Thursday, March 21st 2019

Intel Gen11 Architecture and GT2 "Ice Lake" iGPU Detailed
Intel "Ice Lake" will be the company's first major processor microarchitecture since the "Skylake" (2015), which promises CPU IPC improvements. Intel has been reusing both CPU cores and graphics architecture for four processor generations, since "Skylake". Gen9 got a mid-life update to Gen9.5 with "Kaby Lake", adding new display interfaces and faster drivers. "Ice Lake" takes advantage of the new 10 nm silicon fabrication process to not just pack faster CPU cores (with increased IPC), but also the new Gen11 iGPU. Intel published a whitepaper detailing this architecture.
An illustration in the whitepaper points to the GT2 trim of Gen11. GT2 tends to be the most common variant of each Intel graphics architecture. Gen9.5 GT2, for example, is deployed across the board on 8th and 9th generation Core processors (with the exception of the "F" or "KF" SKUs). The illustration confirms that Intel will continue to use their Ring Bus interconnect on the mainstream implementation of "Ice Lake" processors, despite possible increases in CPU core counts. This is slightly surprising, since Intel introduced a Mesh interconnect with its recent HEDT and enterprise processors. Intel has, however, ensured the iGPU has a preferential access to the Ring Bus, with 64 Byte/clock reads and 64 Byte/clock writes, while each CPU core only has 32 Byte/clock reads and 32 Byte/clock writes.
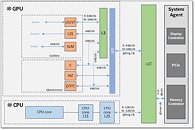


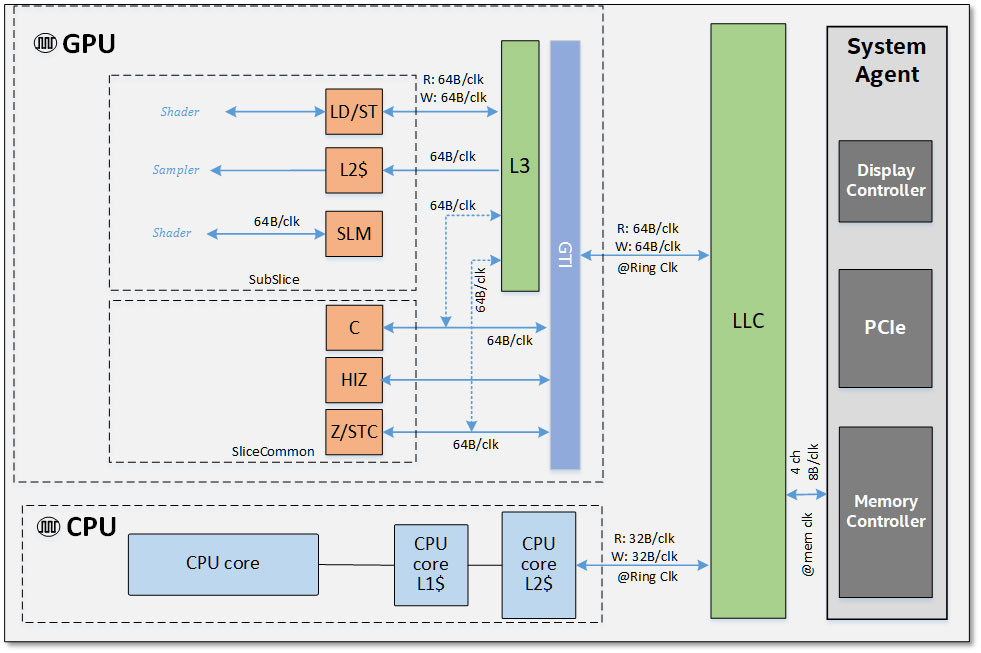
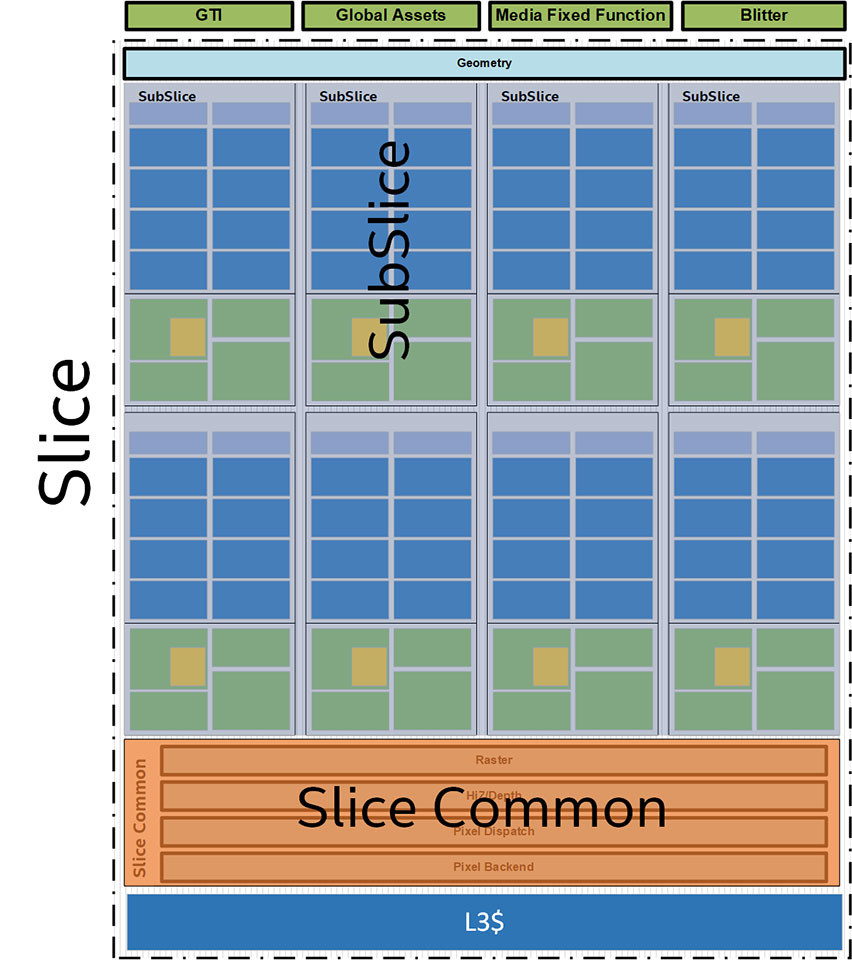
 While the CPU core ring-stop terminates at its dedicated L2 cache, for the iGPU, it does so at a component called "GTI", short for graphics technology interface. The GTI interfaces with two components: Slice Common and a L3 cache which is completely separate from the processor's main L3 cache. The iGPU now has a dedicated 3 MB L3 cache, although the processor's main L3 cache outside the iGPU is still town-square for the entire processor. The iGPU's L3 cache cushions transfers between the GTI and Subslices. These are the indivisible number-crunching clusters of the GPU, much like streaming multiprocessors on an NVIDIA GPU - this is where the shaders are located. In addition to the subslices we find separate geometry processing hardware, and front-ends, including fixed-function hardware to accelerate media, which all feed into the eight subslices. The back-end is handled by "Slice Common", which includes ROPs, which write to the iGPU's own L3 cache.
While the CPU core ring-stop terminates at its dedicated L2 cache, for the iGPU, it does so at a component called "GTI", short for graphics technology interface. The GTI interfaces with two components: Slice Common and a L3 cache which is completely separate from the processor's main L3 cache. The iGPU now has a dedicated 3 MB L3 cache, although the processor's main L3 cache outside the iGPU is still town-square for the entire processor. The iGPU's L3 cache cushions transfers between the GTI and Subslices. These are the indivisible number-crunching clusters of the GPU, much like streaming multiprocessors on an NVIDIA GPU - this is where the shaders are located. In addition to the subslices we find separate geometry processing hardware, and front-ends, including fixed-function hardware to accelerate media, which all feed into the eight subslices. The back-end is handled by "Slice Common", which includes ROPs, which write to the iGPU's own L3 cache.
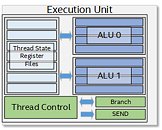
Each Subslice begins with an instruction cache and thread dispatch that divides the number-crunching workload between eight execution units or EUs. Gen11 GT2 has 64 EUs, which is a 166% growth over the 24 EUs that we saw with Gen9.5 GT2 (for example on Core i9-9900K). Such a significant increase in EUs will probably double performance, to make up lost ground against AMD's Ryzen APUs. Each EU packs two ALUs with four execution pipelines each, register files, and a thread control unit. Certain other components are shared between the EUs, such as media samplers. Intel is updating the media engine of its integrated graphics to support hardware acceleration of more video formats, including 10-bpc VP9. The display controller now supports Panel Self Refresh, Display Context Save and Restore, VESA Adaptive-Sync, and support for USB-C based outputs.
An illustration in the whitepaper points to the GT2 trim of Gen11. GT2 tends to be the most common variant of each Intel graphics architecture. Gen9.5 GT2, for example, is deployed across the board on 8th and 9th generation Core processors (with the exception of the "F" or "KF" SKUs). The illustration confirms that Intel will continue to use their Ring Bus interconnect on the mainstream implementation of "Ice Lake" processors, despite possible increases in CPU core counts. This is slightly surprising, since Intel introduced a Mesh interconnect with its recent HEDT and enterprise processors. Intel has, however, ensured the iGPU has a preferential access to the Ring Bus, with 64 Byte/clock reads and 64 Byte/clock writes, while each CPU core only has 32 Byte/clock reads and 32 Byte/clock writes.

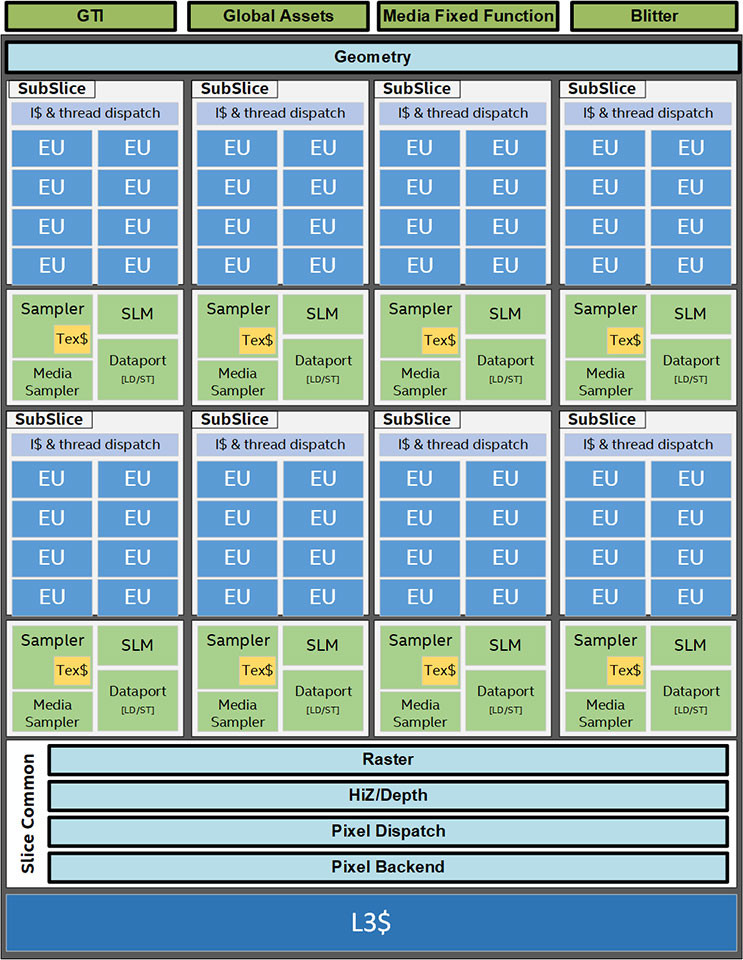
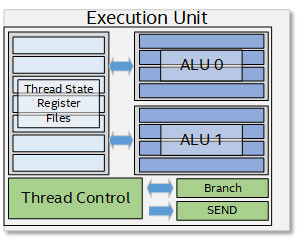
Each Subslice begins with an instruction cache and thread dispatch that divides the number-crunching workload between eight execution units or EUs. Gen11 GT2 has 64 EUs, which is a 166% growth over the 24 EUs that we saw with Gen9.5 GT2 (for example on Core i9-9900K). Such a significant increase in EUs will probably double performance, to make up lost ground against AMD's Ryzen APUs. Each EU packs two ALUs with four execution pipelines each, register files, and a thread control unit. Certain other components are shared between the EUs, such as media samplers. Intel is updating the media engine of its integrated graphics to support hardware acceleration of more video formats, including 10-bpc VP9. The display controller now supports Panel Self Refresh, Display Context Save and Restore, VESA Adaptive-Sync, and support for USB-C based outputs.
27 Comments on Intel Gen11 Architecture and GT2 "Ice Lake" iGPU Detailed
That's all I can say ATM because I"m not expecting anything much different than what's been before.
If the percentage increase is good that would be great, esp if the pricetag for it doesn't amount to wallet-rape.
Edit:
I suppose this is the one:
software.intel.com/sites/default/files/managed/db/88/The-Architecture-of-Intel-Processor-Graphics-Gen11_R1new.pdf
I'm still wondering about what the pricetag would be, hopefully good but that's something we have no real control over except by voting with our wallets come release time.
64 EU Gen11 is 512 shaders.
Architectural changes aside, this is over 2.5 times the compute power.
I think ~2x is a reasonable estimate though
And final specs (Clockspeeds) I'd have to think aren't exactly set in stone just yet, esp if during development they run into problems like before and are forced to tweak things so it works without issues in the end.
Much work to be done yet with it.
I wonder if they will revisit eDRAM or maybe have a go atHBM any time soon. Alternatively 3-channel memory could also be an option.
Bottom line I think is a minor clock bump for CPU along with substantial IGP improvements. Broadwell v2... Inb4 another 5775C that will be a rare unicorn in the wild. Given Intel's 10nm woes, that seems plausible...
From ~ software.intel.com/sites/default/files/managed/db/88/The-Architecture-of-Intel-Processor-Graphics-Gen11_R1new.pdf
Really not sure about the GTI bandwidth, how important is write for a GPU?
2x in terms of efficiency/IPC or 2x from Gen9.5 GT2 to Gen11 GT2? I do not believe it will do twice the efficiency. On the other hand, Gen11 GT2 having twice the performance of Gen9.5 GT2 would be slightly disappointing.
On the other hand, Ice Lake/Sunny Cove is very interesting. It will be the first architectural improvement in 4 years, and Intel have promised improvements for both "single thread" and "ISA", whatever that implies.
We don't have any solid information on the performance characteristics of Sunny Cove yet, and while I'm not expecting huge improvements, I'm pretty sure it will be distinct improvement in IPC. We don't know any of the specs of the front-end of the CPU yet, but we do know Sunny Cove features significant changes in L1/L2 cache configurations and bandwidth. On the execution side it features over double integer mul/div performance (but no changes to ALUs), along with large improvements in load/store bandwidth and memory address calculations. Sunny Cove is clearly engineered for higher throughput, but what that means in terms of IPC gains is hard to tell, especially since we don't know the details of the important front-end which feeds this "beast".