account for Vega10 features competing with 3 different competitive SOCs (GP100, GP102 and GP104)". This is interesting, and one of the points we have stressed here on TPU: AMD's Vega architecture makes great strides towards being the architecture AMD needs for its server/AI/computing needs, but it's a far cry from what AMD gamers deserve. it's always a thin line to be threaded by chip designers on which features and workloads to implement/improve upon with new architectures. AMD, due to its lack of a high-performance graphics chip, was in dire need of a solution that addressed both the high-performance gaming market and the server/computing market where the highest profits are to be made.







131 Comments on On AMD's Raja Koduri RX Vega Tweetstorm
At the end of the day is Vega hot? Yes. Is it competing with its target (1070/1080)? Yes. Despite all the issues/controversy surrounding Vega is it selling? Yes.
Is Ryzen selling? Yes.
It's a consumers market, we determine a products outcome. People flocked for the original titan @$1000 guess what Nvidia did? Increase the new one to $1200. Did ppl still buy it? Yup.
Not that it makes it much better, but the 7900x is $999, not $1700 ;)
(Analogy: theoretically Ryzen has ~50% higher "IPC" than Skylake, but in real life Skylake IPC is much higher)
Don't burst his imagination bubble goat!
For the average joe, the P4 with an higher clock had to be better, architecture optimization isn't something they are aware of. They also don't care/know about the fact that AMD was first on 64bit.
Intel also got a nice little eco-system going on :
Thunderbolt being intel locked means that apple won't go full AMD ever, and also means giving up on that on any ryzen based laptop, so no egpu with a Ryzen system.
As for nvidia, they got an habit of selling the fastest thing on earth wich do a lot for brand fidelity, and brand equity (geforce 256, GTX 8800, Titan) and when they are launching new "toys" they are doing it right:
- 3D vision was better, easier to set up, 3D with AMD was a mess.
- Phys-x may be a gimmick, but it's still a little extra nice to have,and with all the succesfull batman games having it, it was another reason to get an Nvidia card.
- G-sync was first and heavily marketed, freesync came later and have poor marketing,
- CUDA is easier to work with, the developpers get better support for every platform, meanwhile open cl can be really troublesome, some of the devellopers working on opencl cycle renderer for mac osx gave up out of disgust, because they couldn't get any support to fix an issue, open cl on mac osx is broken, and even tho apple was the creator of open cl they didn't care.
The fine wine argument isn't something marketable, and if they ditch GCN it may not be true anymore. When the GTX 980/ti were launched, it was a fact that they were the fastest gpu, that's how you are selling product to people, you don't say: in 2 years our product will go toes to toes with the old fastest gpu in the market.AMD may have been the first to give HBM to the consummers, the fact that it wasn't the fastest thing on earth failed to impress part of the consummers. People in general are not reasonable, fully rational buyers, they like dreams, and buying something from the company selling the fastest gpu or the makers of the 1st cpu sounds better than buying the stuff from the budget company. Being seen as a premium brand does a lot, even if the client doesn't buy the high end product, they still feel like they are a part of it.
It wasn't long ago that i had to show some benchmark to a guy who was making a meh face when i mentionned that the new AMD cpu were good product. People don't know that AMD is back in the game, and all the high end laptop still rocking an Intel cpu/ Nvidia gpu won't help.
I guess you are wondering, for example, where is the branch predictor in nvidia arch ... there isn't one, warp is executing both parts of conditional statement (first "if" block and "else" block after) and portion of cuda cores sleep through the "if" part and other portion sleep through the "else" part. Brute forcing branching in shader code like this seems inefficient and a weakness but it's a trade off for simple and robust parallel design that saves die space and wins efficiency in total.
Actually that's exactly what you want in general with a GPU where you need to keep the core fed. The fact that Vega wins a lot more from memory bandwidth suggests there is nothing wrong with the way instructions are handled. Which isn't surprising at all , one of the biggest bottlenecks inside any of these GPUs was and still is memory bandwidth/latency. AMD should have kept the 4096-bit memory bus.Lack of branch prediction means more burden on compilers/drivers and more CPU overhead in general at run-time. And I would say that's not robust at all , in fact it's the reason why until Pascal they have been struggling with async. When they said Maxwell can do async but it just needs enabling , they were BSing. What they meant is that they can only do that through the help of the driver but that would have ended up being ridiculously inefficient and would have hurt performance most likely and that's why we never saw "a magic async enabling driver".
Nvidia offloaded a lot of the control logic on the driver side of things , meanwhile AMD relies almost entirely on the silicon itself to properly dispatch work. That should have been an advantage if anything for AMD , however Nvidia struck gold when they managed to support multi threaded draw calls automatically through their drivers with DX11 and AMD for some reason couldn't.
And this is why DX12/Vulkan was supposed to help AMD since now draw calls are handled exclusively by the programmer and Nvidia's drivers can't do jack now. But all we got were lousy implementations since it requires a lot of work. In fact it can hurt performance because even the few DX11 optimizations AMD had going are being nullified , see Rise of the Tomb Raider.
In the end my point is that the design language AMD uses for it's architecture is perfectly fine , it's just that they have to deal with an antiquated software landscape that isn't on the same page with them.
Memory bandwidth is not holding Vega back, it has the same bandwidth as GTX 1080 Ti. The problem is the GPU's scheduler and a longer pipeline.Nonesene.
Execution of shader code and low level scheduling is done in the GPU, not the CPU. Conditionals in the shader code doesn't stress the compiler or the driver. Start by learning the basics first.Nonsense.
The drivers translate a queue of API calls into native operations, the GPU schedules clusters, analyzes dependencies, etc. in real time.Nonsense.
If you knew anything about graphics programming, you'd know the programmer has always controlled the draw calls.
Hmm... www.tomshardware.com/reviews/nvidia-cuda-gpu,1954-7.html
If I'm following this correctly. AMD has compute unit flexibility where CUDA only has flexibility on the warp level (64-512 threads). If CUDA is told to execute just a single SIMD operation on behalf of CUDA, 98.4-99.8% of the block will result in idle hardware. I suspect GCN is the opposite: the ACE will reserve a single compute unit to deal with that task while the rest of the GPU continues with other work.
The design philosophy is fundamentally opposite: GCN is about GPGPU where CUDA is about GPU with the ability to switch context to GPGPU. GCN demands saturation (like a CPU) where CUDA demands strict control (like a GPU).
Which is better going forward? Which should computers 10 years from now have? I think GCN because DirectPhysics is coming. We're finally going to have a reason to get serious about physics as a gameplay mechanic and NVIDIA can't get serious because of the massive penalty in framerate CUDA incurs when context switching. It makes far more sense for physics to occupy idle compute resources than disrupting the render wave front. CUDA, as it is designed now, will hold engines back from using physics as they should.
So basically it takes several of them to do a job of single SIMD unit in GCN ... this is what I meant by finer granularitySingle SIMD operation still has multiple data, so it would saturate much more than that ... what you are describing is using SIMD as SISD (having data array consist of only 1 element), and in that context, yes, GCN would handle it more gracefully.
Nvidia's model is actually SIMT and its efficiency depends on having enough concurrent warps - even when those warps are not saturating SM enough by themselves, if there is enough of them for scheduler to choose from, all is well (good read yosefk.com/blog/simd-simt-smt-parallelism-in-nvidia-gpus.html)Ditto. Nvidia kinda expects copious amount of SIMD/SIMT parallelism in their workload, because they are making GPUs.
With GPGPU it's always the question "How much general purpose you want it to be?"Yeah well, physics solvers are extremely dynamic in their load ... one frame nothing is happening, the next frame one collision sets hundreds of objects in motion. If you simply must update all positions by the end of the frame, and you do, async is the way to go. I guess that's why cuda physx is exclusively of a simd/simt kind (huge number of elements behaving by the same algorithm - fluid, hair, grass). Too bad we don't have some alpha version previewed somewhere by now since async compute is a thing.
It's going to take GPGPU to make physics mean something in games. Specifically, they need to prioritize the compute tasks and balance the GPU work with it. PhysX was always built off the foundation of having a separate card handling it. DirectPhysics can't do that.
Edit: trademarks.justia.com/871/86/directphysics-87186880.html