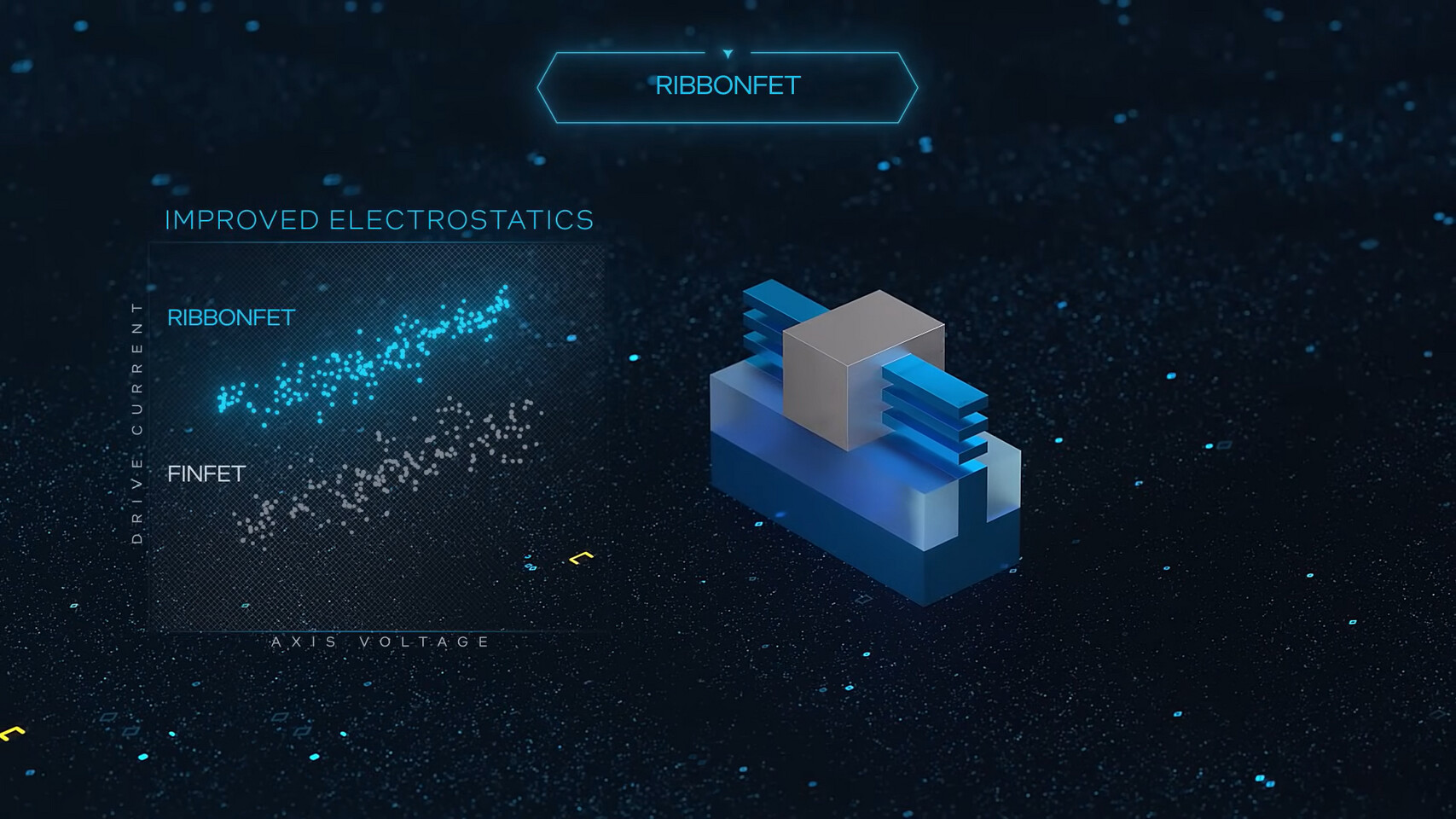
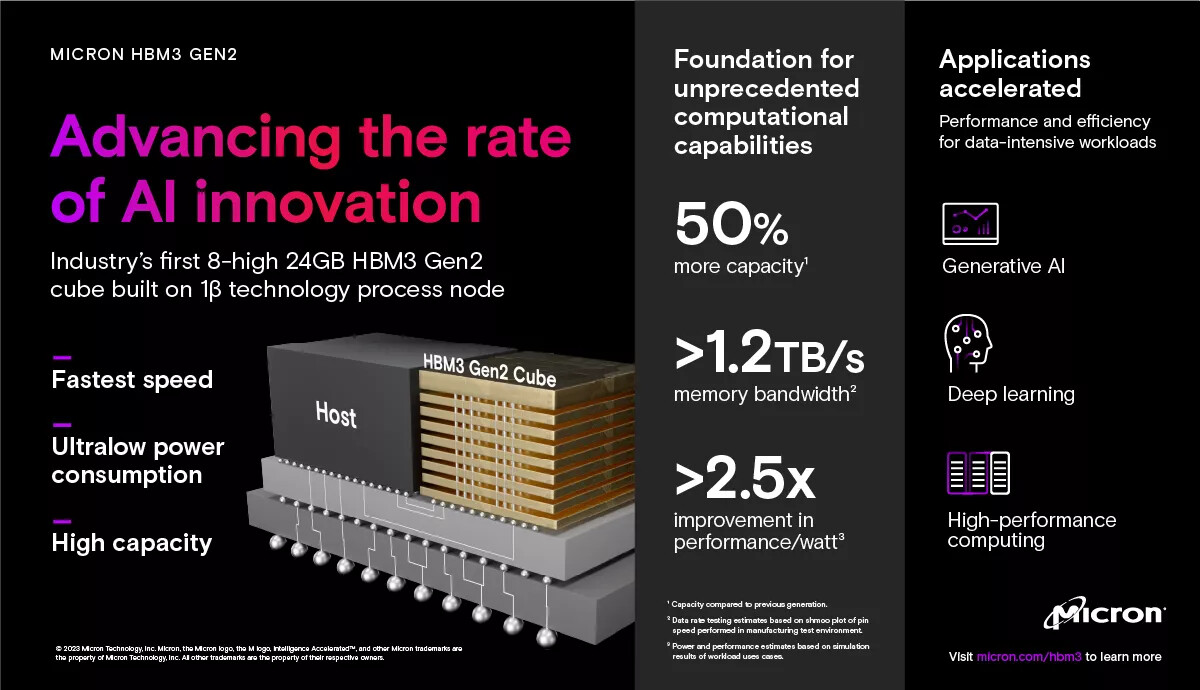
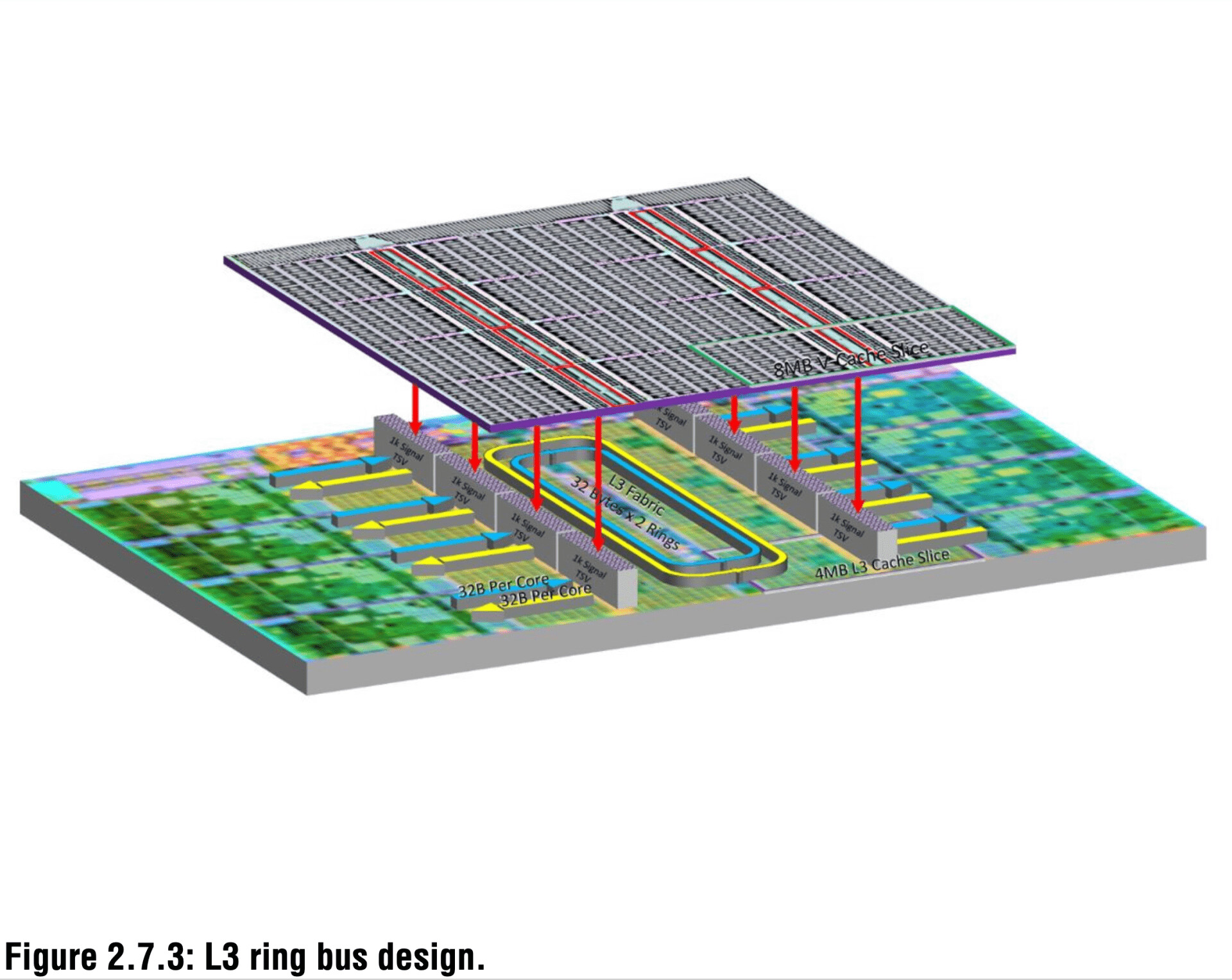
Intel Reportedly Preparing HBM Alternative for AI Accelerators
Demand for AI accelerators has surged in recent years, putting pressure on suppliers to deliver more high-bandwidth memory to enable faster training and higher token throughput in inference. In response, Intel, SoftBank, and the University of Tokyo have quietly formed a new startup called "Saimemory" to develop an alternative to existing HBM solutions, by also using stacked DRAM. According to sources close to the effort, prototype chips are slated for 2027, with volume production aimed at 2030. The venture will combine Intel's extensive chip design experience with novel memory patents from the University of Tokyo, while SoftBank has pledged approximately ¥3 billion (approximately $21 million) to fund the research. Riken Research Institute and Shinko Electric Industries may also join as investors or technical partners, and the team plans to seek government support to accelerate development.
Traditional HBM relies on through-silicon vias (TSVs) to link multiple DRAM dies and uses a wide-bus interposer to achieve data rates above 1 TB/s. Saimemory's design reorganizes signal routing and refresh management to improve energy efficiency, latency, and performance. As readers may recall, there have been past efforts to introduce a rival stacked DRAM technology, but it has not been successful. For example, the Hybrid Memory Cube (HMC), co-developed by Samsung and Micron Technology around 2011, promised speeds up to fifteen times that of DDR3. Despite initial industry backing through the Hybrid Memory Cube Consortium, Micron discontinued HMC production in 2018 after it failed to gain market adoption. HMC's decline shows the challenge of displacing hard-rooted memory standards like HBM. If the Saimemory succeeds, Intel will likely be the first adopter with its upcoming AI accelerators. Others, such as AMD and NVIDIA, could also be approached by the consortium to get a trial chip. Still, the feasibility of mass deployment will largely depend on availability and yields.
Traditional HBM relies on through-silicon vias (TSVs) to link multiple DRAM dies and uses a wide-bus interposer to achieve data rates above 1 TB/s. Saimemory's design reorganizes signal routing and refresh management to improve energy efficiency, latency, and performance. As readers may recall, there have been past efforts to introduce a rival stacked DRAM technology, but it has not been successful. For example, the Hybrid Memory Cube (HMC), co-developed by Samsung and Micron Technology around 2011, promised speeds up to fifteen times that of DDR3. Despite initial industry backing through the Hybrid Memory Cube Consortium, Micron discontinued HMC production in 2018 after it failed to gain market adoption. HMC's decline shows the challenge of displacing hard-rooted memory standards like HBM. If the Saimemory succeeds, Intel will likely be the first adopter with its upcoming AI accelerators. Others, such as AMD and NVIDIA, could also be approached by the consortium to get a trial chip. Still, the feasibility of mass deployment will largely depend on availability and yields.