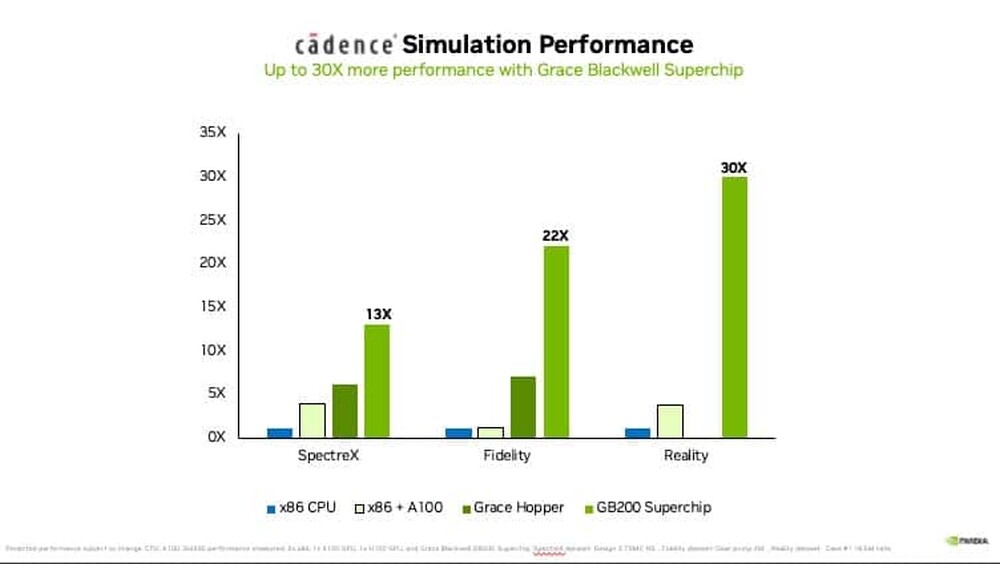
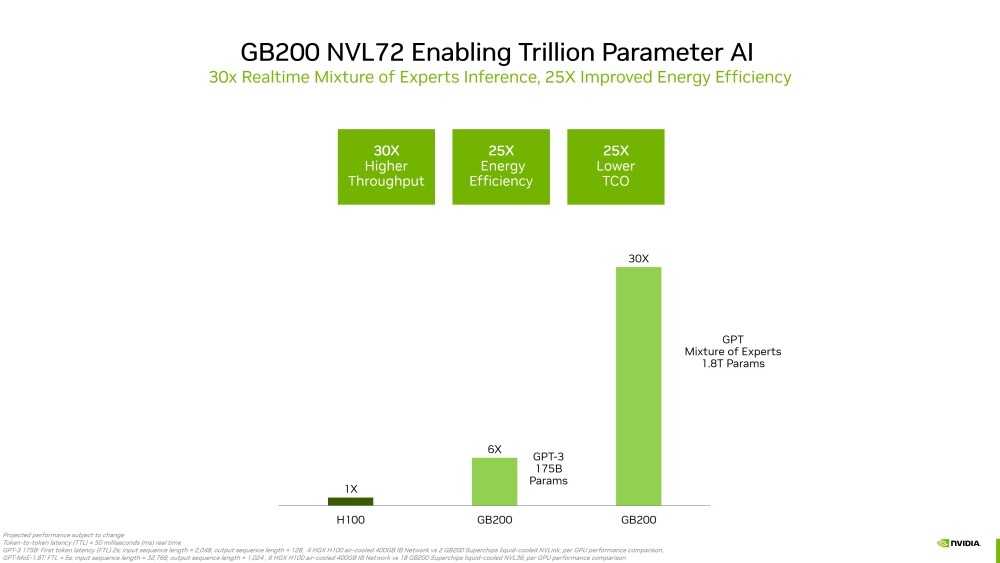
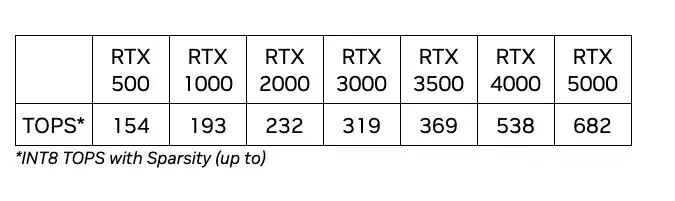
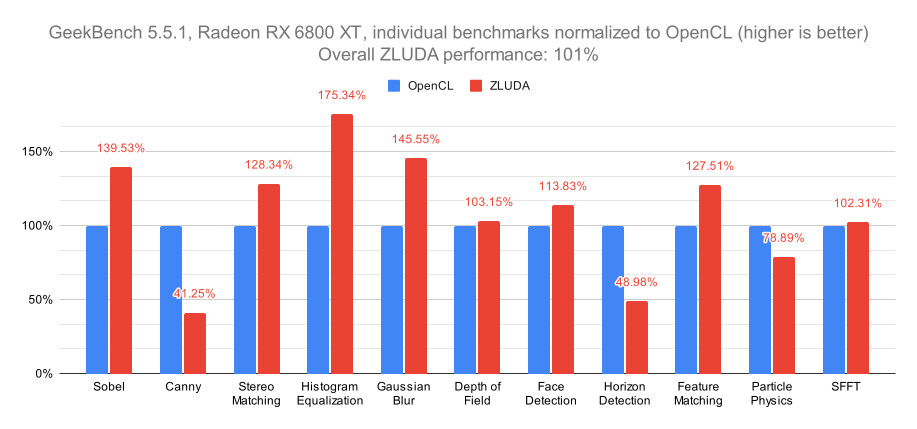
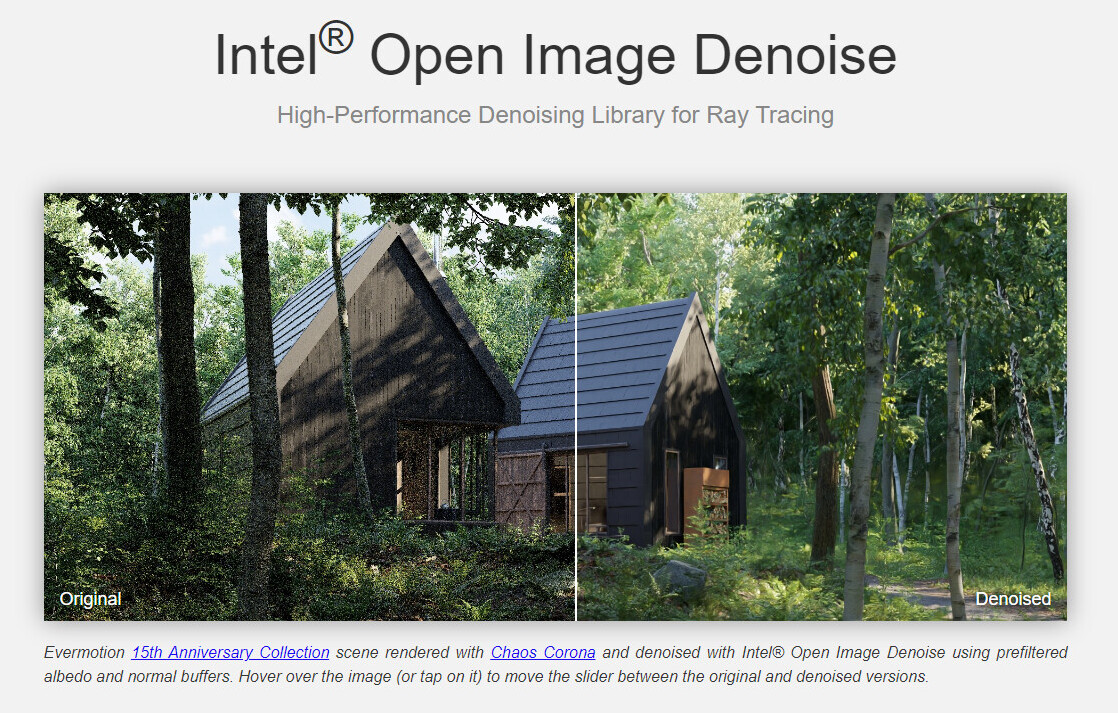
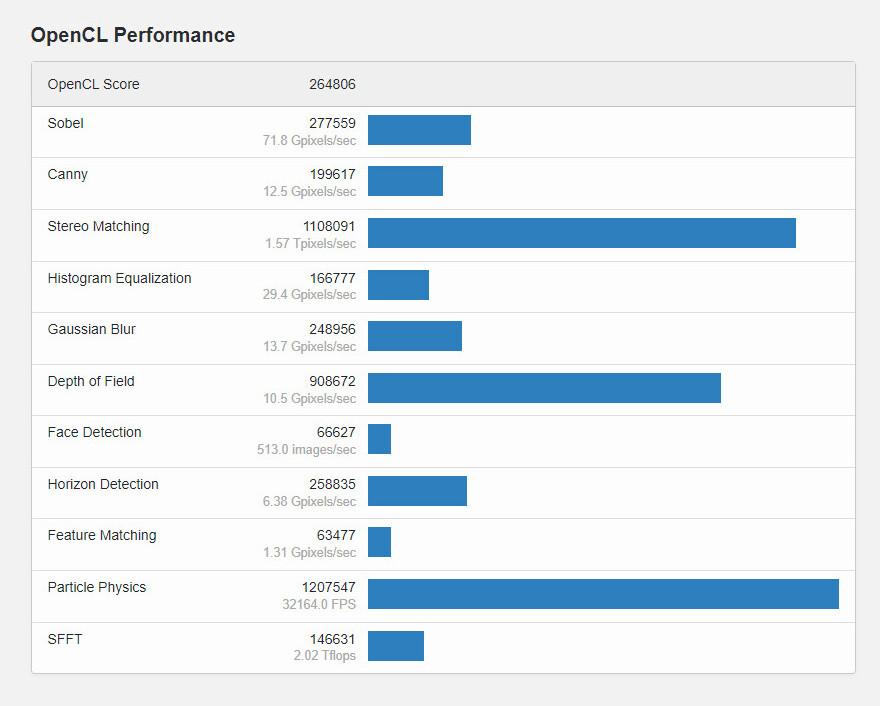
Interview with AMD's Senior Vice President and Chief Software Officer Andrej Zdravkovic: UDNA, ROCm for Radeon, AI Everywhere, and Much More!
A few days ago, we reported on AMD's newest expansion plans for Serbia. The company opened two new engineering design centers with offices in Belgrade and Nis. We were invited to join the opening ceremony and got an exclusive interview with one of AMD's top executives, Andrej Zdravkovic, who is the senior vice president and Chief Software Officer. Previously, we reported on AMD's transition to become a software company. The company has recently tripled its software engineering workforce and is moving some of its best people to support these teams. AMD's plan is spread over a three to five-year timeframe to improve its software ecosystem, accelerating hardware development to launch new products more frequently and to react to changes in software demand. AMD found that to help these expansion efforts, opening new design centers in Serbia would be very advantageous.
We sat down with Andrej Zdravkovic to discuss the purpose of AMD's establishment in Serbia and the future of some products. Zdravkovic is actually an engineer from Serbia, where he completed his Bachelor's and Master's degrees in electrical engineering from Belgrade University. In 1998, Zdravkovic joined ATI and quickly rose through the ranks, eventually becoming a senior director. During his decade-long tenure, Zdravkovic witnessed a significant industry shift as AMD acquired ATI in 2006. After a brief stint at another company, Zdravkovic returned to AMD in 2015, bringing with him a wealth of experience and a unique perspective on the evolution of the graphics and computing industry.


 Here is the full interview:
Here is the full interview:
We sat down with Andrej Zdravkovic to discuss the purpose of AMD's establishment in Serbia and the future of some products. Zdravkovic is actually an engineer from Serbia, where he completed his Bachelor's and Master's degrees in electrical engineering from Belgrade University. In 1998, Zdravkovic joined ATI and quickly rose through the ranks, eventually becoming a senior director. During his decade-long tenure, Zdravkovic witnessed a significant industry shift as AMD acquired ATI in 2006. After a brief stint at another company, Zdravkovic returned to AMD in 2015, bringing with him a wealth of experience and a unique perspective on the evolution of the graphics and computing industry.