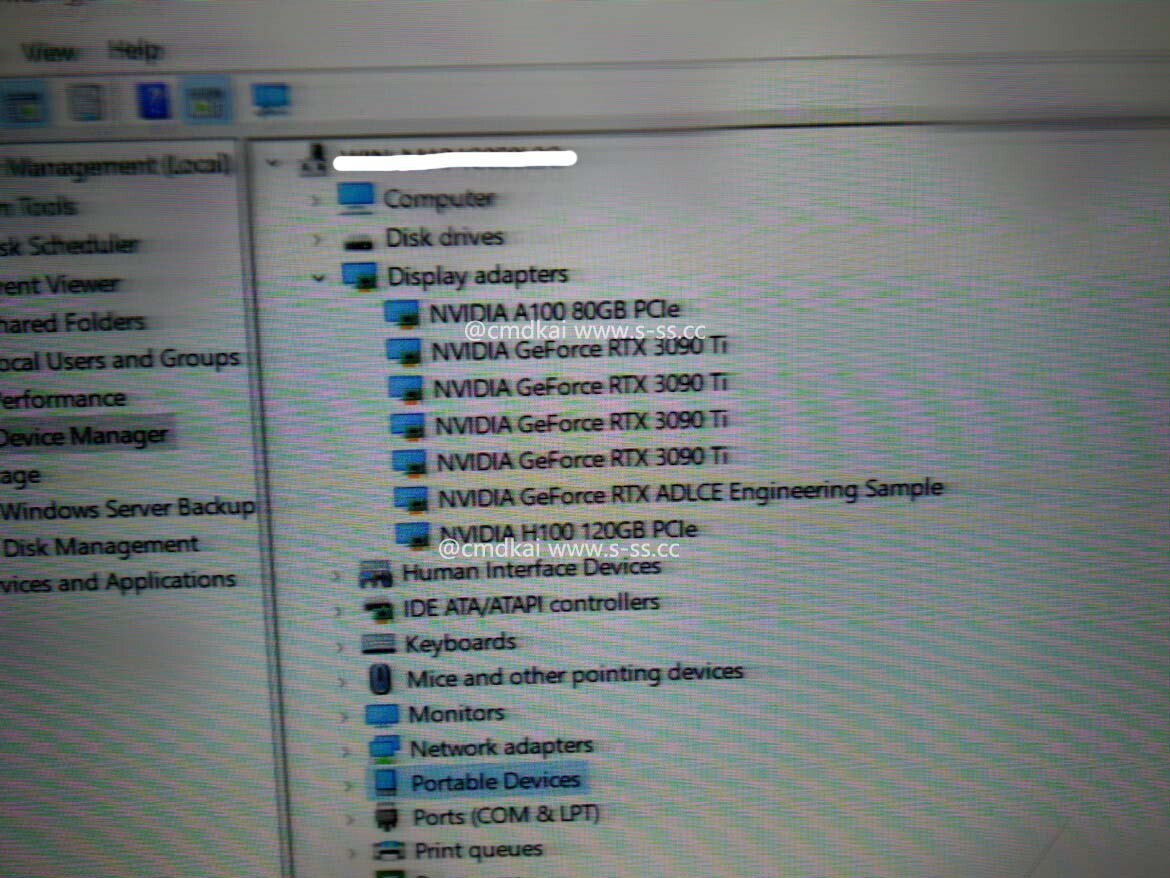
HBM Supply Leader SK Hynix's Market Share to Exceed 50% in 2023 Due to Demand for AI Servers
A strong growth in AI server shipments has driven demand for high bandwidth memory (HBM). TrendForce reports that the top three HBM suppliers in 2022 were SK hynix, Samsung, and Micron, with 50%, 40%, and 10% market share, respectively. Furthermore, the specifications of high-end AI GPUs designed for deep learning have led to HBM product iteration. To prepare for the launch of NVIDIA H100 and AMD MI300 in 2H23, all three major suppliers are planning for the mass production of HBM3 products. At present, SK hynix is the only supplier that mass produces HBM3 products, and as a result, is projected to increase its market share to 53% as more customers adopt HBM3. Samsung and Micron are expected to start mass production sometime towards the end of this year or early 2024, with HBM market shares of 38% and 9%, respectively.
AI server shipment volume expected to increase by 15.4% in 2023
NVIDIA's DM/ML AI servers are equipped with an average of four or eight high-end graphics cards and two mainstream x86 server CPUs. These servers are primarily used by top US cloud services providers such as Google, AWS, Meta, and Microsoft. TrendForce analysis indicates that the shipment volume of servers with high-end GPGPUs is expected to increase by around 9% in 2022, with approximately 80% of these shipments concentrated in eight major cloud service providers in China and the US. Looking ahead to 2023, Microsoft, Meta, Baidu, and ByteDance will launch generative AI products and services, further boosting AI server shipments. It is estimated that the shipment volume of AI servers will increase by 15.4% this year, and a 12.2% CAGR for AI server shipments is projected from 2023 to 2027.
AI server shipment volume expected to increase by 15.4% in 2023
NVIDIA's DM/ML AI servers are equipped with an average of four or eight high-end graphics cards and two mainstream x86 server CPUs. These servers are primarily used by top US cloud services providers such as Google, AWS, Meta, and Microsoft. TrendForce analysis indicates that the shipment volume of servers with high-end GPGPUs is expected to increase by around 9% in 2022, with approximately 80% of these shipments concentrated in eight major cloud service providers in China and the US. Looking ahead to 2023, Microsoft, Meta, Baidu, and ByteDance will launch generative AI products and services, further boosting AI server shipments. It is estimated that the shipment volume of AI servers will increase by 15.4% this year, and a 12.2% CAGR for AI server shipments is projected from 2023 to 2027.