Tuesday, April 9th 2019

Intel Reveals the "What" and "Why" of CXL Interconnect, its Answer to NVLink
CXL, short for Compute Express Link, is an ambitious new interconnect technology for removable high-bandwidth devices, such as GPU-based compute accelerators, in a data-center environment. It is designed to overcome many of the technical limitations of PCI-Express, the least of which is bandwidth. Intel sensed that its upcoming family of scalable compute accelerators under the Xe band need a specialized interconnect, which Intel wants to push as the next industry standard. The development of CXL is also triggered by compute accelerator majors NVIDIA and AMD already having similar interconnects of their own, NVLink and InfinityFabric, respectively. At a dedicated event dubbed "Interconnect Day 2019," Intel put out a technical presentation that spelled out the nuts and bolts of CXL.
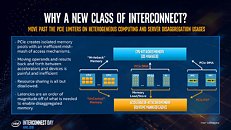
Intel began by describing why the industry needs CXL, and why PCI-Express (PCIe) doesn't suit its use-case. For a client-segment device, PCIe is perfect, since client-segment machines don't have too many devices, too large memory, and the applications don't have a very large memory footprint or scale across multiple machines. PCIe fails big in the data-center, when dealing with multiple bandwidth-hungry devices and vast shared memory pools. Its biggest shortcoming is isolated memory pools for each device, and inefficient access mechanisms. Resource-sharing is almost impossible. Sharing operands and data between multiple devices, such as two GPU accelerators working on a problem, is very inefficient. And lastly, there's latency, lots of it. Latency is the biggest enemy of shared memory pools that span across multiple physical machines. CXL is designed to overcome many of these problems without discarding the best part about PCIe - the simplicity and adaptability of its physical layer.

 CXL uses the PCIe physical layer, and has raw on-paper bandwidth of 32 Gbps per lane, per direction, which aligns with PCIe gen 5.0 standard. The link layer is where all the secret-sauce is. Intel worked on new handshake, auto-negotiation, and transaction protocols replacing those of PCIe, designed to overcome its shortcomings listed above. With PCIe gen 5.0 already standardized by the PCI-SIG, Intel could share CXL IP back to the SIG with PCIe gen 6.0. In other words, Intel admits that CXL may not outlive PCIe, and until the PCI-SIG can standardize gen 6.0 (around 2021-22, if not later), CXL is the need of the hour.
CXL uses the PCIe physical layer, and has raw on-paper bandwidth of 32 Gbps per lane, per direction, which aligns with PCIe gen 5.0 standard. The link layer is where all the secret-sauce is. Intel worked on new handshake, auto-negotiation, and transaction protocols replacing those of PCIe, designed to overcome its shortcomings listed above. With PCIe gen 5.0 already standardized by the PCI-SIG, Intel could share CXL IP back to the SIG with PCIe gen 6.0. In other words, Intel admits that CXL may not outlive PCIe, and until the PCI-SIG can standardize gen 6.0 (around 2021-22, if not later), CXL is the need of the hour.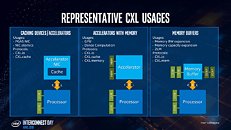
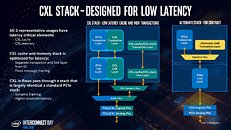
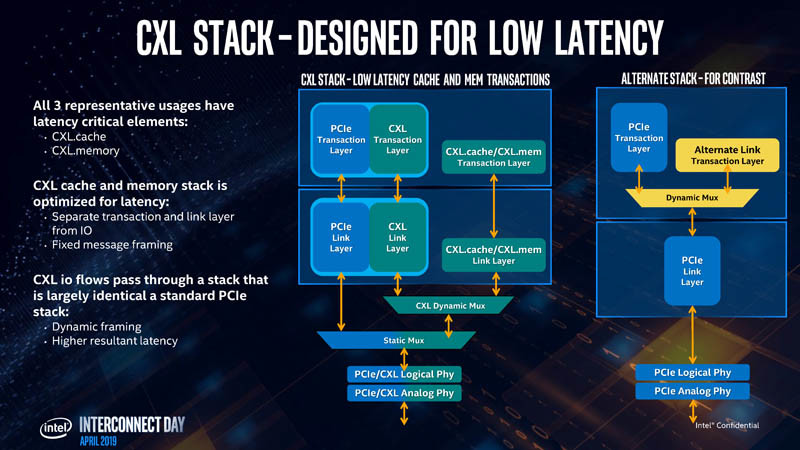
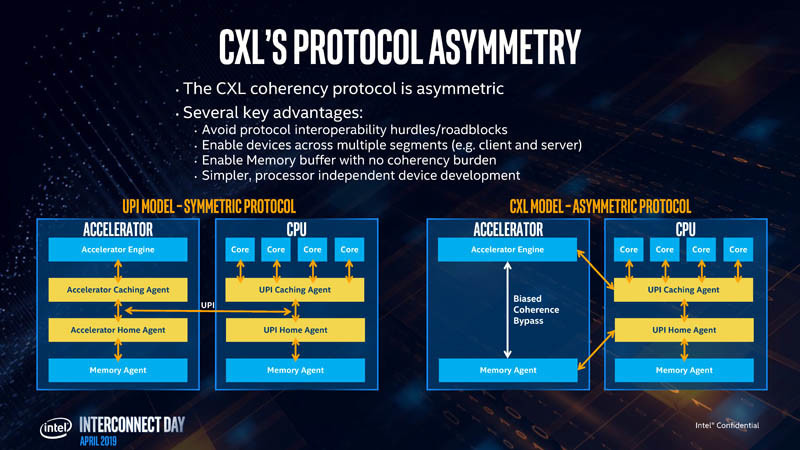
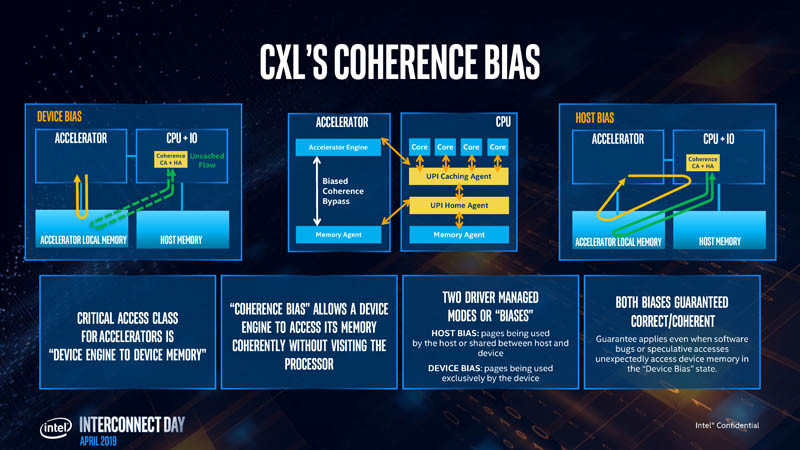
 The CXL transaction layer consists of three multiplexed sub-protocols that run simultaneously on a single link. They are: CXL.io, CXL.cache, and CXL.memory. CXL.io deals with device discovery, link negotiation, interrupts, registry access, etc., which are basically tasks that get a machine to work with a device. CXL.cache deals with the device's access to a local processor's memory. CXL.memory deals with processor's access to non-local memory (memory controlled by another processor or another machine).
The CXL transaction layer consists of three multiplexed sub-protocols that run simultaneously on a single link. They are: CXL.io, CXL.cache, and CXL.memory. CXL.io deals with device discovery, link negotiation, interrupts, registry access, etc., which are basically tasks that get a machine to work with a device. CXL.cache deals with the device's access to a local processor's memory. CXL.memory deals with processor's access to non-local memory (memory controlled by another processor or another machine).


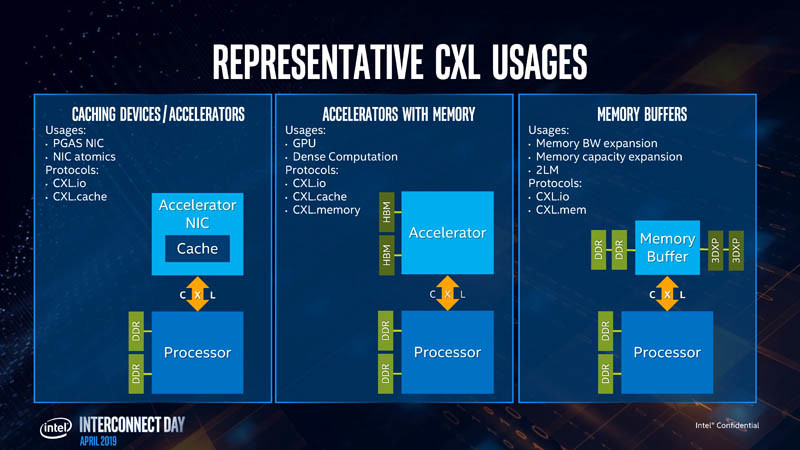
Intel listed out use-cases for CXL, which begins with accelerators with memory, such as graphics cards, GPU compute accelerators, and high-density compute cards. All three CXL transaction layer protocols are relevant to such devices. Next up, are FPGAs, and NICs. CXL.io and CXL.cache are relevant here, since network-stacks are processed by processors local to the NIC. Lastly, there are the all-important memory buffers. You can imagine these devices as "NAS, but with DRAM sticks." Future data-centers will consist of vast memory pools shared between thousands of physical machines and accelerators. CXL.memory and CXL.cache are relevant. Much of what makes the CXL link-layer faster than PCIe is its optimized stack (processing load for the CPU). The CXL stack is built from the ground up keeping low-latency as a design goal.
Source:
Serve the Home
Intel began by describing why the industry needs CXL, and why PCI-Express (PCIe) doesn't suit its use-case. For a client-segment device, PCIe is perfect, since client-segment machines don't have too many devices, too large memory, and the applications don't have a very large memory footprint or scale across multiple machines. PCIe fails big in the data-center, when dealing with multiple bandwidth-hungry devices and vast shared memory pools. Its biggest shortcoming is isolated memory pools for each device, and inefficient access mechanisms. Resource-sharing is almost impossible. Sharing operands and data between multiple devices, such as two GPU accelerators working on a problem, is very inefficient. And lastly, there's latency, lots of it. Latency is the biggest enemy of shared memory pools that span across multiple physical machines. CXL is designed to overcome many of these problems without discarding the best part about PCIe - the simplicity and adaptability of its physical layer.





37 Comments on Intel Reveals the "What" and "Why" of CXL Interconnect, its Answer to NVLink
semiaccurate.com/2019/03/11/intel-releases-compute-express-link-spec/
There have been rumors that Intel intends to skip PCI-Express 4.0 completely.
CXL is a protocol on top of PCI-e 5.0, similarly to CCIX on top of PCI-e 4.0 (at least in the current iteration of it). Whether Intel has something nefarious in mind we will have to wait and see. They make it sound like an evolution of CXL or something similar is something they would like to eventually see in PCI-e 6.0 proper.
What we already have are not exactly optimal for the purpose. Intel does talk about the why they want a new interconnect. Putting this on Intel is a bit strange, as CCIX is quite literally coming from the same points but from AMD, ARM, Qualcomm, Xilinx etc. There are also other interconnects like IF or NVLink.
So if CCIX is so similar, why are they "modifying it" themselves rather than joining the party with everyone else?
I have not had a chance to read the entire CCIX spec (simple search doesn't do it and have not jumped through enough hoops to get the full document) and CXL spec is not public AFAIK. While having their own version of everything is probably part of it, from what has been revealed the solution seems to be somehat different. Intel's approach no doubt is geared or optimized to their specific needs.
So if Intel doesn't get their way this will likely end up as TB, without the USB bailout :rolleyes:
Sounds like Intel wants to make standards that offer little benefits but cost a lot to license.
That's why we "don't need more bandwidth", because latency kills any speed that we could gain from that.
Intel proposing this to be incorporated in PCIe standard is nothing nefarious, since they are already members of the PCI-SIG consortium:
pcisig.com/membership/member-companies?combine=intel
I don't see how this translates into Intel "wanting to get a fee".
As for people that bash Intel just because they feel it's "cool" and they think they "know better"... whatever inflates your ego is fine to be put online, for everyone to see.
CXL, besides Intel, has already gained a lot of support from other big names interested in computing, so put that in perspective:
www.computeexpresslink.org/members
ARM, Google, Cisco, Facebook, alibaba, Dell, HP, Huawei, Lenovo, Microsoft, Microchip... they are all into giving Intel free money???
A standard is as strong as the money behind it and the adoption by industry. Better standard (by al measures) will win.
So oftentimes, when companies decide to go at it by themselves, it's not because they're after your cash (well, they are in the end), but because they need a product out there.