Monday, April 11th 2016

NVIDIA "Pascal" GP100 Silicon Detailed
The upcoming "Pascal" GPU architecture from NVIDIA is shaping up to be a pixel-crunching monstrosity. Introduced as more of a number-cruncher in its Tesla P100 unveil at GTC 2016, we got our hands on the block diagram of the "GP100" silicon which drives it. To begin with, the GP100 is a multi-chip module, much like AMD's "Fiji," consisting of a large GPU die, four memory-stacks, and silicon wafer (interposer) acting as substrate for the GPU and memory stacks, letting NVIDIA drive microscopic wires between the two. The GP100 features a 4096-bit wide HBM2 memory interface, with typical memory bandwidths of up to 1 TB/s. On the P100, the memory ticks at 720 GB/s.
At its most top-level hierarchy, the GP100 is structured much like other NVIDIA GPUs, with the exception of two key interfaces - bus and memory. A PCI-Express gen 3.0 x16 host interface connects the GPU to your system, the GigaThread Engine distributes workload between six graphics processing clusters (GPCs). Eight memory controllers make up the 4096-bit wide HBM2 memory interface, and a new "High-speed Hub" component, wires out four NVLink ports. At this point it's not known if each port has a throughput of 80 GB/s (per-direction), or all four ports put together.
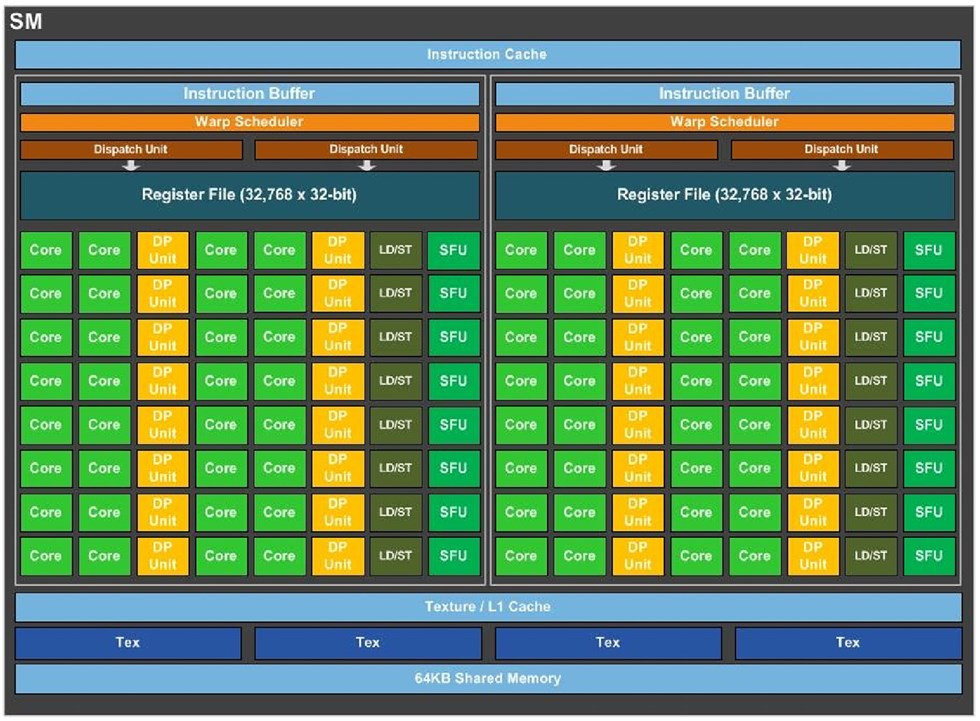
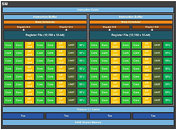 The GP100 features six graphics processing clusters (GPCs). These are highly independent subdivisions of the GPU, with their own render front and back-ends. With the "Pascal" architecture, at least with the way it's implemented on the GP100, each GPC features 10 streaming multiprocessors (SMs), the basic number crunching machinery of the GPU. Each SM holds 64 CUDA cores. The GPC hence holds a total of 640 CUDA cores, and the entire GP100 chip holds 3,840 CUDA cores. Other vital specs include 240 TMUs. On the Tesla P100, NVIDIA enabled just 56 of the 60 streaming multiprocessors, working out to a CUDA core count of 3,584.
The GP100 features six graphics processing clusters (GPCs). These are highly independent subdivisions of the GPU, with their own render front and back-ends. With the "Pascal" architecture, at least with the way it's implemented on the GP100, each GPC features 10 streaming multiprocessors (SMs), the basic number crunching machinery of the GPU. Each SM holds 64 CUDA cores. The GPC hence holds a total of 640 CUDA cores, and the entire GP100 chip holds 3,840 CUDA cores. Other vital specs include 240 TMUs. On the Tesla P100, NVIDIA enabled just 56 of the 60 streaming multiprocessors, working out to a CUDA core count of 3,584.
The "Pascal" architecture appears to facilitate very high clock speeds. The Tesla P100, despite being an enterprise part, features a core clock speed as high as 1328 MHz, with GPU Boost frequency of 1480 MHz, and a TDP of 300W. This might scare you, but you have to take into account that the memory stacks have been moved to the GPU package, and so the heatsink interfacing with it all, will have to cope with the combined thermal loads of the GPU die, the memory stacks, and whatever else makes heat on the multi-chip module.
Lastly, there's the concept of NVLink. This interconnect developed in-house by NVIDIA makes multi-GPU setups work much like a modern multi-socket CPU machine, in which QPI (Intel) or HyperTransport (AMD) links provide super-highways between neighboring sockets. Each NVLink path offers a bandwidth of up to 80 GB/s (per direction), enabling true memory virtualization between multiple GPUs. This could prove useful for GPU-accelerated HPC systems, in which one GPU has to access memory controlled by a neighboring GPU, while the software sees the sum of the two GPUs' memory as one unified and contiguous block. The Pascal Unified Memory system lets advanced GPU programming models like CUDA 8 oversubscribe memory beyond what the GPU physically controls, and up to the system memory.
At its most top-level hierarchy, the GP100 is structured much like other NVIDIA GPUs, with the exception of two key interfaces - bus and memory. A PCI-Express gen 3.0 x16 host interface connects the GPU to your system, the GigaThread Engine distributes workload between six graphics processing clusters (GPCs). Eight memory controllers make up the 4096-bit wide HBM2 memory interface, and a new "High-speed Hub" component, wires out four NVLink ports. At this point it's not known if each port has a throughput of 80 GB/s (per-direction), or all four ports put together.

The "Pascal" architecture appears to facilitate very high clock speeds. The Tesla P100, despite being an enterprise part, features a core clock speed as high as 1328 MHz, with GPU Boost frequency of 1480 MHz, and a TDP of 300W. This might scare you, but you have to take into account that the memory stacks have been moved to the GPU package, and so the heatsink interfacing with it all, will have to cope with the combined thermal loads of the GPU die, the memory stacks, and whatever else makes heat on the multi-chip module.
Lastly, there's the concept of NVLink. This interconnect developed in-house by NVIDIA makes multi-GPU setups work much like a modern multi-socket CPU machine, in which QPI (Intel) or HyperTransport (AMD) links provide super-highways between neighboring sockets. Each NVLink path offers a bandwidth of up to 80 GB/s (per direction), enabling true memory virtualization between multiple GPUs. This could prove useful for GPU-accelerated HPC systems, in which one GPU has to access memory controlled by a neighboring GPU, while the software sees the sum of the two GPUs' memory as one unified and contiguous block. The Pascal Unified Memory system lets advanced GPU programming models like CUDA 8 oversubscribe memory beyond what the GPU physically controls, and up to the system memory.
50 Comments on NVIDIA "Pascal" GP100 Silicon Detailed
- No HBM2 (GDDR5X)
- No NVlink (no functionality on x86, no point otherwise)
- A lower enabled SM count (they will never start with the maximum GP100 can offer, they still need a later release top-end 'ti' version, which means we will see at least two SM's disabled, or more, unless they get really good yields - which is highly unlikely given the maturity of 14/16nm)
- Probably similar or slightly bumped clocks
Also, about positioning of cards, first version GP100 will have a much greater gap with the later version with all SM enabled because the difference will be at least 2 SM's. Nvidia will have a big performance jump up its sleeve, totally different from how they handled things with Kepler and 780ti.
Stop spinning the myth that Nvidia doesn't support async compute, it's a planned feature of CUDA 8 scheduled for June.P100 increased the FP32 performance by 73% over Titan X, 88% over 980 Ti, using only 17% more CUDA cores. That's a pretty impressive increase in IPC.
Game performance doesn't scale linearly with FP32, but we should be able to get 50-60% higher gaming performance on a such chip.We wouldn't see any GP100 based graphics cards anytime soon, GP102 will be the fastest one in a graphics card this year.NVLink is designed for compute workloads, no graphic workload needs it.
As for the whole Async shambles, its not going to be Nvidia's downfall. If people think that's a reality, you need to ease off the red powder you're snorting.
Most likely outcome is very simply Pascal using brute power to deliver the experience.
I don't mind which way it goes, I just hope it goes one way to force the other side to go cheaper.
I think both AMD and NVIDIA are banking on higher IPC + higher clocks. If NVIDIA can manage 1.3 GHz clocks on TSMC where AMD can only manage 800-1000 MHz at GloFo, AMD is going to lose the performance competition; this may be why they're touting performance/watt, not performance. :(
FWIW, the advantages ofGPU point to point bandwidth advances using NVLink have been doing the rounds for the best part of a week since the Quanta and SuperMicro info dropped.
Edit: You seem too eager to take marketing slides as actual real-world gains.
www.hardware.fr/news/14587/gtc-tesla-p100-debits-pcie-nvlink-mesures.html
People constantly needs to be reminded that async shaders is an optional feature of Direct3D 12, and Nvidia so far has prioritized implementing it for CUDA as there really still are no good games on the market to utilize it anyway.
"...Nvidia so far has prioritized implementing it for CUDA..." and that's the problem! Async shaders are a feature of graphics pipeline, not CUDA. CUDA 8 makes no mention of it, nor should it.
Edit: Here's the article: ext3h.makegames.de/DX12_Compute.htmlIf developers start implementing async shaders into their games, they'll always be nerfed on Maxwell and older cards. Backwards compatibility support will be poor because NVIDIA didn't properly implement the feature going into D3D11.
If you recall
Oculus Employees: “Preemption for context switches is best on AMD, Nvidia possibly catastrophic”
They might have improved it. Although The WoZ was dizzy after a few minutes.