Tuesday, June 30th 2020

AMD Ryzen 7 4700GE Memory Benchmarked: Extremely Low Latency Explains Tiny L3 Caches
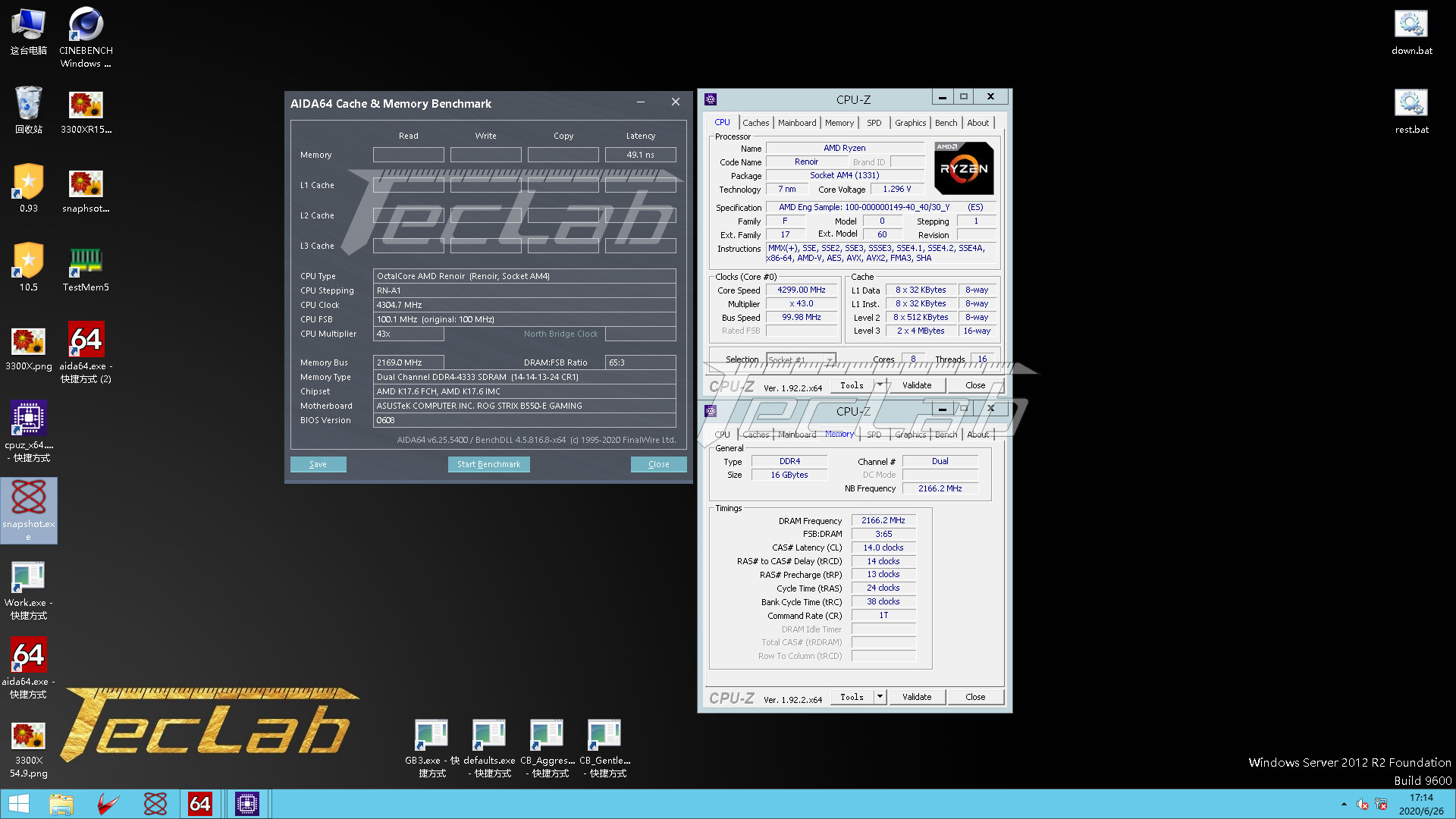
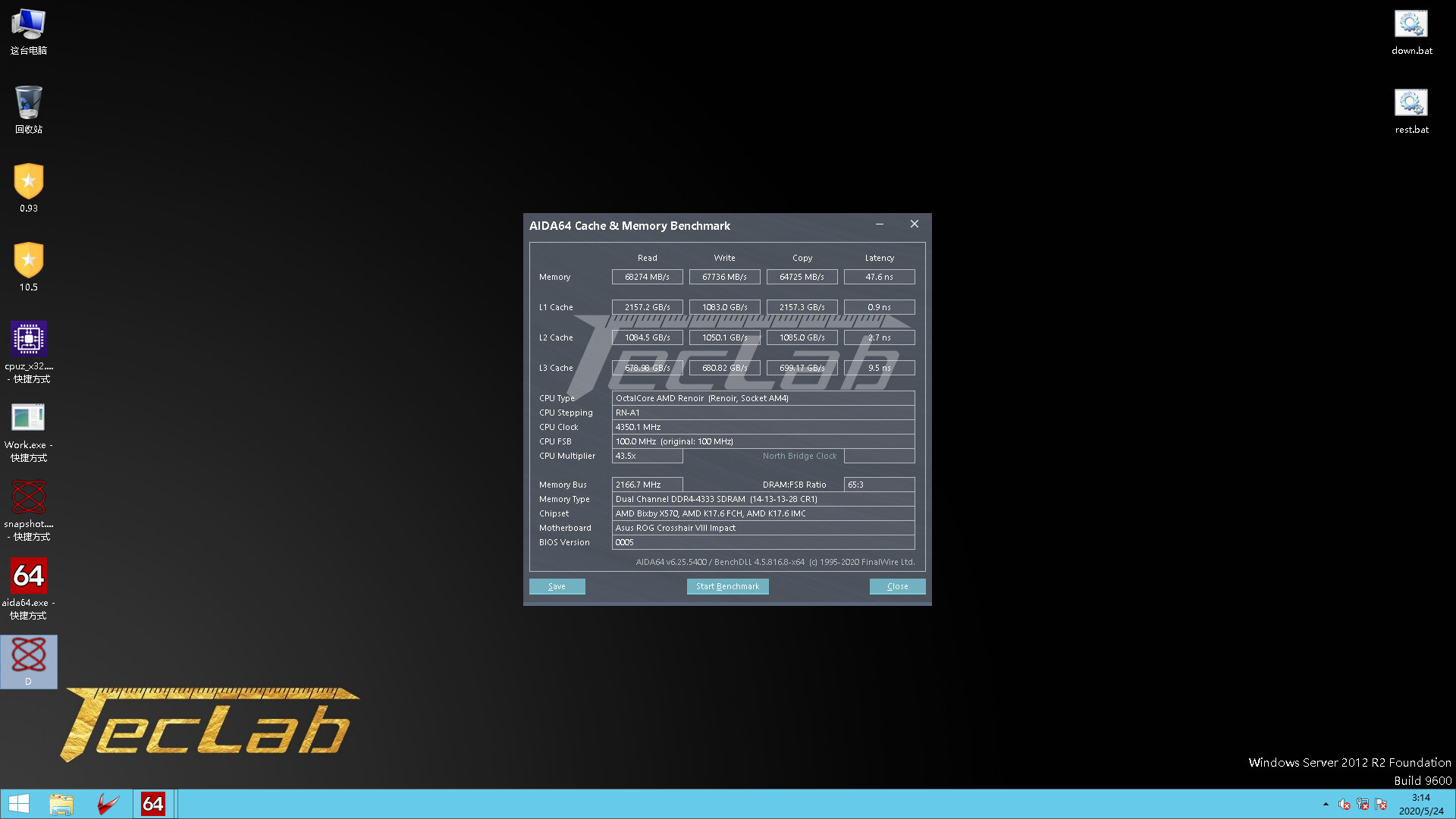
AMD's 7 nm "Renoir" APU silicon, which features eight "Zen 2" CPU cores, has only a quarter of the L3 cache of the 8-core "Zen 2" CCD used in "Matisse," "Rome," and "Castle Peak" processors, with each of its two quad-core compute complexes (CCXs) featuring just 4 MB of it (compared to 16 MB per CCX on the 8-core "Zen 2" CCD). Chinese-language tech publication TecLab pubished a quick review of an alleged Ryzen 7 4700GE socket AM4 processor based on the "Renoir" silicon, and discovered that the chip offers significantly lower memory latencies than "Matisse," posting just 47.6 ns latency when paired with DDR4-4233 dual-channel memory.
In comparison, a Ryzen 9 3900X with these kinds of memory clocks typically posts 60-70 ns latencies, owing to the MCM design of "Matisse," where the CPU cores and memory controllers sit on separate dies, which is one of the key reasons AMD is believed to have doubled the L3 cache amount per CCX compared to previous-generation "Zeppelin" dies. TecLab tested the alleged 4700GE engineering sample on a ROG Crosshair VIII Impact X570 motherboard that has 1 DIMM per channel (the best possible memory topology).



Sources:
TecLab (Bilibili), Komachi Ensaka (Twitter)
In comparison, a Ryzen 9 3900X with these kinds of memory clocks typically posts 60-70 ns latencies, owing to the MCM design of "Matisse," where the CPU cores and memory controllers sit on separate dies, which is one of the key reasons AMD is believed to have doubled the L3 cache amount per CCX compared to previous-generation "Zeppelin" dies. TecLab tested the alleged 4700GE engineering sample on a ROG Crosshair VIII Impact X570 motherboard that has 1 DIMM per channel (the best possible memory topology).


19 Comments on AMD Ryzen 7 4700GE Memory Benchmarked: Extremely Low Latency Explains Tiny L3 Caches
Current ryzen 3000 series desktop cpus would probably go super close to that if it wouldnt desync the fclk with the others
Would be more interesting to see what it does on 3200cl14 for example, or 3600 cl 14 at least
The amount of people that has kits that goes to 4333 cl14-13-13-28 is pretty low
Here are my 3600 4.2Ghz results, with the best mem stable mem settings that matisse can do.
The closest and most comparable results to the 47.6 on the screenshot seem to be:
4200CL18 on 9600KF at 44.5
4266CL15 on 9900K at 33.6
(Keep in mind that compared to 4233CL14, 4266CL15 should be about 6% slower and 4200CL18 almost 30% slower in raw latency)
The frequency depends a bit more on the motherboard but many newer 8Gbit ICs don't struggle to run into the mid 4000s on recent motherboards. Stuff like Rev E, DJR, and D-die for example... I expect with normal voltages for these to land around 10ns quicker than what is currently being done on Matisse.Depends on the access patterns of the program. Ryzen's L3 also gets used differently than Intel's skylake/xcove L3 because of Ryzen using exclusive victim caching while intel has been using inclusive (to L2).
Matisse and Renoir have the same L3$ associativity, that means L3$ tag check has the same latency.
Also both chips have the same 10ns L3$ access latency, it means dram access penalty is the same too.
It's interconnect and purely interconnect which matters (Yes there is a physical difference in delay but who's counting 0.2ns or so)
however, the cpu and memory controller on the same die may allow the frequency of said interconnect at higher frequency as it's not going across a substrate to another chip and thus why it clocks higher.
Just a tiny correction, and information as many thing physical distance matters for latency and no it does not it does have massive implications to power consumption which is the drawback of chiplets :).