Friday, September 25th 2020
RTX 3080 Crash to Desktop Problems Likely Connected to AIB-Designed Capacitor Choice
Igor's Lab has posted an interesting investigative article where he advances a possible reason for the recent crash to desktop problems for RTX 3080 owners. For one, Igor mentions how the launch timings were much tighter than usual, with NVIDIA AIB partners having much less time than would be adequate to prepare and thoroughly test their designs. One of the reasons this apparently happened was that NVIDIA released the compatible driver stack much later than usual for AIB partners; this meant that their actual testing and QA for produced RTX 3080 graphics cards was mostly limited to power on and voltage stability testing, other than actual gaming/graphics workload testing, which might have allowed for some less-than-stellar chip samples to be employed on some of the companies' OC products (which, with higher operating frequencies and consequent broadband frequency mixtures, hit the apparent 2 GHz frequency wall that produces the crash to desktop).
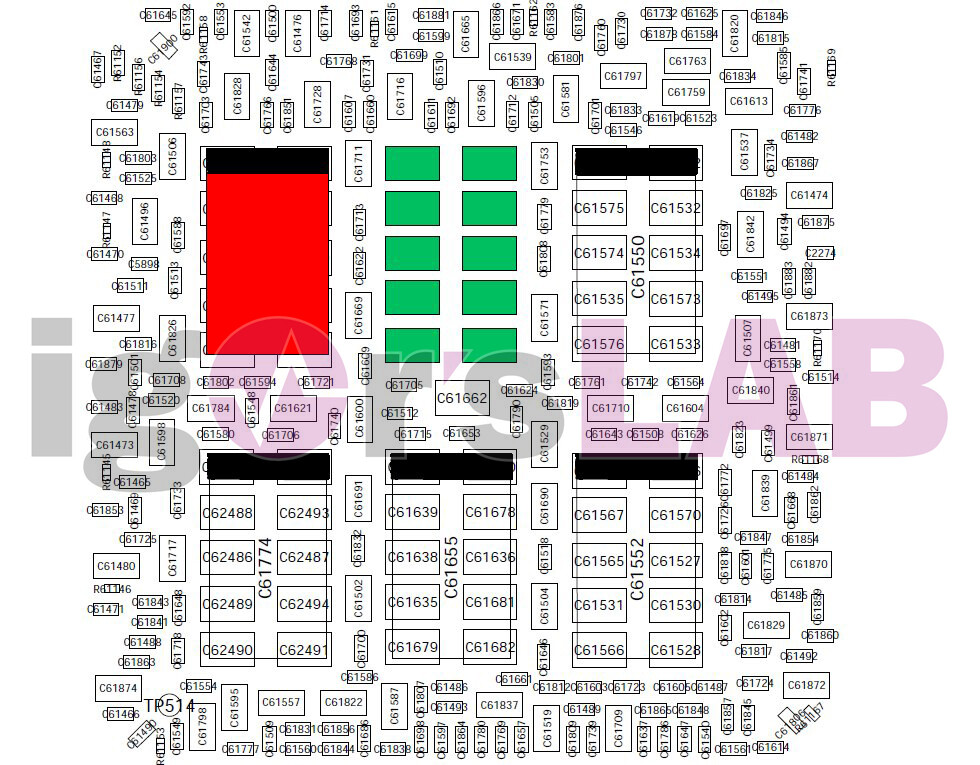
Another reason for this, according to Igor, is the actual "reference board" PG132 design, which is used as a reference, "Base Design" for partners to architecture their custom cards around. The thing here is that apparently NVIDIA's BOM left open choices in terms of power cleanup and regulation in the mounted capacitors. The Base Design features six mandatory capacitors for filtering high frequencies on the voltage rails (NVVDD and MSVDD). There are a number of choices for capacitors to be installed here, with varying levels of capability. POSCAPs (Conductive Polymer Tantalum Solid Capacitors) are generally worse than SP-CAPs (Conductive Polymer-Aluminium-Electrolytic-Capacitors) which are superseded in quality by MLCCs (Multilayer Ceramic Chip Capacitor, which have to be deployed in groups). Below is the circuitry arrangement employed below the BGA array where NVIDIA's GA-102 chip is seated, which corresponds to the central area on the back of the PCB.
 In the images below, you can see how NVIDIA and it's AIBs designed this regulator circuitry (NVIDIA Founders' Edition, MSI Gaming X, ZOTAC Trinity, and ASUS TUF Gaming OC in order, from our reviews' high resolution teardowns). NVIDIA in their Founders' Edition designs uses a hybrid capacitor deployment, with four SP-CAPs and two MLCC groups of 10 individual capacitors each in the center. MSI uses a single MLCC group in the central arrangement, with five SP-CAPs guaranteeing the rest of the cleanup duties. ZOTAC went the cheapest way (which may be one of the reasons their cards are also among the cheapest), with a six POSCAP design (which are worse than MLCCs, remember). ASUS, however, designed their TUF with six MLCC arrangements - there were no savings done in this power circuitry area.
In the images below, you can see how NVIDIA and it's AIBs designed this regulator circuitry (NVIDIA Founders' Edition, MSI Gaming X, ZOTAC Trinity, and ASUS TUF Gaming OC in order, from our reviews' high resolution teardowns). NVIDIA in their Founders' Edition designs uses a hybrid capacitor deployment, with four SP-CAPs and two MLCC groups of 10 individual capacitors each in the center. MSI uses a single MLCC group in the central arrangement, with five SP-CAPs guaranteeing the rest of the cleanup duties. ZOTAC went the cheapest way (which may be one of the reasons their cards are also among the cheapest), with a six POSCAP design (which are worse than MLCCs, remember). ASUS, however, designed their TUF with six MLCC arrangements - there were no savings done in this power circuitry area.



It's likely that the crash to desktop problems are related to both these issues - and this would also justify why some cards cease crashing when underclocked by 50-100 MHz, since at lower frequencies (and this will generally lead boost frequencies to stay below the 2 GHz mark) there is lesser broadband frequency mixture happening, which means POSCAP solutions can do their job - even if just barely.
Source:
Igor's Lab
Another reason for this, according to Igor, is the actual "reference board" PG132 design, which is used as a reference, "Base Design" for partners to architecture their custom cards around. The thing here is that apparently NVIDIA's BOM left open choices in terms of power cleanup and regulation in the mounted capacitors. The Base Design features six mandatory capacitors for filtering high frequencies on the voltage rails (NVVDD and MSVDD). There are a number of choices for capacitors to be installed here, with varying levels of capability. POSCAPs (Conductive Polymer Tantalum Solid Capacitors) are generally worse than SP-CAPs (Conductive Polymer-Aluminium-Electrolytic-Capacitors) which are superseded in quality by MLCCs (Multilayer Ceramic Chip Capacitor, which have to be deployed in groups). Below is the circuitry arrangement employed below the BGA array where NVIDIA's GA-102 chip is seated, which corresponds to the central area on the back of the PCB.





297 Comments on RTX 3080 Crash to Desktop Problems Likely Connected to AIB-Designed Capacitor Choice
The reference spec design they passed AIB was different to their own reference card's.
And they compressed development and testing time to near zero.
And they allowed such design variation in their development reference kit instead of both knowing that it needed specific voltage conditioning and informing AIB partners or limiting those AIB designs.
It's not all on Nvidia but they share the blame.
Most of the time, in this type of situation, the responsibility is shared, but the chances than Nvidia gave very clear and correct specifications and the AIB just blatantly disprespected them are close to 0.
Time will tell, but it looks like we were expecting another Pascal and we got another Fermi... They'll fix it soon, I imagine, if it's just a matter of dropping the frequency a tad should be easily fixable.
This is exactly on Nvidia.:shadedshu:
Dont think I have to look for more informative and unbiased opinion.
For those people who insisted TUF won't crash, I post an evidence video of my TUF crashed.
www.asus.com/us/Graphics-Cards/TUF-RTX3080-10G-GAMING/gallery/
From a PDN perspective, the only thing that matters is the frequencies at which power is drawn. It doesn't matter how NVidia's pipelines or local memory or whatever work. What matters is that they draw power at 2.1GHz increments, generating a 2.1GHz "ring frequency" across the power network... at roughly 100+ Amps.
Which will be roughly:
* 2.1GHz (Clockspeed of GPU)
* 5.25 GHz (rough clockspeed of the GDDR6x)
* 75Hz (The 75-Hz "pulse" every time a 75Hz monitor refreshes: the GPU will suddenly become very active, then stop drawing power waiting for VSync).
* Whatever the GHz is for PCIe communications
* Etc. etc. (Anything else that varies power across time)
Satisfying the needs of both a 5GHz and 75Hz simultaneously (and everything else) is what makes this so difficult. On the one hand, MLCC is traditionally considered great for high-frequency signals (like 5GHz). But guess what's considered best for low-frequency (75Hz) signals? You betcha: huge, high ESR Aluminum caps (and big 470 uF POSCAPs or 220uF caps would similarly better tackle lower-frequency problems).
----------
COULD the issue be the 2.1GHz signal? Do we KNOW FOR SURE that the issue is that the PDN runs out of power inside of a nanosecond?
Or is the card running out of power on VSyncs (~75Hz)? If the card is running out of power at that point, maybe more POSCAPs is better.
I wouldn't be convinced MLCC is "better" until someone posts a sub-nanosecond transient on a $50,000 10GHz oscilloscope showing the problem. Heck, I've seen no actual evidence posted in this entire discussion that even suggests the PDN is the issue yet. (Yeah, EVGA says they had issues when making the card. But other companies clearly have a different power-network design and EVGA's issues may not match theirs).