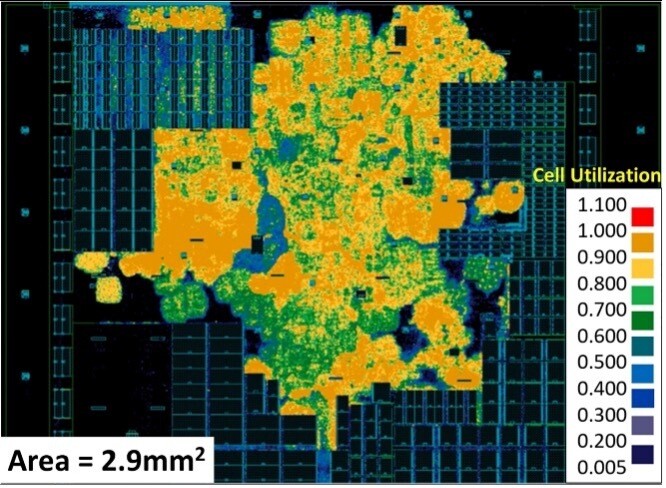
Intel Showcases 18A Node Performance: 25% Faster and 40% Lower Power Draw
Intel's presentation at the VLSI Symposium in Japan offered a detailed look at the upcoming Intel 18A process, which is set to enter mass production in the second half of 2025. This node combines Gate-All-Around transistors with the PowerVia backside power delivery network, resulting in a completely new metal stack architecture. By routing power through the rear of the die, Intel has been able to tighten interconnect pitches on critical layers while relaxing spacing on the top layer, improving yield and simplifying fabrication. In standardized power, performance, and area tests on an Arm core sub-block, Intel 18A demonstrated roughly 15% higher performance at the same power draw compared to Intel 3. When operating at 1.1 volts, clock speeds increase by up to 25% without incurring additional energy costs, and at around 0.75 volts, performance can rise by 18%, or power consumption can drop by nearly 40%.
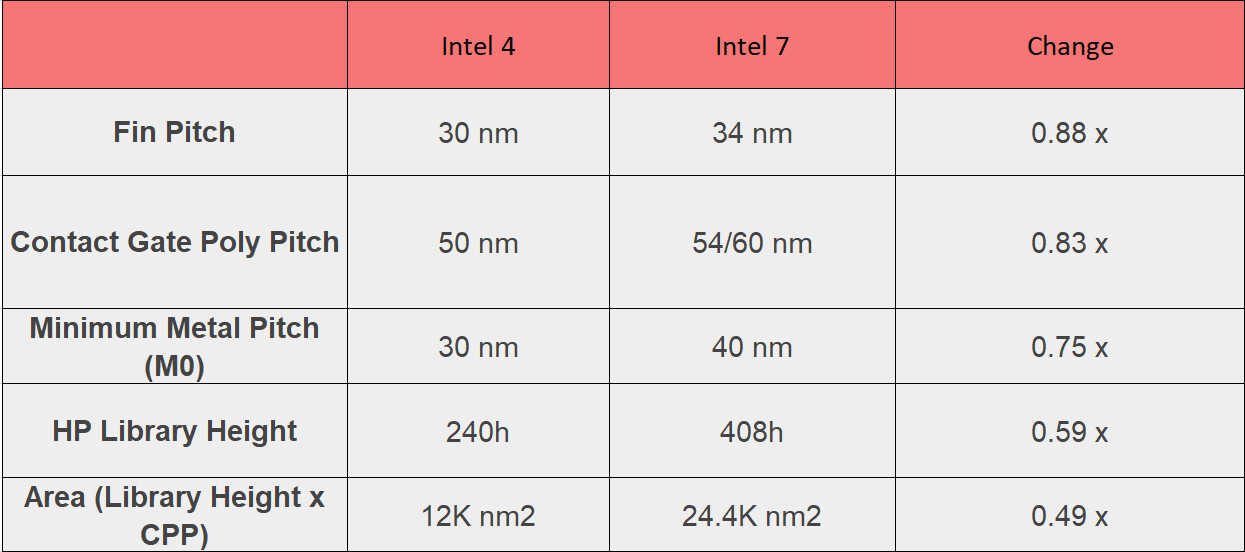
Under the hood, the process features significant cell height reductions: performance‑tuned cells measure 180 nanometers tall, while high‑density designs sit at 160 nanometers, both smaller than their predecessors. The front‑side metal layers have been reduced from between 12 and 19 on Intel 3 to between 11 and 16 on Intel 18A, with three additional rear metal layers added for PowerVia support. Pitches on layers M1 through M10 have been tightened from as much as 60 nanometers down to 32 nanometers before easing again in the upper layers. Low-NA EUV exposure is used on layers M0 through M4, cutting the number of masks required by 44% and simplifying the manufacturing flow. Intel plans to debut 18A in its low‑power "Panther Lake" compute chiplet and the efficiency‑core‑only Clearwater Forest Xeon 7 family. A cost-optimized 17-layer variant, a balanced 21-layer option, and a performance-focused 22-layer configuration will address different market segments.



Under the hood, the process features significant cell height reductions: performance‑tuned cells measure 180 nanometers tall, while high‑density designs sit at 160 nanometers, both smaller than their predecessors. The front‑side metal layers have been reduced from between 12 and 19 on Intel 3 to between 11 and 16 on Intel 18A, with three additional rear metal layers added for PowerVia support. Pitches on layers M1 through M10 have been tightened from as much as 60 nanometers down to 32 nanometers before easing again in the upper layers. Low-NA EUV exposure is used on layers M0 through M4, cutting the number of masks required by 44% and simplifying the manufacturing flow. Intel plans to debut 18A in its low‑power "Panther Lake" compute chiplet and the efficiency‑core‑only Clearwater Forest Xeon 7 family. A cost-optimized 17-layer variant, a balanced 21-layer option, and a performance-focused 22-layer configuration will address different market segments.