Tuesday, November 6th 2018

AMD Unveils "Zen 2" CPU Architecture and 7 nm Vega Radeon Instinct MI60 at New Horizon
AMD today held its "New Horizon" event for investors, offering guidance and "color" on what the company's near-future could look like. At the event, the company formally launched its Radeon Instinct MI60 GPU-based compute accelerator; and disclosed a few interesting tidbits on its next-generation "Zen 2" mircroarchitecture. The Instinct MI60 is the world's first GPU built on the 7 nanometer silicon fabrication process, and among the first commercially available products built on 7 nm. "Rome" is on track to becoming the first 7 nm processor, and is based on the Zen 2 architecture.
The Radeon Instinct MI60 is based on a 7 nm rendition of the "Vega" architecture. It is not an optical shrink of "Vega 10," and could have more number-crunching machinery, and an HBM2 memory interface that's twice as wide that can hold double the memory. It also features on-die logic that gives it hardware virtualization, which could be a boon for cloud-computing providers.



 If you've been paying attention to our "Zen 2" coverage over the past couple of weeks, you would've read our recent article citing a Singapore-based VLSI engineer claiming that AMD could disintegrate the northbridge for its high core-count enterprise CPUs, in an attempt to make the memory I/O "truly" wide, without compromising on the idea of MCM CPU chiplets. All of that is true.
If you've been paying attention to our "Zen 2" coverage over the past couple of weeks, you would've read our recent article citing a Singapore-based VLSI engineer claiming that AMD could disintegrate the northbridge for its high core-count enterprise CPUs, in an attempt to make the memory I/O "truly" wide, without compromising on the idea of MCM CPU chiplets. All of that is true.
"Rome" is codename for a multi-chip module of four to eight 7 nm CPU dies, wired to a centralized die over InfinityFabric. This 14 nm die, called "I/O die," handles memory and PCIe, providing a monolithic 8-channel memory interface, overcoming the memory bandwidth bottlenecks of current-generation 4-die MCMs. The CPU dies and an I/O die probably share an interposer. Assuming each die has 8 CPU cores, "Rome" could have up to 64 cores, an 8-channel DDR4 memory interface, and a 96-lane PCI-Express gen 4.0 root-complex, per socket. If AMD has increased its core-count per CPU die, Rome's core count could be even higher. The broader memory I/O, assuming InfinityFabric does its job, could significantly improve performance of multi-threaded workloads that can scale across as many cores as you can throw at them, utilizing a truly broader memory interface. AMD also speaks of "increased IPC," which bodes well for the client-segment. AMD has managed to increase IPC (per-core performance), with several on-die enhancements to the core design.
The broader memory I/O, assuming InfinityFabric does its job, could significantly improve performance of multi-threaded workloads that can scale across as many cores as you can throw at them, utilizing a truly broader memory interface. AMD also speaks of "increased IPC," which bodes well for the client-segment. AMD has managed to increase IPC (per-core performance), with several on-die enhancements to the core design.
With "Zen" and "Zen+," AMD recognized several components on the core that could be broadened or made faster, which could bring about tangible IPC improvements. This includes a significantly redesigned front-end. Zen/Zen+ feature a front-end that's not much different than AMD's past micro-architectures. The new front-end includes an improved branch-predictor, a faster instruction prefetcher, an improved/enlarged L1 instruction cache, and an improved prefetcher cache (L2).
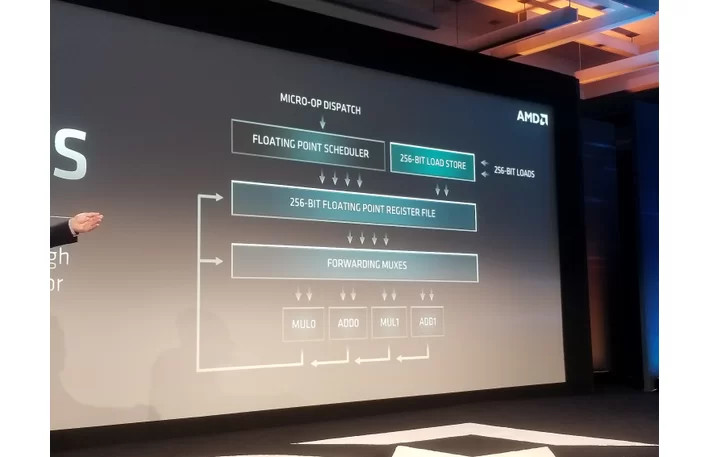
The number-crunching machinery, the floating point unit, also receives a massive overhaul. "Zen 2" features 256-bit FPUs, which are doubled in width compared to Zen. load/store/dispatch/retire bandwidths have been doubled over the current generation. These changes are massive. Given that even without these core-level changes, by simply improving cache latencies, AMD managed to eke out a ~3% IPC uplift with "Zen+," one can expect double-digit percentage IPC gains with "Zen 2." Higher IPC, combined with possible increased core counts, higher clock speeds, and power benefits of switching to 7 nm, complete AMD's "Zen 2" proposition.
Source:
Tom's Hardware
The Radeon Instinct MI60 is based on a 7 nm rendition of the "Vega" architecture. It is not an optical shrink of "Vega 10," and could have more number-crunching machinery, and an HBM2 memory interface that's twice as wide that can hold double the memory. It also features on-die logic that gives it hardware virtualization, which could be a boon for cloud-computing providers.




"Rome" is codename for a multi-chip module of four to eight 7 nm CPU dies, wired to a centralized die over InfinityFabric. This 14 nm die, called "I/O die," handles memory and PCIe, providing a monolithic 8-channel memory interface, overcoming the memory bandwidth bottlenecks of current-generation 4-die MCMs. The CPU dies and an I/O die probably share an interposer. Assuming each die has 8 CPU cores, "Rome" could have up to 64 cores, an 8-channel DDR4 memory interface, and a 96-lane PCI-Express gen 4.0 root-complex, per socket. If AMD has increased its core-count per CPU die, Rome's core count could be even higher.

With "Zen" and "Zen+," AMD recognized several components on the core that could be broadened or made faster, which could bring about tangible IPC improvements. This includes a significantly redesigned front-end. Zen/Zen+ feature a front-end that's not much different than AMD's past micro-architectures. The new front-end includes an improved branch-predictor, a faster instruction prefetcher, an improved/enlarged L1 instruction cache, and an improved prefetcher cache (L2).
The number-crunching machinery, the floating point unit, also receives a massive overhaul. "Zen 2" features 256-bit FPUs, which are doubled in width compared to Zen. load/store/dispatch/retire bandwidths have been doubled over the current generation. These changes are massive. Given that even without these core-level changes, by simply improving cache latencies, AMD managed to eke out a ~3% IPC uplift with "Zen+," one can expect double-digit percentage IPC gains with "Zen 2." Higher IPC, combined with possible increased core counts, higher clock speeds, and power benefits of switching to 7 nm, complete AMD's "Zen 2" proposition.
57 Comments on AMD Unveils "Zen 2" CPU Architecture and 7 nm Vega Radeon Instinct MI60 at New Horizon
I may finally buy a CPU day 1.
Regarding Vega: Meh, I guess, since it's not aimed at consumers. Although it's probably a lot more interesting for those that work in HPC, datacenters, cloud computing and the like.
They also said 2x core density and a lot of confimations on leaks which wasn't said outright but confirm our leaks..
IPC is an unknown but I expect Intel levels of IPC and I doubt Intel have left any ipc on the table so I think we're close to the max possible IPC as both enter the same realm after decades of optimizations.
But thankfully memory always give IPC and that'll be on Zen3 (DDR5).
Also we do not know what the I/O chip will be in the different classes, Epyc, TR, Desktop\laptop.
Furthermore clocks, but if IPC and 4.5 ghz i think we have a pretty good cpu in the future :) (1.25x performance = frequency = 4.5 allcore possibility ~)
The chiplet arrangement seems odd but i'm no expert on the matter.
The good thing is that the NUMA thing seeems to be gone, meaning in TR CPUs and Epyc CPUs will have the whole chip running certain things that required "legacy mode", or whatever it's called, will no longer need it. I'm assuming the bigger AM4 platform Zen 2 version (in cores) will also not require NUMA, which is quite good, i think.
No more excuses for not building a Ryzen system next year, lower price with close to/same/or possibly above IPC of Intel chips means there's hardly anything to sacrifice for red team. Of course, always wait for reviews kids ;-) !
So a single PCB & 9 chiplets spread out, I wonder how they're connected without the interposer :confused:
Intel is a victim of their own increased frequencies: with the higher and higher base / boost frequencies for the current manufacturing processes, they either come up with a significant boost in IPC and reduce the clocks or improve the clocks and keep (or slightly improve) the IPC and they assumed they could do the former with 10nm but that backfired spectacularly and they are being forced to use an even more refined version of the same process and that means pretty much the same IPC, meaning they need higher clocks on these than the previous gen, which in turn aggravates the issue with frequencies / IPC for the next gen.
AMD must be careful not to fall for the same "frequency trap" or they risk getting caught in it. I'd prefer CPUs with lower frequencies but higher IPC than CPU with high frequencies but lower IPC, so long as the performance ends up being roughly the same, ofc.
I said it for years interposers appeared with sockets as an abstraction layer to connect the beol to a socket and as such has Always been a multi leyer(phones tut it got it right seconds before) circuited PCB not just a interlink.
Am4 could be one of the best sockets ever made and shows intel why people like me aren't spending cash with them.
So the chiplets were true, now let's wait the reviews.
Will these Rome be compatibles with the same motherboards as current EPYC?
EDIT: Yeah, maybe that's too hopeful...
Edit: I also don't see anything about Zen2 availability in the server space, so good luck with that "Q1 or Q2 2019" prediction.
Mainstream stuff will be discussed at CES keynote at the beginning of January next year. Judging by the data we have now it looks like we might get 16c/32t mainstream part on AM4. That is two chiplets and a controller chip between them. Coupled with improved IPC and clockspeeds things looks pretty good imo.