Thursday, March 9th 2023
South Korean Company Morumi is Developing a CPU with Infinite Parallel Processing Scaling
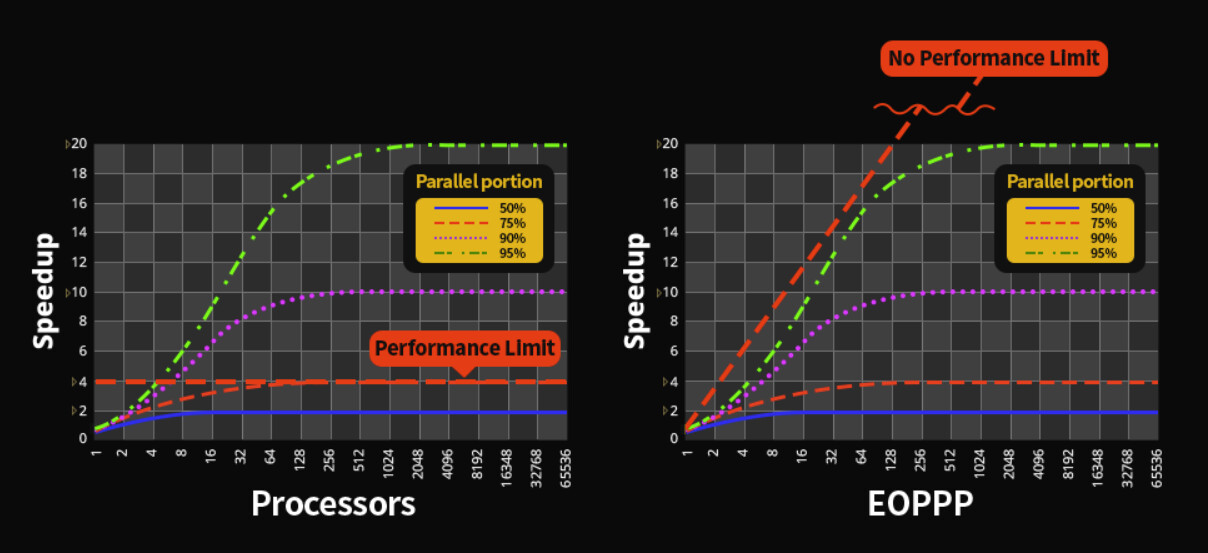
One of the biggest drawbacks of modern CPUs is that adding more cores doesn't equal more performance in a linear fashion. Parallelism in CPUs offer limited scaling for most applications and even none for some. A South Korean company called Morumi is now taking a stab at solving this problem and wants to develop a CPU that can offer more or less infinite processing scaling, as more cores are added. The company has been around since 2018 and focused on various telecommunications chips, but has now started the development on what it calls every one period parallel processor (EOPPP) technology.
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
Sources:
The Elec, Morumi
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
29 Comments on South Korean Company Morumi is Developing a CPU with Infinite Parallel Processing Scaling
Internally to the Zen4 is something like 8 parallel pipelines, per core. These CPUs are capable of executing 4 instructions per clock tick, all the way up to 6 or so (other bottlenecks prevent all 8 pipelines from being used). Zen4 manages to shove even more "compute" using AVX512. Intel is pretty similar, and Apple actually has the widest CPU today (most instructions in parallel at once). Most importantly, CPUs find parallelism by executing code out of order (aka: OoO scheduler). The retirement unit "puts the calculations back into order", so to speak, and the decoder figures out when out-of-order parallelism is legal and possible.
But even with all the OoO tricks, no CPU can perform as "wide" as a GPU. But GPUs unlock parallelism through the help of the programmer. IE: You have to write your shaders in "just the right way" for parallelism to work on a GPU (see CUDA, OpenCL, DirectX, etc. etc. All languages designed to show the GPU hardware "where infinite work" exists, so it knows how to execute it in parallel). Though difficult to learn at first, programmers have gotten better-and-better at programming in GPU-style coding. So instead of a GPU spending a lot of transistors/power trying to find OoO parallelism, its "already laid out in a parallel fashion" by the programmer+compiler team.
So those are the two traditional paths: CPUs to maximize traditional code writing (finding hidden parallelism in "traditional" code from a C compiler or other legacy system), and now GPUs where the programmer unlocks parallelism through explicitly laying out data in grids / blocks / groups for CUDA to automatically split between your GPU units.
-------------
There was one other methodology: VLIW, aka Intel Itanium, which is somewhere "in between" traditional CPU and traditional GPU. Its wider than a normal CPU, but not as wide as a GPU. It mostly works on normal code, but the assembly language was extremely difficult for compilers to work with. The magical compilers never really came into existence. Still, VLIW works out today in modern DSPs, where programmers code in a way where VLIW works out. But this isn't very mainstream.
----------------
That's about all the patterns I'm personally aware of. If this Korean company made up a new pattern, it'd be interesting... but also highly research-y. Even VLIWs and GPUs have multiple decades of research to draw from.
There's a lot to this that seems like breaking the laws of Computer Science. (Ahmdal's law is... a law. It cannot be broken, though it can be reinterpreted in favorable manners). So my bullshit detector is kinda going off, to be honest. Still though, Alchemists (though full of bullshit), managed to invent modern Chemistry. So maybe they're onto something, but maybe they don't know how to communicate their ideas yet? I wish them luck, and maybe they can publish a paper or deeper discussion on what makes their methodology unique over the traditional CPU, GPU, or VLIW methods in use today to extract fine-grained parallelism automatically (or semi-automatically)
----------
I probably have to note one more thing: this "AI Boom" is important to compute-makers because AI is an infinite amount of work as per Gustafson's Law (en.wikipedia.org/wiki/Gustafson's_law), the little known "reciprocal" to Ahmdal's law. (Its literally just 1/Ahmdal ). While you can't speed up a given task infinitely with parallelism, you can often make a task 2x more difficult, or 4x more difficult, or 100x more difficult, and then parallelize it easily.
Sound familiar? The traditional source of Gustafson's Law is GPUs, as we tried to parallelize more-and-more pixels, triangles, shaders, light calculations, reflections, and now ray-tracing. But AI now promises a new infinite source of easily parallelized work that (maybe??) people will buy.
As long as you can figure out ways to make "tasks infinitely more difficult", you can "infinitely make them more parallel", and then parallel-compute machines become more useful.
Thing is, you can do it on literally any hardware with multiple execution units.