Monday, June 29th 2020

Intel Updates Its ISA Manual with Advanced Matrix Extension Reference
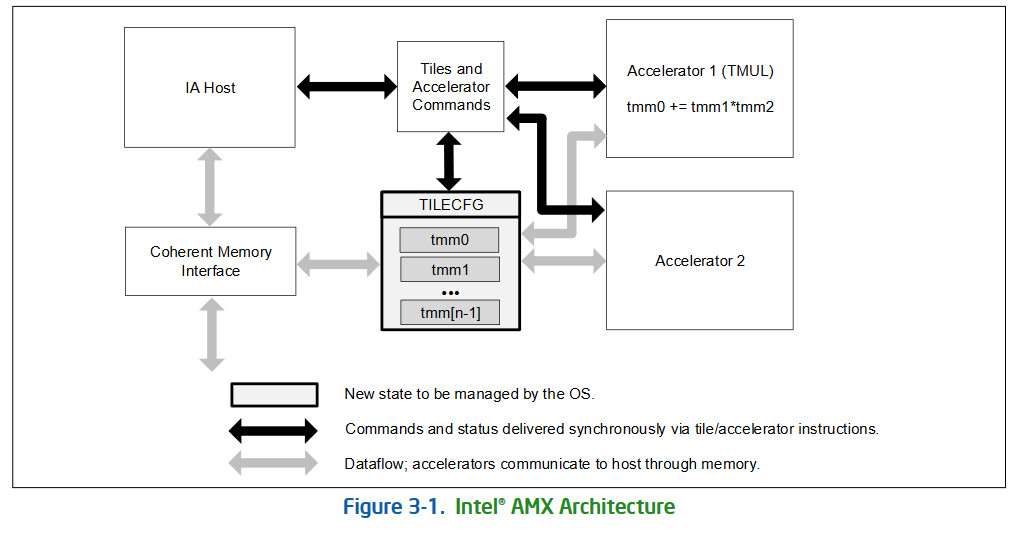
Intel today released and updated version of its "Architecture Instruction Set Extensions and Future Features Programming" Reference document with the latest advanced matrix extension (AMX) programming reference. This gives us some insights into AMX and how it works. While we will not go in too much depth here, the AMX is pretty simple. Intel describes it as the following: "Intel Advanced Matrix Extensions (Intel AMX) is a new 64-bit programming paradigm consisting of two components: a set of 2-dimensional registers (tiles) representing sub-arrays from a larger 2-dimensional memory image, and an accelerator able to operate on tiles, the first implementation is called TMUL (tile matrix multiply unit)." In other words, this represents another matrix processing extension that can be used for a wide variety of workload, mainly machine learning processing. The first microarchitecture that will implement the new extension is Sapphire Rapids Xeon processor. You can find more about AMX here.
4 Comments on Intel Updates Its ISA Manual with Advanced Matrix Extension Reference
A few notes:
* This seems to be a competitor against NVidia's Tensor cores.
* Unlike NVidia Tensor Cores, these Intel AMX instructions seem to handle rectangular matricies (2x3 matrix).
* IIRC, NVidia Tensor cores are a full matrix-multiply instruction. These AMX instructions are "only" dot-product.
-----------
AMD's tensor operations are clearly in AMD's SIMD-processor. Vega / RDNA chips instead. I would expect AMD to push tensor processing to the GPU, while focusing on CPU I/O and core count.