Friday, June 29th 2018

AMD Vega 20 GPU Could Implement PCI-Express gen 4.0
The "Vega 20" silicon will be significantly different from the "Vega 10" which powers the company's current Radeon RX Vega series. AMD CEO Dr. Lisa Su unveiled the "Vega 20" silicon at the company's 2018 Computex event, revealing that the multi-chip module's 7 nm GPU die is surrounded by not two, but four HBM2 memory stacks, making up to 32 GB of memory. Another key specification is emerging thanks to the sharp eyes at ComputerBase.de - system bus.
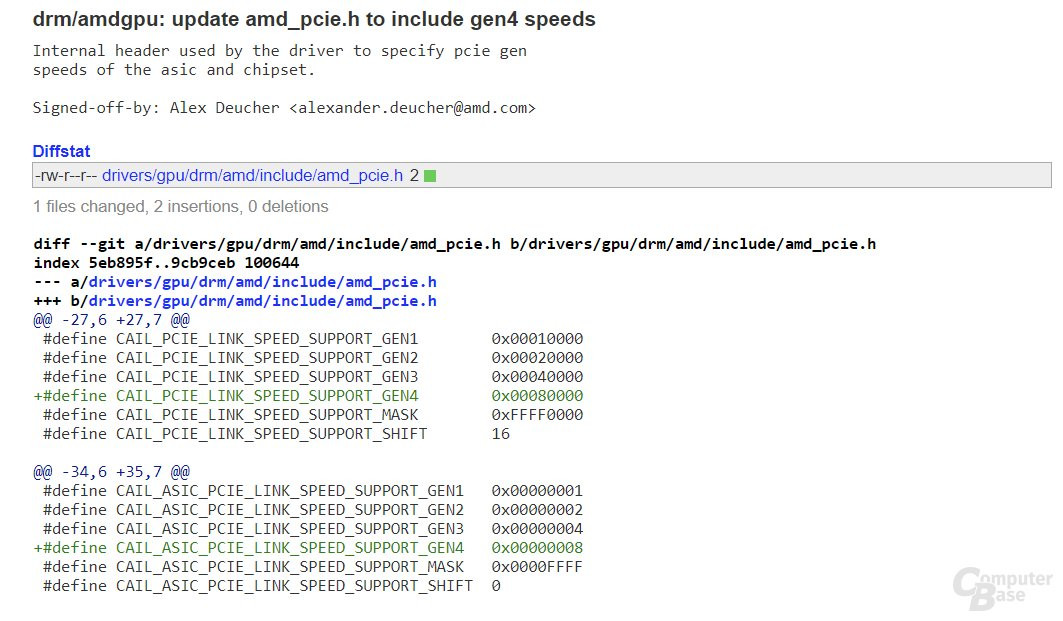
A close inspection of the latest AMDGPU Linux driver includes PCI-Express link speed definitions for PCI-Express gen 4.0, which offers 256 Gbps of bandwidth per direction at x16 bus width, double that of PCI-Express gen 3.0. "Vega 20" got its first PCIe gen 4.0 support confirmation from a leak slide that surfaced around CES 2018. AMD "Vega" architecture slides from last year hinted at a Q3/Q4 launch of the first "Vega 20" based product. The same slide also hinted that the next-generation EPYC processor, which we know are "Zen 2" based and not "Zen+," could feature PCI-Express gen 4.0 root-complexes. Since EPYC chips are multi-chip modules, it could also hint at the likelihood of PCIe gen 4.0 on "Zen 2" based 3rd generation Ryzen processor family.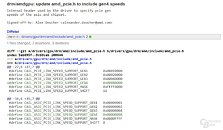
Source:
ComputerBase.de
A close inspection of the latest AMDGPU Linux driver includes PCI-Express link speed definitions for PCI-Express gen 4.0, which offers 256 Gbps of bandwidth per direction at x16 bus width, double that of PCI-Express gen 3.0. "Vega 20" got its first PCIe gen 4.0 support confirmation from a leak slide that surfaced around CES 2018. AMD "Vega" architecture slides from last year hinted at a Q3/Q4 launch of the first "Vega 20" based product. The same slide also hinted that the next-generation EPYC processor, which we know are "Zen 2" based and not "Zen+," could feature PCI-Express gen 4.0 root-complexes. Since EPYC chips are multi-chip modules, it could also hint at the likelihood of PCIe gen 4.0 on "Zen 2" based 3rd generation Ryzen processor family.
26 Comments on AMD Vega 20 GPU Could Implement PCI-Express gen 4.0
No biggie, we've been there before with PCIe 2.0 and 3.0.
What would be really neat would be for the card to run PCIe 4.0 x8 and free up 8 more lanes for NVMe storage.
All i wanna see is good graphical performance for a fair price.
By this time I wouldn't even care if the damn thing consumes 300 watts. We've come to this very reasonable and minimalist request. This is all there's left to ask.
Edit: Phoronix has some benchmarks under Linux of it.
This also makes me think that I should probably put on hold any upgrade plans and wait until motherboards and CPUs with support for PCI 4.0 reach consumer market, for better future proofing...
This only really benefits us the other way round: you can run GPU at x8 and save lanes for other stuff such as storage, which is a real thing these days for us lowly consumers.
The motivation behind the sudden improvement of PCI-E (3.0 was back in 2010) is exactly GPU, but not the gaming part; it is the compute part which finds the PCI-E interface a horrible bottleneck.
PS: I am writing GPU code to accelerate data capture, the PCI-E speed is basically what determines the shortest processing time.
As the numbers are bigger than the competition.
In the real price performanec and heat are pretty average.
How many TFLOPs can even a cheap card handle today, how much bandwidth those cards have, and finally how many GB/s can PCI-E 3.0 pass.
This bandwidth limit does not kill everyone as one could do a lot of operations in GPU, plus for various reason performance does not just scale with TFLOPs, however, in cases like digital down-conversion where vectors are multiplied element-wise, the transfer is the limitation.
And vega 7Nm with 32 GB HBM2 is Designing ONLY for Datacenter and HPC,,, AMD making GPU For datacenter not dekstop,, where your point ??
In the meantime, I think we should cut some slack for those that see GPU and don't automatically think mining, AI and whatnot. In exchange, they (myself included) should be more careful choosing their words.
Can you tell us how much data is transferred between the CPU/GPU through PCIe, by certain applications in your line of work? I'm not talking about theoretical limits, but actual observed data transfers.
Each input will create two output, so the output size will be 1600 MB.
I am still exploring and optimizing it, the best I got is around a few times above of the theoretical limit; I believe there are some overhead.
We want to utilize all 4 channels, and possibly boost the sampling rate to 400 MHz (or higher), so it will be up to 8 times longer than that. As the operations are relatively simple, the operations are mostly bandwidth limited in our case.
The above is the best case scenario, otherwise we could also be limited by sharing of the PCI-E lanes and stuff alike. The time seems short, but comparing to the computation the transfer dominates things here.
A possible solution is to see if the transfer time (as well as small VRAM size) can be solved by using APU (Raven Ridge) where the RAM is shared between the host and the on-die GPU. If this works, that would be a low cost and efficient processor for our application. Also, by using lower precision (half) and doing decimation in the GPU might also help solve the problem.
en.m.wikipedia.org/wiki/Digital_down_converter
To add to the diagram, a raw input vector will be sent to GPU (VRAM), then got multiplied by a sin and cos vector with the same number of points, element-wise.
The two product vectors are then sent back to the host (RAM).
In practice, I tried to use something called DMA transfer which ideally does not read or write the data from host until run-time, and it should reduce overhead and allowed the read/write to happen together.
For DDC itself, more processing like decimation can be done to reduce the output vector we return from GPU to host, but the feeding of the raw input vector cannot be avoided.