Supermicro Begins Volume Shipments of Max-Performance Servers Optimized for AI, HPC, Virtualization, and Edge Workloads
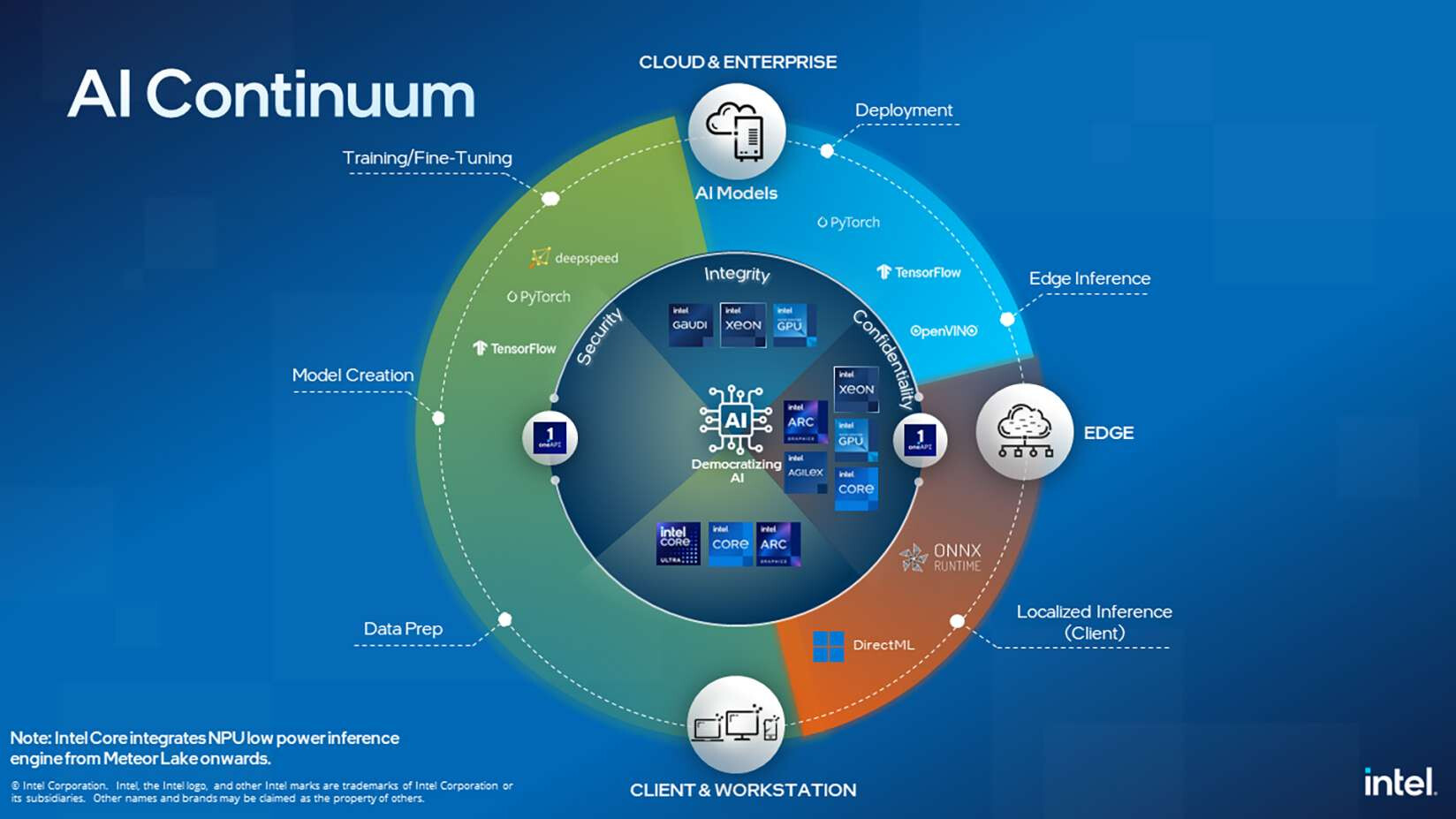
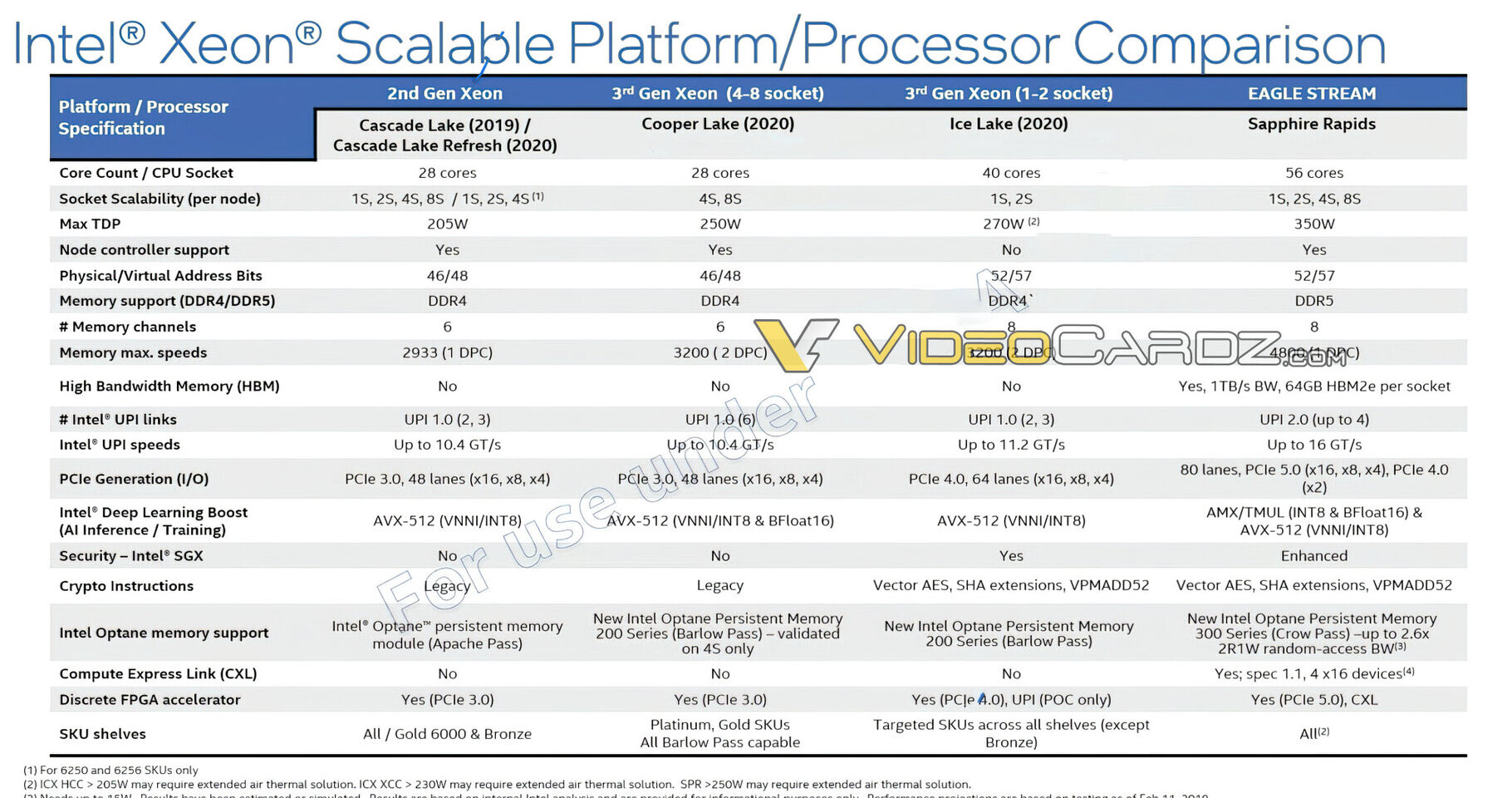
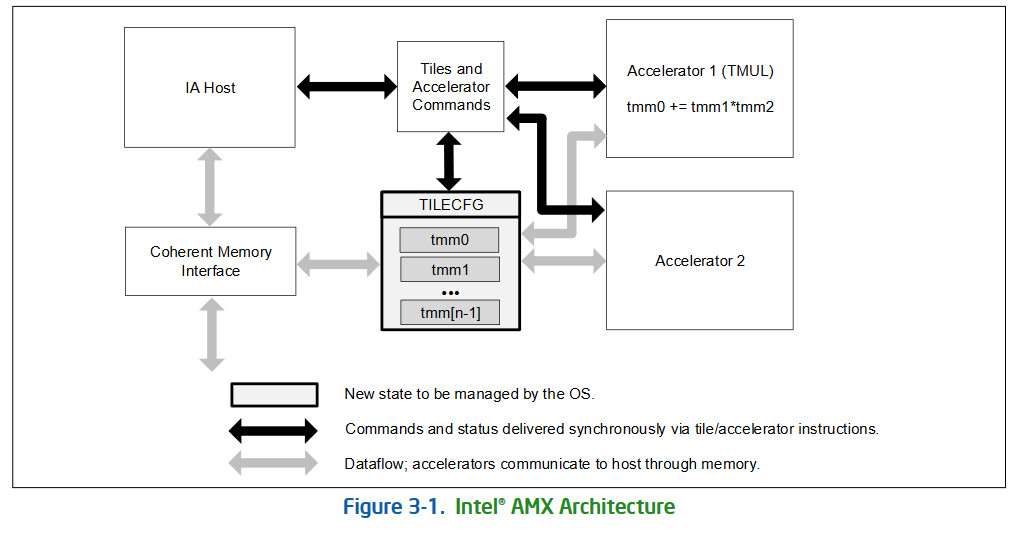
Supermicro, Inc. a Total IT Solution Provider for AI/ML, HPC, Cloud, Storage, and 5G/Edge is commencing shipments of max-performance servers featuring Intel Xeon 6900 series processors with P-cores. The new systems feature a range of new and upgraded technologies with new architectures optimized for the most demanding high-performance workloads including large-scale AI, cluster-scale HPC, and environments where a maximum number of GPUs are needed, such as collaborative design and media distribution.
"The systems now shipping in volume promise to unlock new capabilities and levels of performance for our customers around the world, featuring low latency, maximum I/O expansion providing high throughput with 256 performance cores per system, 12 memory channels per CPU with MRDIMM support, and high performance EDSFF storage options," said Charles Liang, president and CEO of Supermicro. "We are able to ship our complete range of servers with these new application-optimized technologies thanks to our Server Building Block Solutions design methodology. With our global capacity to ship solutions at any scale, and in-house developed liquid cooling solutions providing unrivaled cooling efficiency, Supermicro is leading the industry into a new era of maximum performance computing."



"The systems now shipping in volume promise to unlock new capabilities and levels of performance for our customers around the world, featuring low latency, maximum I/O expansion providing high throughput with 256 performance cores per system, 12 memory channels per CPU with MRDIMM support, and high performance EDSFF storage options," said Charles Liang, president and CEO of Supermicro. "We are able to ship our complete range of servers with these new application-optimized technologies thanks to our Server Building Block Solutions design methodology. With our global capacity to ship solutions at any scale, and in-house developed liquid cooling solutions providing unrivaled cooling efficiency, Supermicro is leading the industry into a new era of maximum performance computing."