Saturday, April 1st 2023

DirectX 12 API New Feature Set Introduces GPU Upload Heaps, Enables Simultaneous Access to VRAM for CPU and GPU
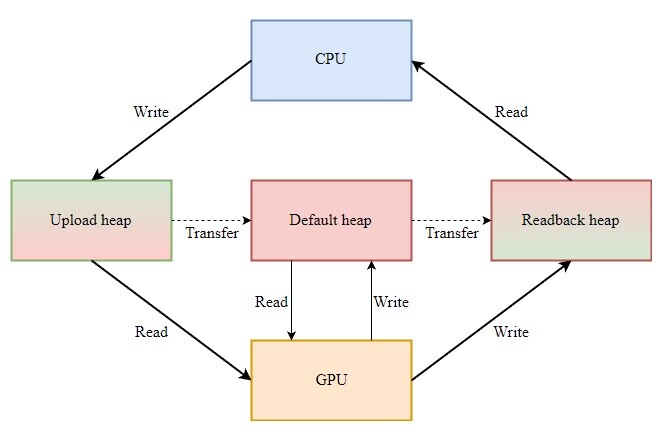
Microsoft has implemented two new features into its DirectX 12 API - GPU Upload Heaps and Non-Normalized sampling have been added via the latest Agility SDK 1.710.0 preview, and the former looks to be the more intriguing of the pair. The SDK preview is only accessible to developers at the present time, since its official introduction on Friday 31 March. Support has also been initiated via the latest graphics drivers issued by NVIDIA, Intel, and AMD. The Microsoft team has this to say about the preview version of GPU upload heaps feature in DirectX 12: "Historically a GPU's VRAM was inaccessible to the CPU, forcing programs to have to copy large amounts of data to the GPU via the PCI bus. Most modern GPUs have introduced VRAM resizable base address register (BAR) enabling Windows to manage the GPU VRAM in WDDM 2.0 or later."
They continue to describe how the update allows the CPU to gain access to the pool of VRAM on the connected graphics card: "With the VRAM being managed by Windows, D3D now exposes the heap memory access directly to the CPU! This allows both the CPU and GPU to directly access the memory simultaneously, removing the need to copy data from the CPU to the GPU increasing performance in certain scenarios." This GPU optimization could offer many benefits in the context of computer games, since memory requirements continue to grow in line with an increase in visual sophistication and complexity.


 A shared pool of memory between the CPU and GPU will eliminate the need to keep duplicates of the game scenario data in both system memory and graphics card VRAM, therefore resulting in a reduced data stream between the two locations. Modern graphics cards have tended to feature very fast on-board memory standards (GDDR6) in contrast to main system memory (DDR5 at best). In theory the CPU could benefit greatly from exclusive access to a pool of ultra quick VRAM, perhaps giving an early preview of a time when DDR6 becomes the daily standard in main system memory.
A shared pool of memory between the CPU and GPU will eliminate the need to keep duplicates of the game scenario data in both system memory and graphics card VRAM, therefore resulting in a reduced data stream between the two locations. Modern graphics cards have tended to feature very fast on-board memory standards (GDDR6) in contrast to main system memory (DDR5 at best). In theory the CPU could benefit greatly from exclusive access to a pool of ultra quick VRAM, perhaps giving an early preview of a time when DDR6 becomes the daily standard in main system memory.
Sources:
Microsoft Dev Blogs, Zhang Doa
They continue to describe how the update allows the CPU to gain access to the pool of VRAM on the connected graphics card: "With the VRAM being managed by Windows, D3D now exposes the heap memory access directly to the CPU! This allows both the CPU and GPU to directly access the memory simultaneously, removing the need to copy data from the CPU to the GPU increasing performance in certain scenarios." This GPU optimization could offer many benefits in the context of computer games, since memory requirements continue to grow in line with an increase in visual sophistication and complexity.



54 Comments on DirectX 12 API New Feature Set Introduces GPU Upload Heaps, Enables Simultaneous Access to VRAM for CPU and GPU
But in reality it had partial DX11.
Also, They are directly connected to it. They do not need to go via the PCI-E Bus. Doesn't matter if the GPU have 1 TB/s of bandwidth when you have to go thru a PCI-E 16X bus that is limited to 32 GB/s at with PCI-E 4.0 or 64 GB with PCI-E 5.0.
You mostly just saving copy there.
but with dedicated GPU, i think it will only be used marginally.
32GB/s is far faster than any current NVME drives, and that bandwidth is used for other things at the same time - and 32GB/s is faster than any current NVME by a large amount, and is definitely going to be a lot faster than anything from system RAM since every reduced step takes out latency - and that latency is the killer
PCIe 4.0 16 lanes 32 GB/s bandwidth read direction is slightly above Xbox 360's 22.4 GB/s or about half of the texture memory bandwidth of Xbox One's 68 GB/s. PC iGPU is not limited by PCIe 4.0 16-lane link.
And also, i wonder how the cache will handle that as they cache memory line in main memory.the VRAM can't be compared to NVME so i am not sure what you are trying to describe here.
VRAM is temporary storage, same as main ram were NVME is long term storage. The data you would want to access in VRAM is probably not stored on the SSD anyway.
I see this more a good way to utilize more the GPU. Things like mesh shaders are super powerful, but you are limited to what you can do right now due to having to sync data between the GPU and CPU.
By example, i could see very complex mesh shaders that perform complex destructions on mesh that also affect the collision model. with this tech, the CPU could have the collision model in VRAM.
It will be really about exchanging temporary data. not static one.
Despite APU's single-chip design, Infinity Link still exists between IO and CCX blocks i.e. AMD's cut-n-paste engineering.
Renior APU example
There's a reason for some Epyc SKUs having double infinity links between CCD and IO.FYI, AMD 4700S APU recycled PS5 APU with 16 GB GDDR6-14000 memory for the PC market and it was benchmarked.
AMD supplied "Design for Windows" ACPI UEFI Firmware for recycled PS5 4700S APU to boot ACPI HAL-enabled Windows.
PS5 APU with "Design for Windows" ACPI UEFI Firmware is an AMD-based X86-64 PC.
My QNAP NAS has Intel Haswell Core i7 4770T CPU (45 watts) and it can't directly boot Windows since it's missing "Design for Windows" ACPI-enabled UEFI. The same Intel Haswell Core i7 4770T CPU was recycled from a slim office Windows-based PC.
AMD designed AM4 cooler mounting holes for 4800S. AMD is not throwing away defective console APUs with working Zen 2 CPUs in the bin i.e. BOM cost for these chips needs to be recovered.
It's a ton faster (latency wise) to go from NVME to VRAM, than it is any of the current methods - so even with bandwidth that's lower than VRAM speeds it's going to massively reduce stuttering on low VRAM cards, for example
Think more about data that both CPU and GPU need to have access to and that need to be modify on the GPU.
It's quite bit hard to see the real usage of this technology in gaming as many use case doesn't exist yet as it didn't make sense to use it
Using system ram as a landing zone from NVMe adds additional memory copy latency.
Nvidia's GPUdirect with CUDA skips system memory landing zone for direct NVMe to GPU VRAM.
MS's current DX12U Direct Storage build for PC doesn't skip system memory and has double data storage issue. PC's DX12U Direct Storage needs to evolved when DX12U gains AMD Fusion like feature i.e. this topic's DX12U improvements.
It has to be moved from storage TO ram, and no, you cant fit everything into RAM. There are multiple AAA titles out there with 100GB+ sizes right now.
If it has to go storage -> RAM -> VRAM it's got delays every step of the way, vs the GPU just loading what's needed directly
DXdiag for example now shows a mix of VRAM + system RAM, with directstorage your NVME drive becomes part of that setup too - and the GPU is aware of it, instead of the CPU processing all the work prior to that point.
What you discribe is Direct Storage. What this technology allow is for the CPU to be able to edit things in VRAM without having to copy them to local memory and also very importantly, without the GPU losing access to that data. It's true that you could maybe use that for something like Direct Storage, but it would be just be the tips of the iceberg. (And mostly, you don't need at all this technology to be able to acheive what you are describing, just DirectStorage is enough). Also Latency wise, the main source of latency will be the SSD access that is calculated in microseconds. System ram latency is calculated in nano seconds. But you save a big copy in ram so you save a lot of CPU cycles and also bandwidth by sending it directly where you want to send it.
This technology for scenario when you want to compute a data set with both GPU and CPU. Not just for copying stuff into VRAM without passing thru system RAM. This have usage outside of games right now but not much in game since you can't do that right now. The things possible to achieve with that will appear as the technology is deployed.
The current PC Direct Storage implementation has system memory as a landing zone.
The current PC Direct Storage implementation has the PC's legacy "double copy" issue.
Before Direct Storage on the Windows-based PC
Meanwhile, NVIDIA's GPUDirect on HPC markets
NVIDIA's RTX IO with Ampere generation developer.nvidia.com/rtx-io
PC's current Direct Storage implementation needs middleware evolution for direct NVME to GPU path i.e. this topic's DirectX12U's improvement direction.
PC's current Direct Storage Tier 1.1 implementation is half-baked. The console's DirectStorage model is the destination.
GPU decompression got added with Direct Storage 1.1
I was under the impression that Direct Storage 1.0 was directly from NVME to GPU but you are right. It's actually DMA access from main memory. The CPU doesn't have to intervene there and the GPU can communicate directly with the memory controller to get the data.
It's a bit the opposite of the technology described in this news.
In this news, it's the CPU that can access directly the GPU memory.
PC's current Direct Storage Tier 1.1 implementation. From devblogs.microsoft.com/directx/directstorage-1-1-now-available/
There are the chipset's DMA functions from NVMe to system memory (we're not in PIO modes) and then there are GPU's DMA functions from system memory to GPU memory.
---
For this topic, Microsoft has announced a new DirectX12 GPU optimization feature in conjunction with Resizable-BAR, called GPU Upload Heaps that allows the CPU to have direct, simultaneous access to GPU memory. This can increase performance in DX12 titles and decrease system RAM utilization since the feature circumvents the need to copy data from the CPU to the GPU.
CPU ping-pong between GPU VRAM is limited by PCIe 4.0 16 lanes (32 GB/s per direction).
Using PS4's Killzone Shadow Fall's example, the shared CPU-GPU data storage is usually small i.e. the bulk of CPU and GPU data sets don't need to be known by either CPU or GPU nodes e.g. CPU should not be interested in GPU's framebuffer and texture processing activities.
- cpu and GPU do very different things with different data, and
- sharing data between the gpu and cpu is very costly even with unified memory because of memory coherency : if the gpu and cpu want to modify the same memory range they have to be sychronized and their caches have to be flushed which destroys performance. The same issue occurs with atomic operations inside a multi core gpu, and it can destroy performance on a single chip with access to a common cache !