Wednesday, May 1st 2024

We Tested NVIDIA's new ChatRTX: Your Own GPU-accelerated AI Assistant with Photo Recognition, Speech Input, Updated Models
NVIDIA today unveiled ChatRTX, the AI assistant that runs locally on your machine, and which is accelerated by your GeForce RTX GPU. NVIDIA had originally launched this as "Chat with RTX" back in February 2024, back then this was regarded more as a public tech demo. We reviewed the application in our feature article. The ChatRTX rebranding is probably aimed at making the name sound more like ChatGPT, which is what the application aims to be—except it runs completely on your machine, and is exhaustively customizable. The most obvious advantage of a locally-run AI assistant is privacy—you are interacting with an assistant that processes your prompt locally, and accelerated by your GPU; the second is that you're not held back by performance bottlenecks by cloud-based assistants.
ChatRTX is a major update over the Chat with RTX tech-demo from February. To begin with, the application has several stability refinements from Chat with RTX, which felt a little rough on the edges. NVIDIA has significantly updated the LLMs included with the application, including Mistral 7B INT4, and Llama 2 7B INT4. Support is also added for additional LLMs, including Gemma, a local LLM trained by Google, based on the same technology used to make Google's flagship Gemini model. ChatRTX now also supports ChatGLM3, for both English and Chinese prompts. Perhaps the biggest upgrade ChatRTX is its ability to recognize images on your machine, as it incorporates CLIP (contrastive language-image pre-training) from OpenAI. CLIP is an LLM that recognizes what it's seeing in image collections. Using this feature, you can interact with your image library without the need for metadata. ChatRTX doesn't just take text input—you can speak to it. It now accepts natural voice input, as it integrates the Whisper speech-to-text NLI model.

 DOWNLOAD: NVIDIA ChatRTX
DOWNLOAD: NVIDIA ChatRTX
As with the original Chat with RTX tech-demo, the new ChatRTX application's biggest feature is its ability to let users switch between AI models, or to let it build and train your own dataset based on text and images on your local machine. You can point it to a folder with documents such as plaintext, Word (doc) and PDFs, as well as images; and it will train itself on answering queries related to the dataset.
There remain some major limitations with ChatRTX which we had hoped would be fixed since its February release, and that is context—the ability to ask follow-up questions. Apparently, follow-ups are harder to implement than they seem, as the model has to connect the new question to the previous ones and its responses to them. It's also inaccurate in attributing its responses to the right text tiles. The browser-based frontend only supports Chrome and Edge, it's buggy with Firefox.
ChatRTX is a major update over the Chat with RTX tech-demo from February. To begin with, the application has several stability refinements from Chat with RTX, which felt a little rough on the edges. NVIDIA has significantly updated the LLMs included with the application, including Mistral 7B INT4, and Llama 2 7B INT4. Support is also added for additional LLMs, including Gemma, a local LLM trained by Google, based on the same technology used to make Google's flagship Gemini model. ChatRTX now also supports ChatGLM3, for both English and Chinese prompts. Perhaps the biggest upgrade ChatRTX is its ability to recognize images on your machine, as it incorporates CLIP (contrastive language-image pre-training) from OpenAI. CLIP is an LLM that recognizes what it's seeing in image collections. Using this feature, you can interact with your image library without the need for metadata. ChatRTX doesn't just take text input—you can speak to it. It now accepts natural voice input, as it integrates the Whisper speech-to-text NLI model.
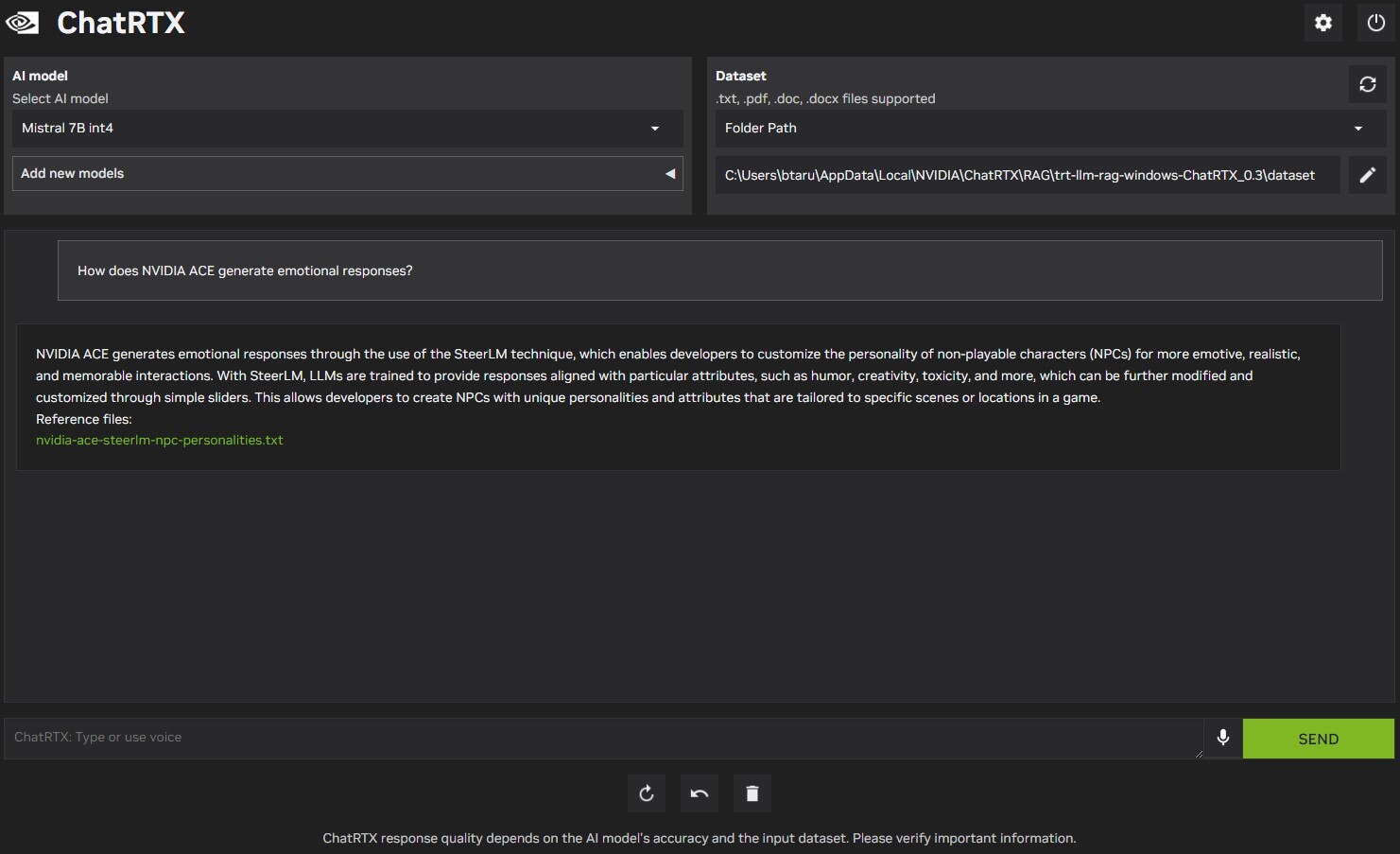

As with the original Chat with RTX tech-demo, the new ChatRTX application's biggest feature is its ability to let users switch between AI models, or to let it build and train your own dataset based on text and images on your local machine. You can point it to a folder with documents such as plaintext, Word (doc) and PDFs, as well as images; and it will train itself on answering queries related to the dataset.
There remain some major limitations with ChatRTX which we had hoped would be fixed since its February release, and that is context—the ability to ask follow-up questions. Apparently, follow-ups are harder to implement than they seem, as the model has to connect the new question to the previous ones and its responses to them. It's also inaccurate in attributing its responses to the right text tiles. The browser-based frontend only supports Chrome and Edge, it's buggy with Firefox.
25 Comments on We Tested NVIDIA's new ChatRTX: Your Own GPU-accelerated AI Assistant with Photo Recognition, Speech Input, Updated Models
All that's left is for Nvidia to create an assistant with the appearance of an Anime character to further captivate lonely nerds and keep them on a leash. If anyone wants, feel free to write down the idea for a film.
Have rope, will strangle....
First they captured the AI cloud-base, now they are wiggling their way into your pc's insides, which will spawn the command & control of all pc's everywhere, all the time, all at once...
And then, all that will remain is "Hello SkyNet, how can I help you infiltrate & destroy humanity today ?
No thanks, cause resistance is NOT futile !
Oh well... At least now people can get their wrong and nonsensical answers without risking [much of] their privacy.We had better.
Glad I didn't use Google or I might start getting targeted adverts...
'nuff said !
Until the next updateAll that's left for you to do is find a link that says Huang tried Ozempic and you're up for internet hero status. The ingredients are all there, live and in effect already... :D Who needs Netflix?
Placing creation against the creator is a cliché but it works. :toast:
Can copilot be run locally or is that coming?
Remember the debacle around Gemini on Pixels, when Google wanted to leave out the 8 because of "hardware limitations", despite it being exactly the same as the Pro, only with 8GB RAM instead of 12?
I believe what is going on here is companies figuring out ways to shrink their models while still offering useful functionality or otherwise compressing the models better, before declaring them ready to run on local machines.