Wednesday, September 28th 2022

Intel Outs First Xeon Scalable "Sapphire Rapids" Benchmarks, On-package Accelerators Help Catch Up with AMD EPYC
Intel in the second day of its InnovatiON event, turned attention to its next-generation Xeon Scalable "Sapphire Rapids" server processors, and demonstrated on-package accelerators. These are fixed-function hardware components that accelerate specific kinds of popular server workloads (i.e. run them faster than a CPU core can). With these, Intel hopes to close the CPU core-count gap it has with AMD EPYC, with the upcoming "Zen 4" EPYC chips expected to launch with up to 96 cores per socket in its conventional variant, and up to 128 cores per socket in its cloud-optimized variant.
Intel's on-package accelerators include AMX (advanced matrix extensions), which accelerate recommendation-engines, natural language processing (NLP), image-recognition, etc; DLB (dynamic load-balancing), which accelerates security-gateway and load-balancing; DSA (data-streaming accelerator), which speeds up the network stack, guest OS, and migration; IAA (in-memory analysis accelerator), which speeds up big-data (Apache Hadoop), IMDB, and warehousing applications; a feature-rich implementation of the AVX-512 instruction-set for a plethora of content-creation and scientific applications; and lastly, the QAT (QuickAssist Technology), with speed-ups for data compression, OpenSSL, nginx, IPsec, etc. Unlike "Ice Lake-SP," QAT is now implemented on the processor package instead of the PCH.
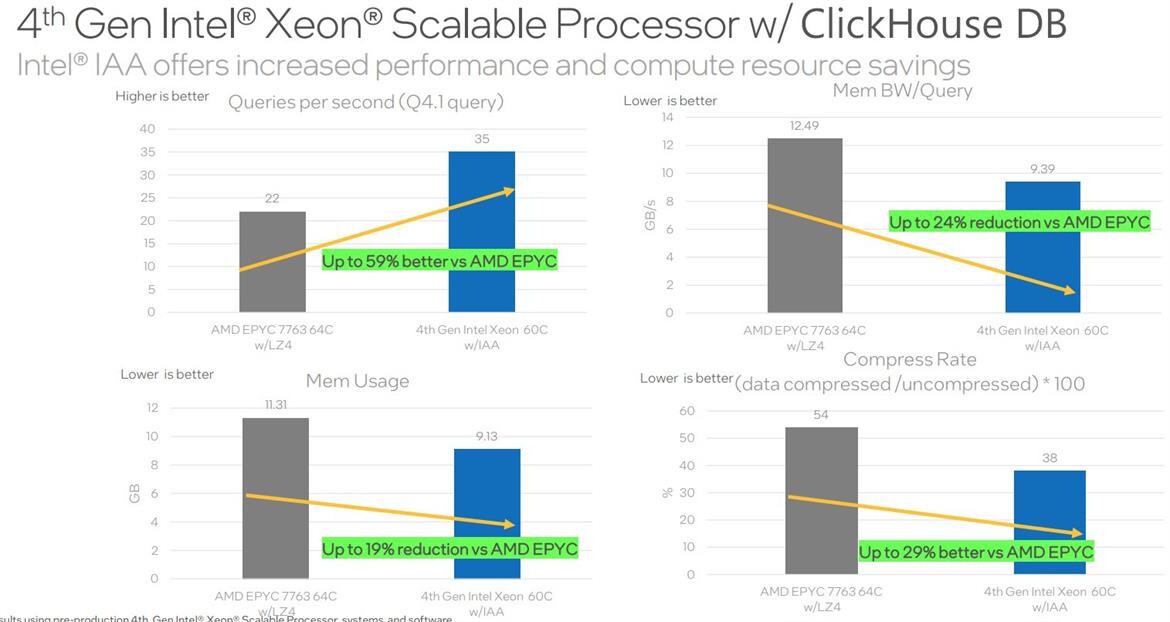
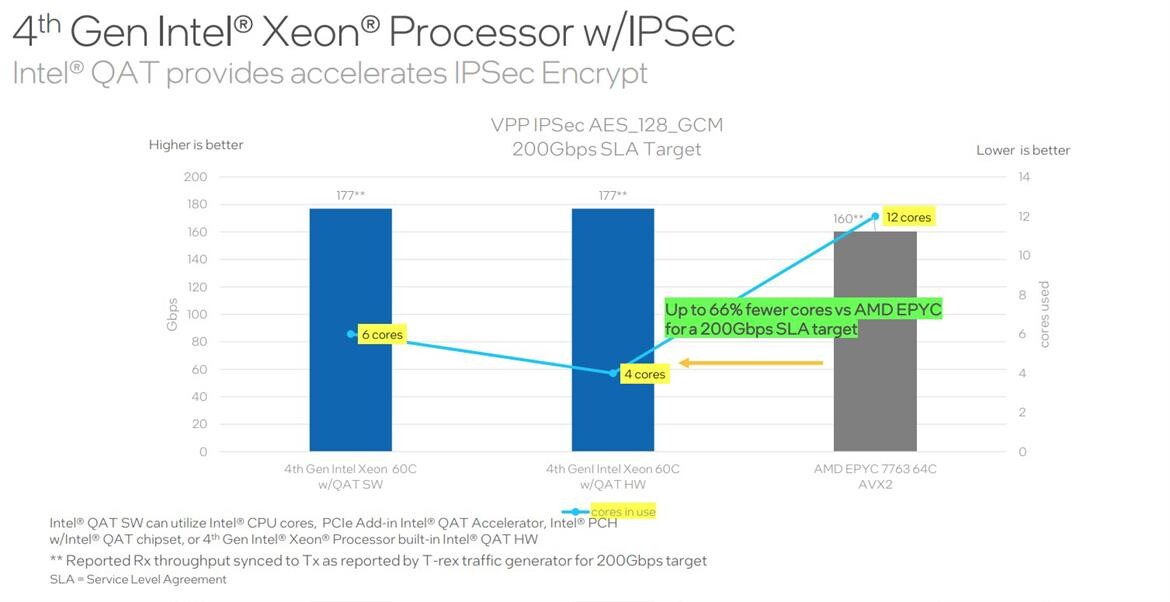
 Intel's benchmarks for the Xeon Scalable "Sapphire Rapids" focus on each of the above accelerators, and how they help the processor work "smarter" than AMD EPYC and overcome the CPU core deficit; as well as save power along the way. The first set of benchmarks focus on Intel AMX, and the speed-up it offers with ResNet50v1.5 Tensorflow AI Image Classification benchmarks. The second set of benchmarks showcases the data-compression speed-up with QAT implemented at scale, with QATzip Level 1. The third set focuses on big-data analysis accelerated by IAA, using ClickHouse and RocksDB. The next set shows off the SPDK NVMe TCP Storage Performance acceleration provided by DSA. QAT is shown accelerating nginx and IPsec encryption.
Intel's benchmarks for the Xeon Scalable "Sapphire Rapids" focus on each of the above accelerators, and how they help the processor work "smarter" than AMD EPYC and overcome the CPU core deficit; as well as save power along the way. The first set of benchmarks focus on Intel AMX, and the speed-up it offers with ResNet50v1.5 Tensorflow AI Image Classification benchmarks. The second set of benchmarks showcases the data-compression speed-up with QAT implemented at scale, with QATzip Level 1. The third set focuses on big-data analysis accelerated by IAA, using ClickHouse and RocksDB. The next set shows off the SPDK NVMe TCP Storage Performance acceleration provided by DSA. QAT is shown accelerating nginx and IPsec encryption.






Intel's on-package accelerators include AMX (advanced matrix extensions), which accelerate recommendation-engines, natural language processing (NLP), image-recognition, etc; DLB (dynamic load-balancing), which accelerates security-gateway and load-balancing; DSA (data-streaming accelerator), which speeds up the network stack, guest OS, and migration; IAA (in-memory analysis accelerator), which speeds up big-data (Apache Hadoop), IMDB, and warehousing applications; a feature-rich implementation of the AVX-512 instruction-set for a plethora of content-creation and scientific applications; and lastly, the QAT (QuickAssist Technology), with speed-ups for data compression, OpenSSL, nginx, IPsec, etc. Unlike "Ice Lake-SP," QAT is now implemented on the processor package instead of the PCH.







9 Comments on Intel Outs First Xeon Scalable "Sapphire Rapids" Benchmarks, On-package Accelerators Help Catch Up with AMD EPYC
Honestly kinda disappointed with something like this with Alderlake and Rocketlake being pretty solid.
But I guess this has been in development hell for a while and only now coming out, dated on release.
I said this was the future and people thought it was silly. -_-
It looks like it's the last moment to publish data showing meaningful improvement from dedicated accelerators: before the Genoa(-X) hits market at the same time SPR does (or earlier).
Genoa (-X) will have 1.5x cores at higher IPC (vs. Milan shown as comparison) plus AVX-512.
Judging by Milan's (non-X) results it looks like Genoa(-X) can be:
- probably competitive with AMX at ResNet (because of AVX-512 and 1.5x cores)
- slightly better than IAA at LZ4 (more cores)
- competitive with DSA at CRC32, at least on smaller blocks (charts look like they selected comparison on larger blocks, probably because of some overhead or latency, as 16k improvements are lower);
- 8 fewer occupied cores at QAT (or even 50 in the second chart) is somewhat moot if you have 32 more cores on package (so +64 in 2P); and the cores are faster...
So probably the QATzip will be the only one not matched/overpowered by Genoa's general-purpose cores; and Genoa won't need software rewrites.
And it's kind of worrying (for SPR) to see Milan slightly better than SPR at QAT/OpenSSL in OOB configuration (same result at 67 vs. 70 cores) and in compression (both zlib and ISA/L).
Quote was found here...
www.tomshardware.com/news/intel-delays-xeon-scalable-sapphire-rapids-again
"We would have liked more of that gap, more of that leadership window for our customers in terms of when we originally forecasted the product to be out and ramping in high volume, but because of the additional platform validation that we're doing, that window is a bit shorter. So it will be leadership — it depends on where the competition lands," (Sandra L. Rivera is executive vice president and general manager of the Datacenter and AI Group at Intel)
Soo Intel Expects to beat Milan, but get stomped by Genoa.
The problem with ASICs is that they are very inefficient software wise. For each and every new ASIC you need to code from scratch trying to work into strengths of that particular ASIC. This is very time consuming, never mind expensive.
Now imagine that every software company out there which has a strong software suite (Adobe, Autodesk, Blender, various scientific software, etc.), imagine if they had to code from scratch for different ASICs just in hopes that some of them might get used. See? ASICs make sense from hardware point of view, software not so much if at all.
Hell, even the name says it all ASIC - Application-specific integrated circuit; it's an Application-specific hardware, meaning hardware made for a specific application or a small class of those. This is very much opposed to the CPU, which is very generic and can run any software as long as it has a compiler for the CPU architecture (this is pretty much a given nowadays). Where you can as SW company (from my first example) work on your software without having to worry which hardware it will be run on, as you you provide that software in multiple binary or distribution forms, but not for any ASICs (obviously). :laugh:
I would much like some In Order Operations in the instructions of the cpu, however this isn't in possible in the current desin of OoO ( out of Order opertations). I mean sure there are tricks programers can do from trying to get to run in order from the out of order. But why not use the an A.A or algorythom to Sense which works fasters for certain code. Like it would run it in both Out of out order on one try & in roder in another try. Not like the Speculation that's currently in the instuction cache no this would have been measure on the end of the execute not the beginning.
Out of order would always be faster than in order unless no instructions could be re-ordered, which is almost never the case.
There is a reason why OoO was introduced in the first place. It's to increase performance by eliminating bottlenecks and avoiding NOP operations, avoiding having to wait for result of some instruction before starting work on next instructions.