NVIDIA NIM Microservices Now Available to Streamline Agentic Workflows on RTX AI PCs and Workstations
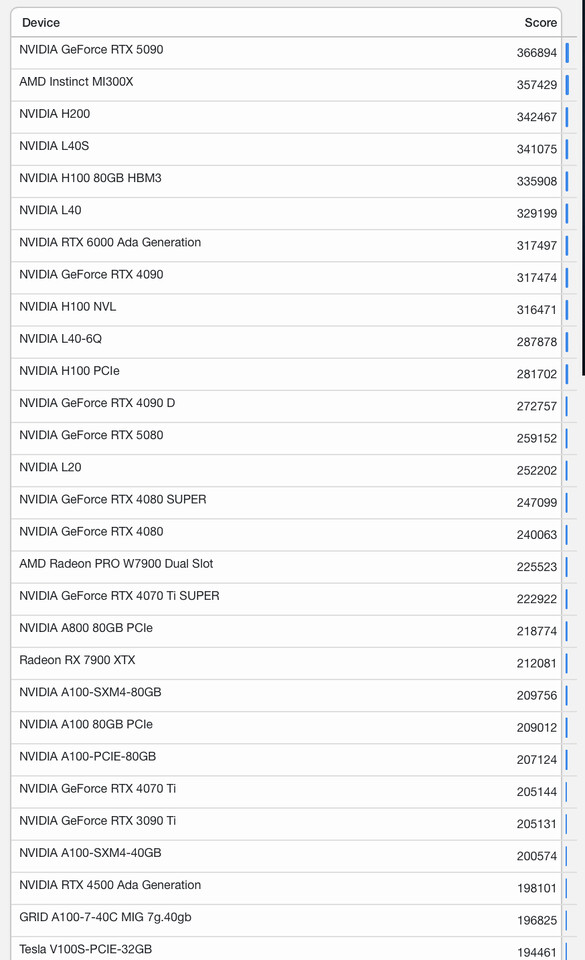
Generative AI is unlocking new capabilities for PCs and workstations, including game assistants, enhanced content-creation and productivity tools and more. NVIDIA NIM microservices, available now, and AI Blueprints, in the coming weeks, accelerate AI development and improve its accessibility. Announced at the CES trade show in January, NVIDIA NIM provides prepackaged, state-of-the-art AI models optimized for the NVIDIA RTX platform, including the NVIDIA GeForce RTX 50 Series and, now, the new NVIDIA Blackwell RTX PRO GPUs. The microservices are easy to download and run. They span the top modalities for PC development and are compatible with top ecosystem applications and tools.
The experimental System Assistant feature of Project G-Assist was also released today. Project G-Assist showcases how AI assistants can enhance apps and games. The System Assistant allows users to run real-time diagnostics, get recommendations on performance optimizations, or control system software and peripherals - all via simple voice or text commands. Developers and enthusiasts can extend its capabilities with a simple plug-in architecture and new plug-in builder.
The experimental System Assistant feature of Project G-Assist was also released today. Project G-Assist showcases how AI assistants can enhance apps and games. The System Assistant allows users to run real-time diagnostics, get recommendations on performance optimizations, or control system software and peripherals - all via simple voice or text commands. Developers and enthusiasts can extend its capabilities with a simple plug-in architecture and new plug-in builder.