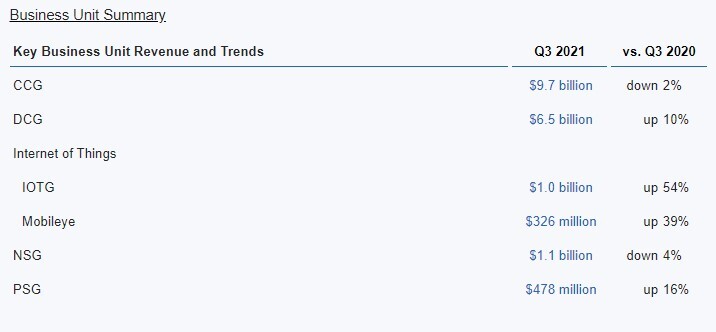Intel Reports Third-Quarter 2021 Financial Results
Intel Corporation today reported third-quarter 2021 financial results. "Q3 shone an even greater spotlight on the global demand for semiconductors, where Intel has the unique breadth and scale to lead. Our focus on execution continued as we started delivering on our IDM 2.0 commitments. We broke ground on new fabs, shared our accelerated path to regain process performance leadership, and unveiled our most dramatic architectural innovations in a decade. We also announced major customer wins across every part of our business," said Pat Gelsinger, Intel CEO. "We are still in the early stages of our journey, but I see the enormous opportunity ahead, and I couldn't be prouder of the progress we are making towards that opportunity."
In the third quarter, the company generated $9.9 billion in cash from operations and paid dividends of $1.4 billion. Intel CFO George Davis announced plans to retire from Intel in May 2022. He will continue to serve in his current role while Intel conducts a search for a new CFO and until his successor is appointed. Third-quarter revenue was led by strong recovery in the Enterprise portion of DCG and in IOTG, which saw higher demand amid recovery from the economic impacts of COVID-19. The Client Computing Group (CCG) was down due to lower notebook volumes due to industry-wide component shortages, and on lower adjacent revenue, partially offset by higher average selling prices (ASPs) and strength in desktop.


In the third quarter, the company generated $9.9 billion in cash from operations and paid dividends of $1.4 billion. Intel CFO George Davis announced plans to retire from Intel in May 2022. He will continue to serve in his current role while Intel conducts a search for a new CFO and until his successor is appointed. Third-quarter revenue was led by strong recovery in the Enterprise portion of DCG and in IOTG, which saw higher demand amid recovery from the economic impacts of COVID-19. The Client Computing Group (CCG) was down due to lower notebook volumes due to industry-wide component shortages, and on lower adjacent revenue, partially offset by higher average selling prices (ASPs) and strength in desktop.