NVIDIA GeForce RTX 3080 Ti Landing in January at $999
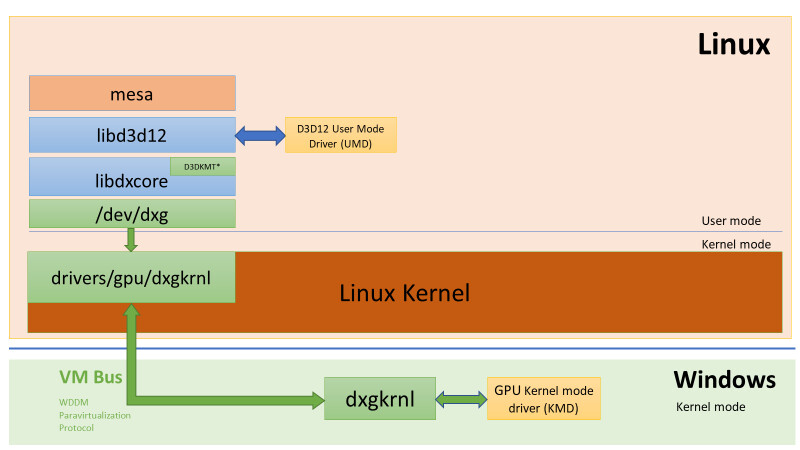
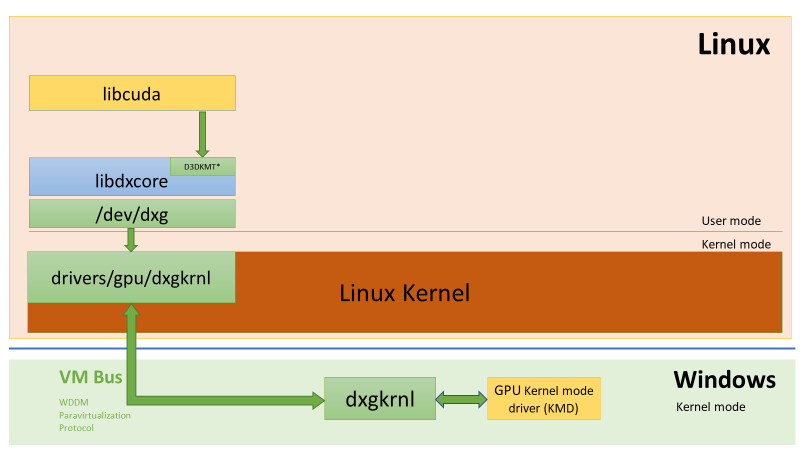
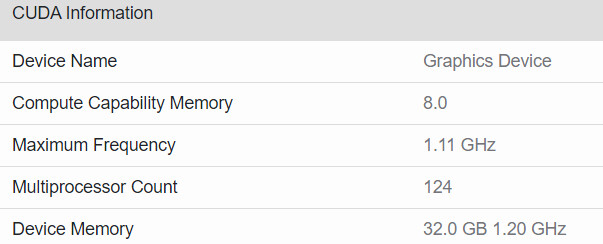
According to the unknown manufacturer (AIB) based in Taiwan, NVIDIA is preparing to launch the new GeForce RTX 3000 series "Ampere" graphics card. As reported by the HKEPC website, the Santa Clara-based company is preparing to fill the gap between its top-end GeForce RTX 3090 and a bit slower RTX 3080 graphics card. The new product will be called GeForce RTX 3080 Ti. If you are wondering what the specification of the new graphics card will look like, you are in luck because the source has a few pieces of information. The new product will be based on GA102-250-KD-A1 GPU core, with a PG133-SKU15 PCB design scheme. The GPU will contain the same 10496 CUDA core configuration as the RTX 3090.
The only difference to the RTX 3090 will be a reduced GDDR6X amount of 20 GB. Along with the 20 GB of GDDR6X memory, the RTX 3080 Ti graphics cards will feature a 320-bit bus. The TGP of the card is limited to 320 Watts. The sources are reporting that the card will be launched sometime in January of 2021, and it will come at $999. This puts the price category of the RTX 3080 Ti in the same range as AMD's recently launched Radeon RX 6900 XT graphics card, so it will be interesting to see how these two products are competing.
The only difference to the RTX 3090 will be a reduced GDDR6X amount of 20 GB. Along with the 20 GB of GDDR6X memory, the RTX 3080 Ti graphics cards will feature a 320-bit bus. The TGP of the card is limited to 320 Watts. The sources are reporting that the card will be launched sometime in January of 2021, and it will come at $999. This puts the price category of the RTX 3080 Ti in the same range as AMD's recently launched Radeon RX 6900 XT graphics card, so it will be interesting to see how these two products are competing.