Samsung Unveils Far-Reaching, Next-Generation Memory Solutions at FMS 2022
Samsung Electronics, the world leader in advanced memory technology, today unveiled an array of next-generation memory and storage technologies during Flash Memory Summit 2022, held at the Santa Clara (California) Convention Center, Aug. 2-4. In a keynote titled "Memory Innovations Navigating the Big Data Era," Samsung spotlighted four areas of technological advancement driving the big data market—data movement, data storage, data processing and data management—and revealed its leading-edge memory solutions addressing each field.
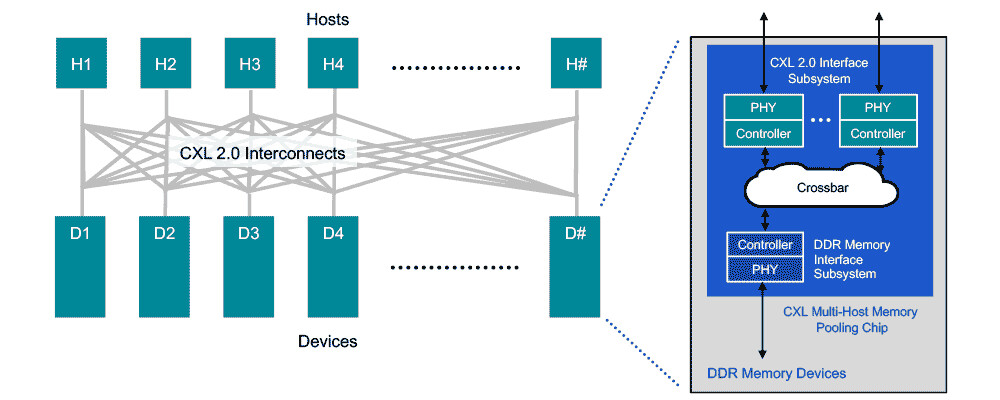
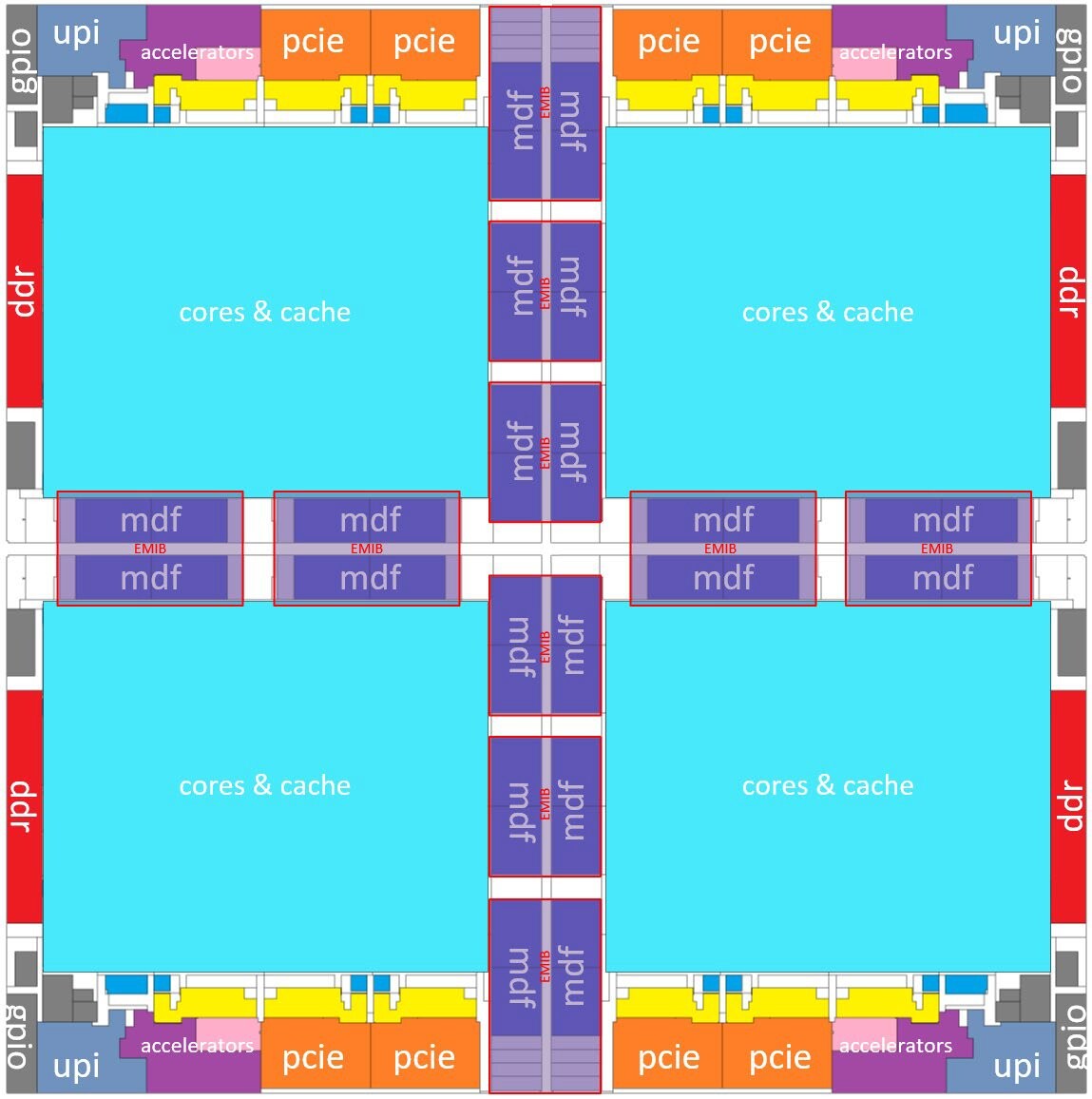
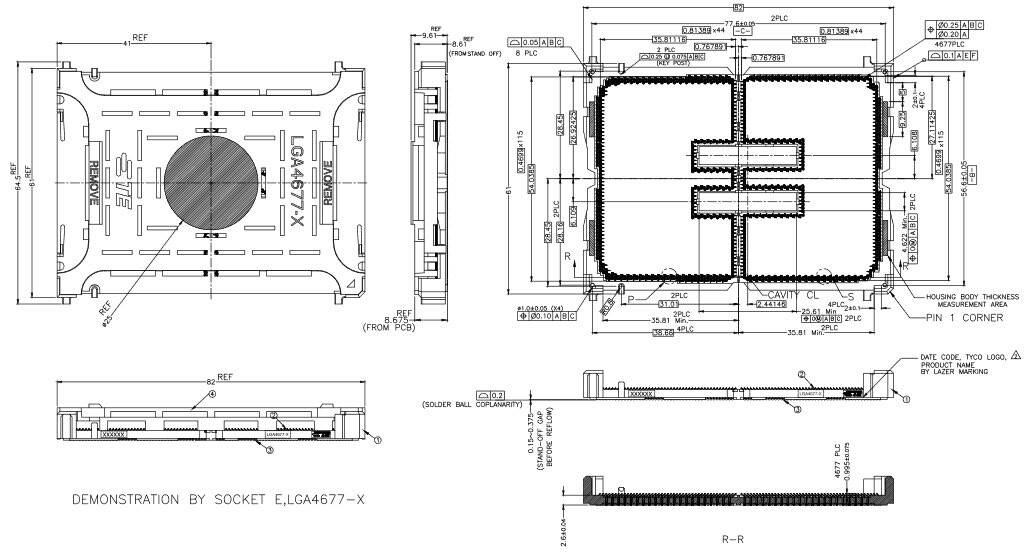
To maximize data center efficiency in an increasingly data-driven world, Samsung introduced a next-generation storage technology, "Petabyte Storage." The new solution will allow a single server unit to pack more than one petabyte of storage, enabling server manufacturers to sharply increase their storage capacity within the same floor space with a minimal number of servers. High server utilization will also help to lower power consumption.

To maximize data center efficiency in an increasingly data-driven world, Samsung introduced a next-generation storage technology, "Petabyte Storage." The new solution will allow a single server unit to pack more than one petabyte of storage, enabling server manufacturers to sharply increase their storage capacity within the same floor space with a minimal number of servers. High server utilization will also help to lower power consumption.