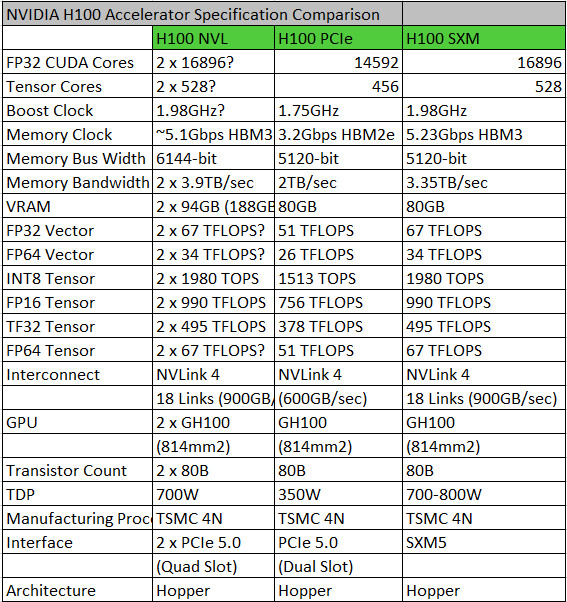
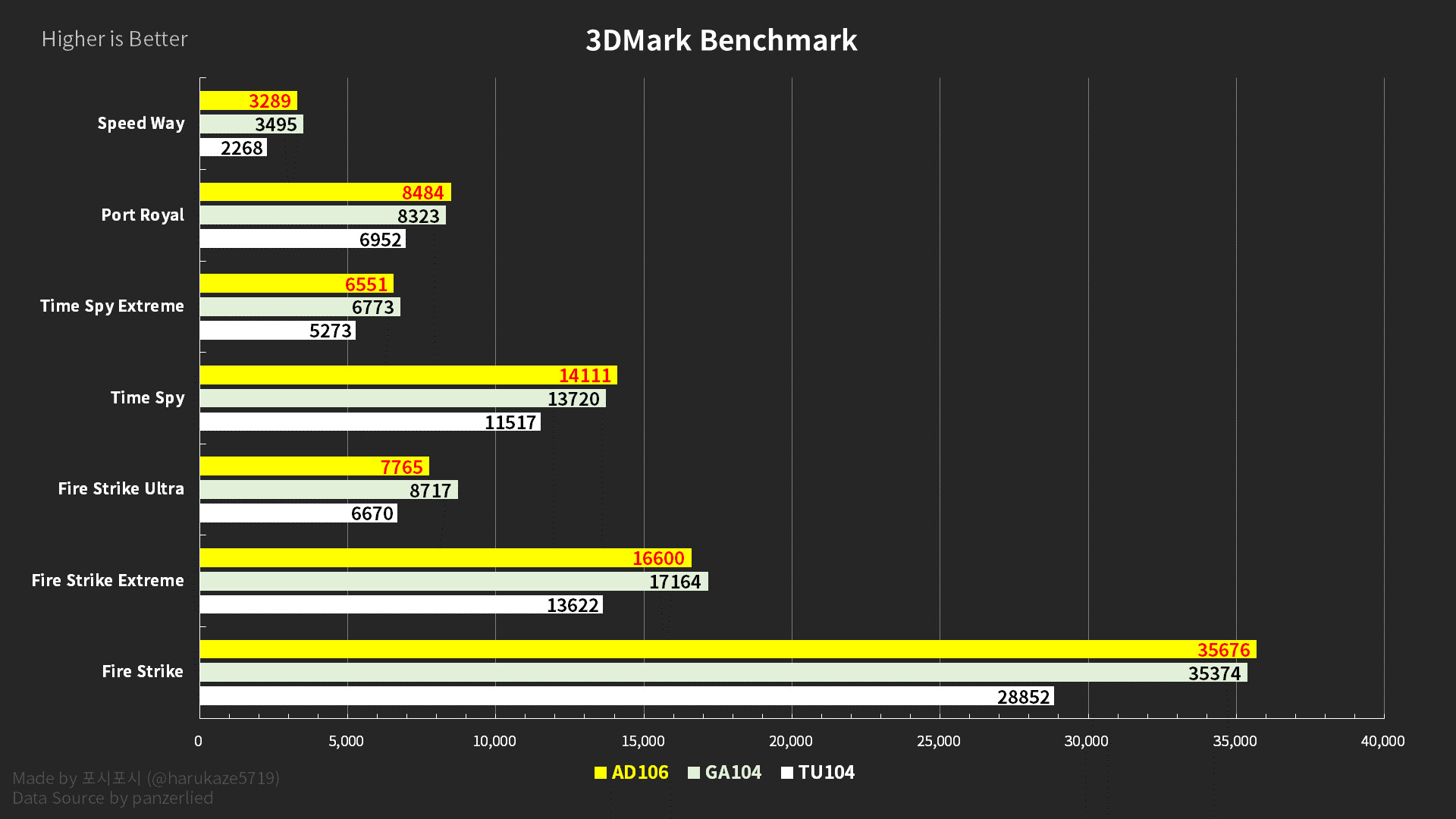
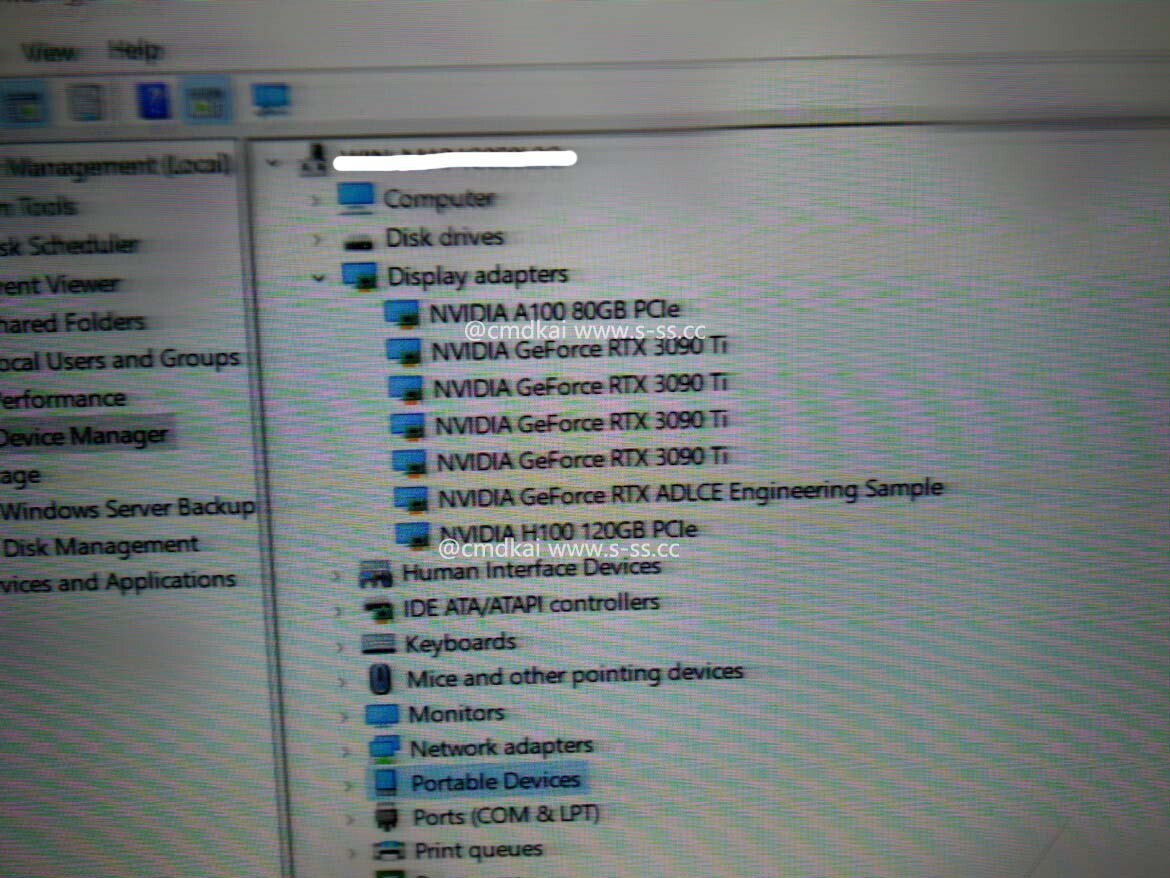
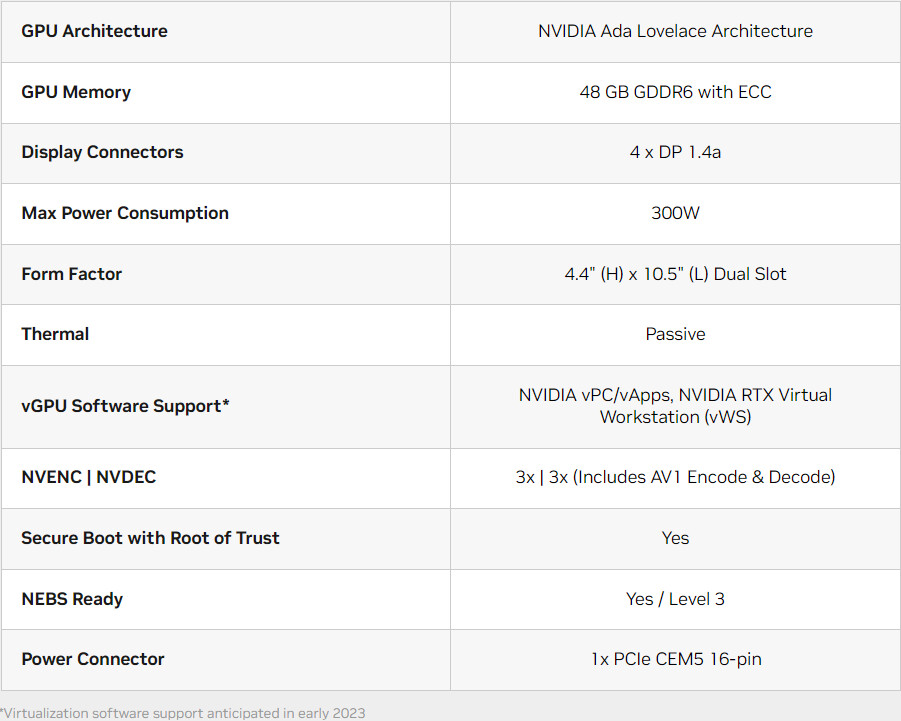
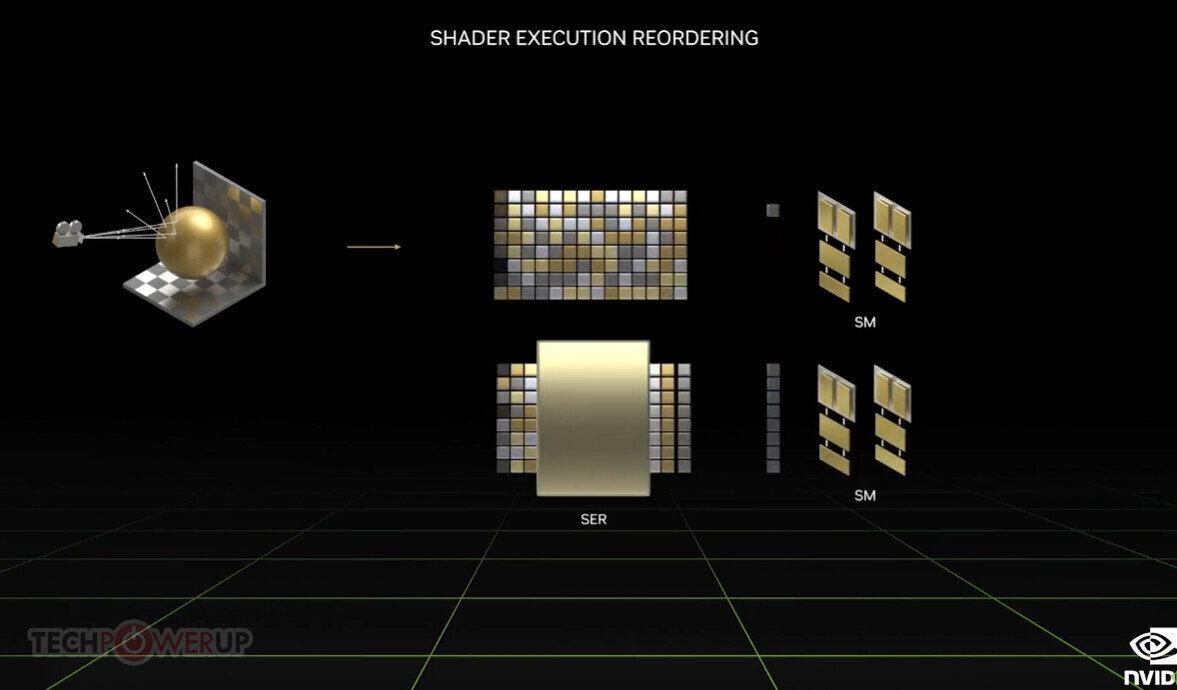
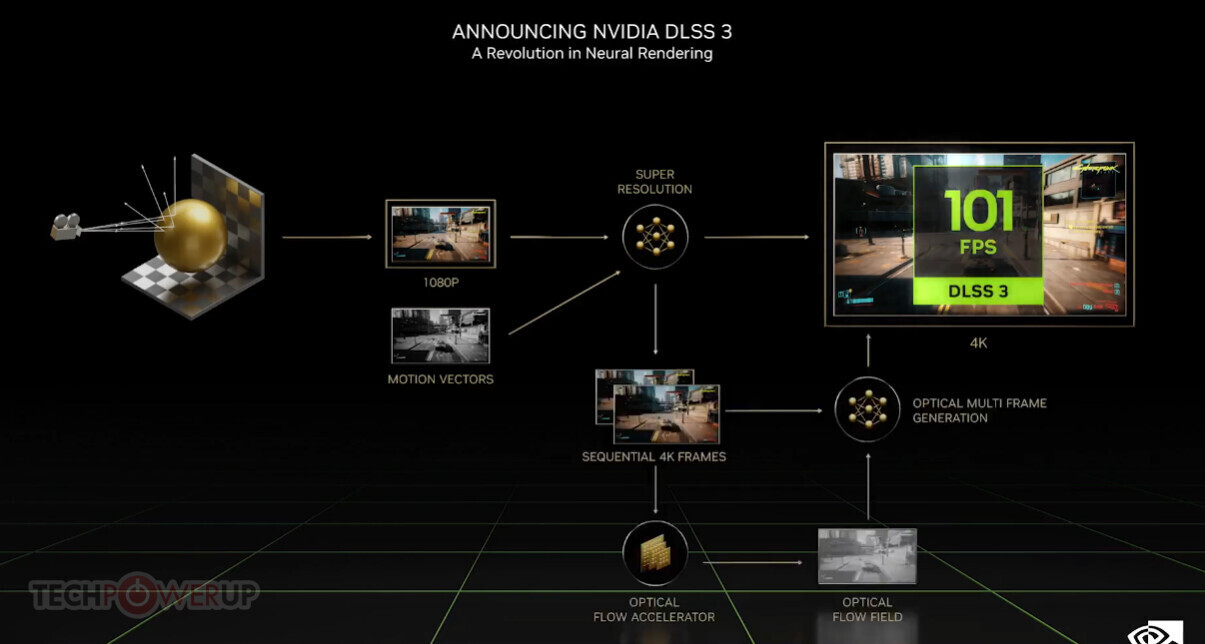
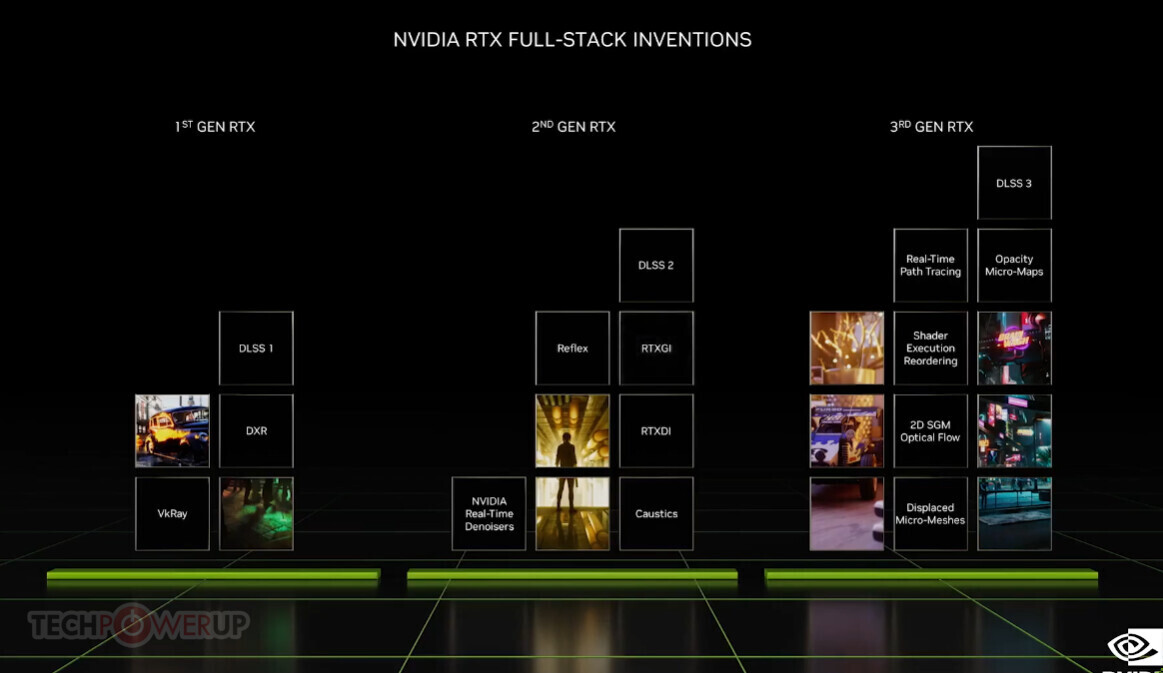
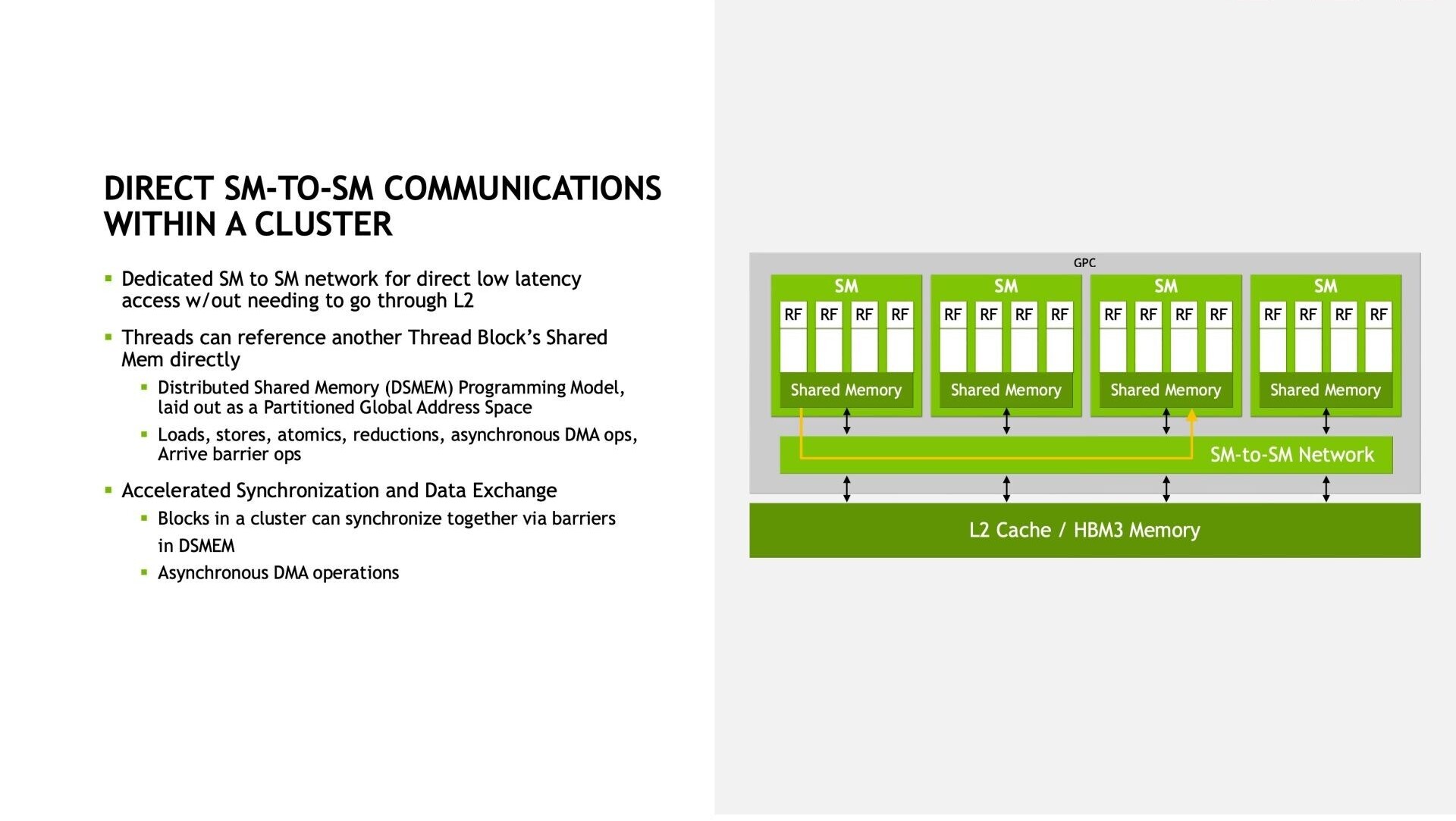
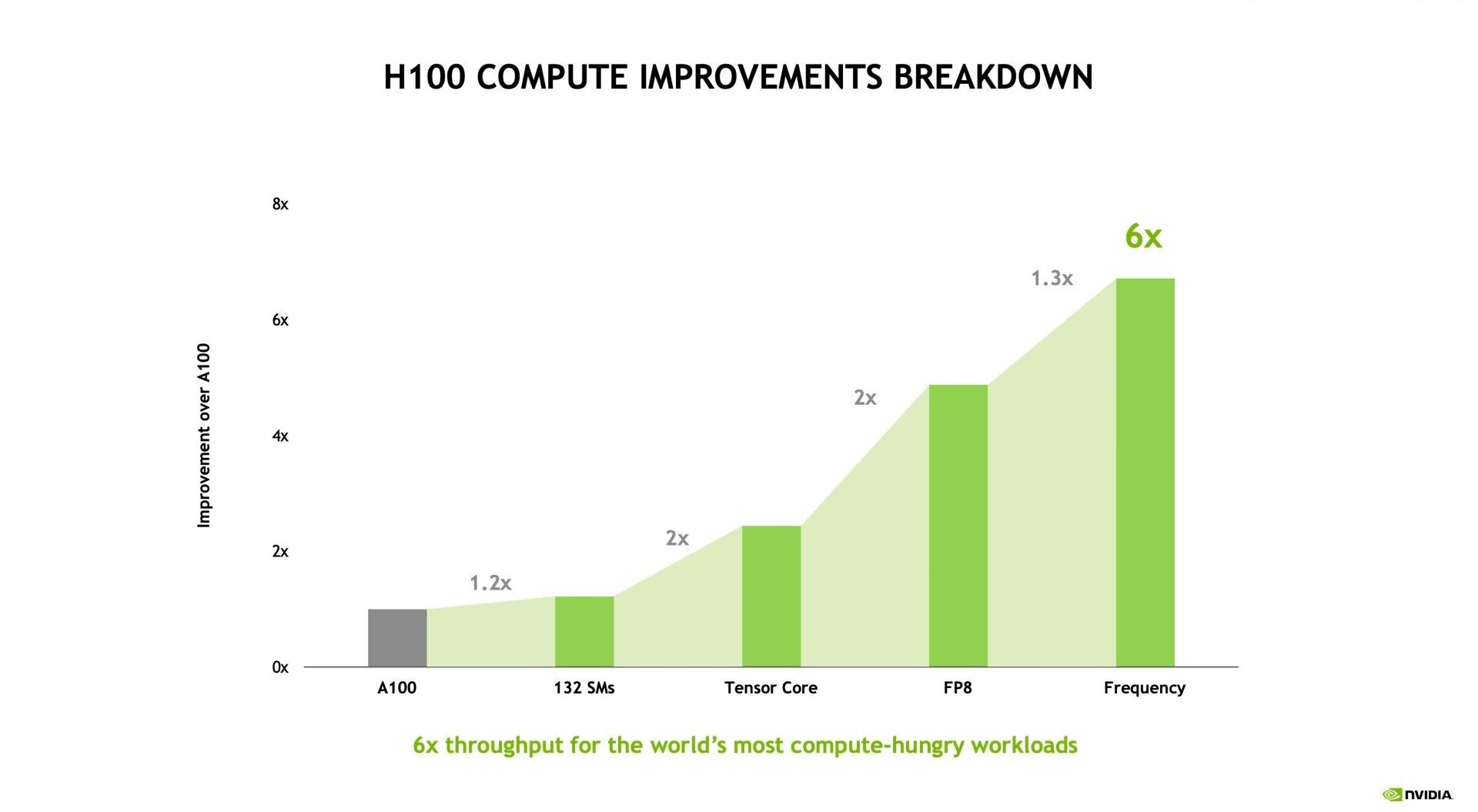
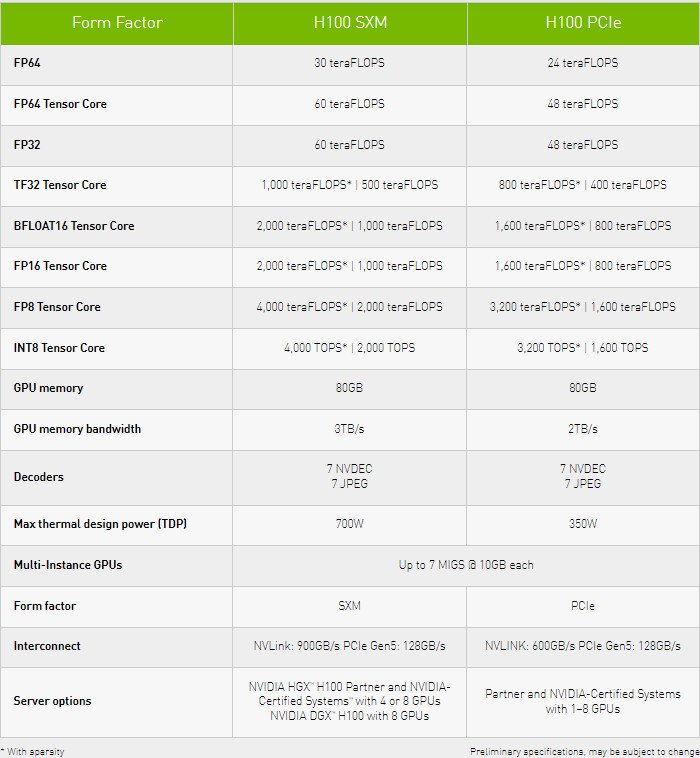
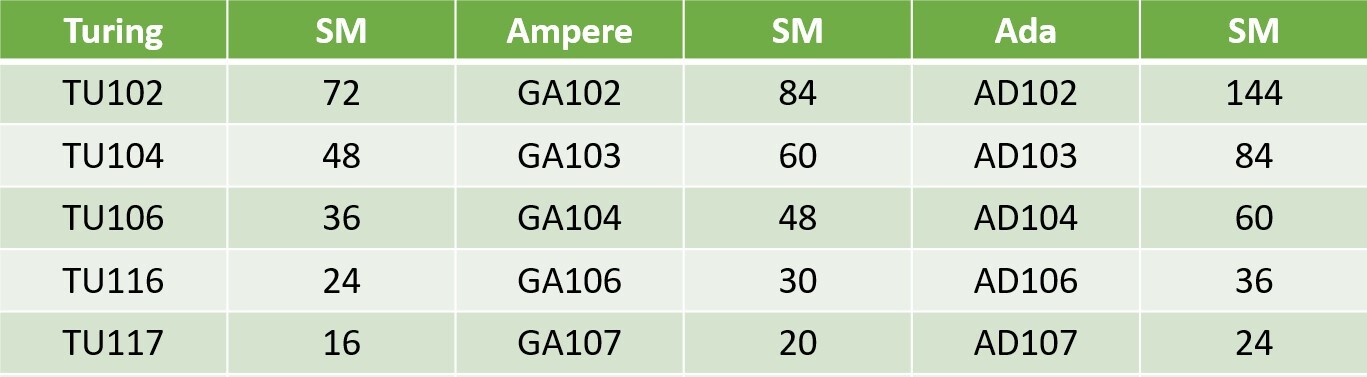
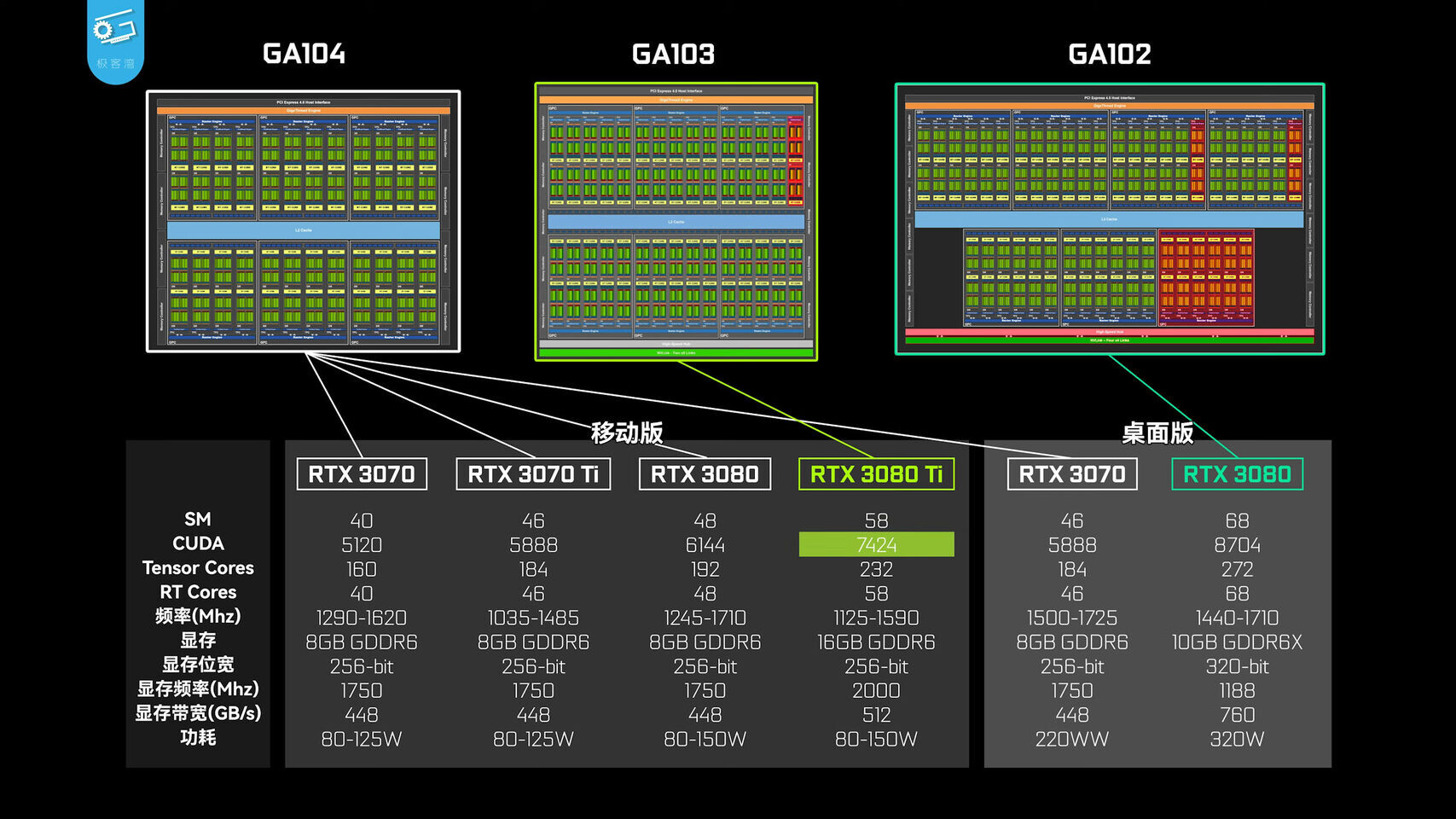
Adlink launches portable GPU accelerator with NVIDIA RTX A500
ADLINK Technology Inc., a global leader in edge computing, today launched Pocket AI - the first ever ultra-portable GPU accelerator to offer exceptional power at a cost-effective price point. With hardware and software compatibility, Pocket AI is the perfect tool to boost performance and productivity. It provides plug-and-play scalability from development to deployment for AI developers, professional graphics users and embedded industrial applications.
Pocket AI is a simple, reliable route to impressive GPU acceleration at a fraction of the cost of a laptop with equivalent GPU power. Its many benefits include a perfect power/performance balance from the NVIDIA RTX A500 GPU; high functionality driven by NVIDIA CUDA X and accelerated libraries; quick, easy delivery/power via Thunderbolt 3 interface and USB PD; and compatibility supported by NVIDIA developer tools. For the ultimate portability, the Pocket AI is compact and lightweight - est. 106 x 72 x 25 mm and 250 grams.

Pocket AI is a simple, reliable route to impressive GPU acceleration at a fraction of the cost of a laptop with equivalent GPU power. Its many benefits include a perfect power/performance balance from the NVIDIA RTX A500 GPU; high functionality driven by NVIDIA CUDA X and accelerated libraries; quick, easy delivery/power via Thunderbolt 3 interface and USB PD; and compatibility supported by NVIDIA developer tools. For the ultimate portability, the Pocket AI is compact and lightweight - est. 106 x 72 x 25 mm and 250 grams.