Thursday, July 14th 2016

Futuremark Releases 3DMark Time Spy DirectX 12 Benchmark
Futuremark released the latest addition to the 3DMark benchmark suite, the new "Time Spy" benchmark and stress-test. All existing 3DMark Basic and Advanced users have limited access to "Time Spy," existing 3DMark Advanced users have the option of unlocking the full feature-set of "Time Spy" with an upgrade key that's priced at US $9.99. The price of 3DMark Advanced for new users has been revised from its existing $24.99 to $29.99, as new 3DMark Advanced purchases include the fully-unlocked "Time Spy." Futuremark announced limited-period offers that last up till 23rd July, in which the "Time Spy" upgrade key for existing 3DMark Advanced users can be had for $4.99, and the 3DMark Advanced Edition (minus "Time Spy") for $9.99.
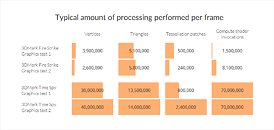
Futuremark 3DMark "Time Spy" has been developed with inputs from AMD, NVIDIA, Intel, and Microsoft, and takes advantage of the new DirectX 12 API. For this reason, the test requires Windows 10. The test almost exponentially increases the 3D processing load over "Fire Strike," by leveraging the low-overhead API features of DirectX 12, to present a graphically intense 3D test-scene that can make any gaming/enthusiast PC of today break a sweat. It can also make use of several beyond-4K display resolutions.
DOWNLOAD: 3DMark with TimeSpy v2.1.2852
Futuremark 3DMark "Time Spy" has been developed with inputs from AMD, NVIDIA, Intel, and Microsoft, and takes advantage of the new DirectX 12 API. For this reason, the test requires Windows 10. The test almost exponentially increases the 3D processing load over "Fire Strike," by leveraging the low-overhead API features of DirectX 12, to present a graphically intense 3D test-scene that can make any gaming/enthusiast PC of today break a sweat. It can also make use of several beyond-4K display resolutions.

91 Comments on Futuremark Releases 3DMark Time Spy DirectX 12 Benchmark
It seems no one has noticed this. AMD cards are not shining like they did in the Vulkan Doom patch, because TimeSpy has very limited use of Async workloads. Nvidia cards show less gain than the AMD cards, and that is with very limited usage. Take the use of Async workloads up to 60-70% per frame and the AMD cards would have dramatic increases, just like in the Vulkan and AotS demos.
Correct me if I am misinterpreting the quote, but in my opinion it appears to me this is why AMD cards are not showing the same dramatic increase we are seeing elsewhere using Async.
JAT
RX480 got potential
s3.amazonaws.com/download-aws.futuremark.com/3DMark_Technical_Guide.pdf
It's also interesting is it uses FL 11_0 for maximum compatibility.
Please note I am not being argumentative, and will happily conceded if it is being "heavily used", but I would like someone to explain how 10-20% workload is considered "heavy". I would assume, like most things, even to be considered "regular" usage would be around 50%.
JAT
For example:And other stuff like particles:Asynchronous compute is therefore fundamental to how the scene is generated and in turn rendered.
The workload is then clearly very high as shown here:
So yeah, basically it's pretty fundamental to the test.
Please explain how a 10-20% async workload is "heavy use". That's seems like a really low workload usage, statistically.
I get that async is the new buzzword word that people cling too, but why do you think it should be 60%+? Clearly workloads can vary from app to app, but what specific compute tasks do you think this benchmark doesn't address?
Are you suggesting this test isn't stressful for modern GPU's?
I am not remotely suggesting that it is not stressful on modern GPUs, but are you saying that 80-90% of all the Compute Units of the GPU are being used 100% of the time during the benchmark, leaving only 10-20% for compute and copy commands over what is being used for 3D rendering commands? I do not believe that is accurate. It simply appears that async commands to the compute units are being under utilized and being limited to particular instructions.
Like I said, maybe I am misinterpreting, but I haven't seen anything showing the contrary. I'm just hoping someone with more knowledge than me can explain it to me.
Like i said workloads can vary drastically on an app by app basis, there doesn't have to be a right or wrong way, what matters is there is another baseline to compare, Futuremark after all claim most of the major parties had input into it's development, and I'd put more credence on them than some random game dev known to have pimped one brand or another in the past.
Their new benchmark doesn't use Async compute in many scenarios where it should be universally usable in any game. My guess is the "input" they received from Nvidia was to do as little with Async as possible as Nvidia cards only support Async through drivers.
We know that proper use of Async yeilds a large advantage for AMD cards. Every game that has utilized it correctly has shown so.
www.tweaktown.com/articles/7785/3dmark-time-spy-dx12-benchmarking-masses/index3.htmlNvidia gained a sizable performance in Doom's Vulkan api benches as well particularly for 1070 and 1080 pascal cards. That's even without nvidia's software version of "async compute".
It's just that maxwell don't really do async compute in any meaningful fashion. (which nVidia said they could improve with a driver update, about 4 months ago).
Also shows how much more superior Vulkan is compare to DX12. Too bad I doubt 3dMark would make a Vulkan api version of time spy.
Maxwell cards gain 0.1% performance increase with async on.
Core feature... Yeah right, dont make me laugh
- The primary purpose of async shaders is to utilize different resources for different purposes simultaneously.
- Rendering and compute does primarily utilize the exact same resources, so an already saturated GPU will only show minor gains.
- The fact that Radeon 200/300/RX400 series shows gains from utilizing the same resources for different tasks is proof that their GPUs are underutilized (which is confirmed by their low performance per GFlop). So it's a problem of their own making, which they have found a way for the game developers to "partially solve". It's a testament to their own inferior architecture, not to Nvidia's "lack of features".
All of this should be obvious. But when you guys can't even be bothered to get the basic understanding of the GPU architectures before you fill the forums with this trash, you have clearly prove yourself unqualified for a technical discussion.
Billy Khan: Yes, async compute will be extensively used on the PC Vulkan version running on AMD hardware. Vulkan allows us to finally code much more to the ;metal'. The thick driver layer is eliminated with Vulkan, which will give significant performance improvements that were not achievable on OpenGL or DX.
www.eurogamer.net/articles/digitalfoundry-2016-doom-tech-interview
- The primary purpose of async shaders is to be able to accept varied instructions from the scheduler for different purposes simultaneously.
- Rendering and compute does primarily utilize the exact same resources, so an already saturated scheduler and pipeline will only show minor gains.
- The fact that Radeon 200/300/RX400 series shows gains from utilizing the same resources for different tasks is proof that their GPU scheduler is able to send more instructions to different shaders than the competition, allowing them to work at full capacity (which is confirmed by their higher performance when using a more efficient API and efficiently coded engine). So it's a solution of their own making, which they have found a way for the game developers to fully utilize. It's a testament to their own architecture that multiple generations are getting substantial gains when the market utilized the given resources correctly.
Now that all of the consoles will be using Compute Units with a scheduler that can make full use of the shaders, I have a feeling most game will start being written to fully utilize them, and NV's arch will have to be reworked to include a larger path for the scheduler. I explained it to my son like this: Imagine a grocery store with a line of people (instructions) waiting to check out, but there is only one cashier (scheduler)...what async does is opens other lanes with more cashiers so that more lines of people can get out of the store faster to their car (shaders). AMD's Aync Compute Engine opens LOTS of lanes, while the NV scheduler opens a few to handle certain lines of people (like the express lane in this analogy).
It appears TimeSpy has limited use of Async, as only certain instructions are being routed through the async scheduler, while most a being routed through the main schedule. 10-20% async workload is not fully utilizing the scheduler of AMDs cards, even 4 generations back.
My 2 Cents.
JAT
If parallelizing two tasks requiring the same resources yields a performance increase, then some resources had to be idling in the first place. Any alternative would be impossible.When they need a bigger 8602 GFlop/s GPU to match a 5632 GFlop/s GPU it's clearly an inefficient archiecture. If AMD scaled as well as Nvidia Fury X would outperform GTX 980 Ti by ~53% and AMD would kick Nvidia's ass.Even with the help of async shaders AMD are still not able to beat Nvidia with or without them. When facing an architecture with is ~50% more efficient it's not going to be enough.
This is why NVidia cards shine so well, APIs today send out instructions in a mostly serial nature, wherein preemption works relatively well...however the new APIs are able to be used with inherently parallel workloads, which causes AMD cards to shine.
Please bear in mind I am not bashing either approach, NV cards are pure muscle, and I love it! but that also comes with a price. AMDs approach to bring that kind of power without needing the brute force approach is good for everyone, and is more cost effective when utilized correctly.