Tuesday, February 23rd 2021

"Rocket Lake" Offers 11% Higher PCIe Gen4 NVMe Storage Performance: Intel
Intel claims that its upcoming 11th Gen Core "Rocket Lake-S" desktop processors offer up to 11% higher storage performance than competing AMD Ryzen 5000 processors, when using the CPU-attached M.2 NVMe slot. A performance slide released by Intel's Ryan Shrout shows a Samsung 980 PRO 1 TB PCI-Express 4.0 x4 M.2 NVMe SSD performance on a machine powered by a Core i9-11900K processor, compared to one powered by an AMD Ryzen 9 5950X. PCMark 10 Quick System Drive Benchmark is used to evaluate storage performance on both machines. On both machines a separate drive is used as the OS/boot drive, and the Samsung 980 PRO is used as a test drive, free from any OS role.
The backup page for the slide provides details of the system configurations used for both machines. What it doesn't mention, however, is whether on the AMD machine, the 980 PRO was installed on the CPU-attached M.2 NVMe slot, or one that's attached to the AMD X570 chipset. Unlike the Intel Z590, the AMD X570 puts out downstream PCI-Express 4.0, which motherboard designers can use to put out additional NVMe Gen 4 slots. On the Intel Z590 motherboard, the M.2 NVMe Gen 4 slot the drive was tested on is guaranteed to be the CPU-attached one, as the Z590 PCH puts out PCIe Gen 3 downstream lanes. A PCI-Express 4.0 x4 link is used as chipset bus on the AMD X570, offering comparable bandwidth to the DMI 3.0 x8 (PCI-Express 3.0 x8) employed on the Intel Z590. A drive capable of attaining 7 GB/s sequential transfers should be in a sub-optimal situation on a chipset-attached M.2 slot. It would be nice if Intel clears this up in an update to its backup.
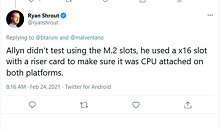
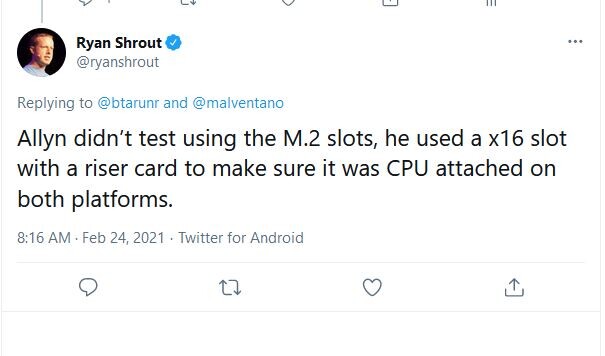
Update 02:51 UTC: In response to a specific question on Twitter, on whether the drives were tested on CPU-attached M.2 slots on both platforms, Ryan Shrout stated that a PCI-Express AIC riser card was used on both platforms to ensure that the drives are CPU-attached. 11% is a significant storage performance uplift on offer.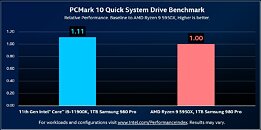

Source:
Ryan Shrout (Twitter)
The backup page for the slide provides details of the system configurations used for both machines. What it doesn't mention, however, is whether on the AMD machine, the 980 PRO was installed on the CPU-attached M.2 NVMe slot, or one that's attached to the AMD X570 chipset. Unlike the Intel Z590, the AMD X570 puts out downstream PCI-Express 4.0, which motherboard designers can use to put out additional NVMe Gen 4 slots. On the Intel Z590 motherboard, the M.2 NVMe Gen 4 slot the drive was tested on is guaranteed to be the CPU-attached one, as the Z590 PCH puts out PCIe Gen 3 downstream lanes. A PCI-Express 4.0 x4 link is used as chipset bus on the AMD X570, offering comparable bandwidth to the DMI 3.0 x8 (PCI-Express 3.0 x8) employed on the Intel Z590. A drive capable of attaining 7 GB/s sequential transfers should be in a sub-optimal situation on a chipset-attached M.2 slot. It would be nice if Intel clears this up in an update to its backup.
Update 02:51 UTC: In response to a specific question on Twitter, on whether the drives were tested on CPU-attached M.2 slots on both platforms, Ryan Shrout stated that a PCI-Express AIC riser card was used on both platforms to ensure that the drives are CPU-attached. 11% is a significant storage performance uplift on offer.


41 Comments on "Rocket Lake" Offers 11% Higher PCIe Gen4 NVMe Storage Performance: Intel
From Asrock B560 Pro4 description:
11th Gen Intel® Core™ Processors
- 2 x PCI Express x16 Slots (PCIE1/PCIE3: single at Gen4x16 (PCIE1); dual at Gen4x16 (PCIE1) / Gen3x2 (PCIE3))*
- 1 x Hyper M.2 Socket (M2_1), supports M Key type 2242/2260/2280 M.2 PCI Express module up to Gen4x4 (64 Gb/s) (Only supported with 11th Gen Intel® Core™ Processors)**
From Asrock H570M Pro4:
11th Gen Intel® Core™ Processors
- 1 x PCI Express 4.0 x16 Slot (PCIE1)*
- 1 x Hyper M.2 Socket (M2_1), supports M Key type 2280 M.2 PCI Express module up to Gen4x4 (64 Gb/s) (Only supported with 11th Gen Intel® Core™ Processors) **
So no Z boards are also getting PCI-E 4.0.
1
2
BIOS is relevant for many things, but not for PCIe performance anyway. :)Games like all applications relies on standard library functions to do IO, which are completely agnostic whether the file is loaded from a floppy, an SSD or from RAM cache. So there is no such thing as optimizing for HDDs, unless you are designing a file system or firmware.
Even changing buffer sizes for file loading have little effect on read performance from SSDs, according to my own tests.
So if you see little performance gain in loading times when switching from HDDs to SSDs, it has to do with other overhead in the game engine.Decompression speed varies between algorithms, but generally speaking a single core should be able to handle several hundred MB/s in many of them.
I'm pretty sure it comes down to just plain bloated code in most cases, but it is testable to some extent, assuming loading times are fairly consistent for a setup. If you see a clear correlation between CPU performance and loading times(let's say you underclock your CPU significantly), then it's the load of the algorithm. On the other hand, if you see little difference between vastly different CPUs and storage mediums, then it's most likely due to software bloat causing cache misses.There are many aspects of caches which matters; latency, banks, bandwidth etc. Due to ever-changing architectures, cache sizes may go up and down, but performance nearly always improves.FPGAs are way too slow to be competing with high-performance CPUs, and also too expensive.
I'm all for removing application specific fixed function hardware, but to replace it with more execution ports with more ALUs and vector units, and possibly some more programmability on the CPU-front-end through firmware. This should achieve more or less what you want at a much lower cost.
I stayed with Gen3 nvme drives because I transfer enough between drives to enjoy > sata, prices are comparable and... game load times don't change.
Heck, when nvme drives first came out, boot times were longer due to the initialization time completely offsetting the startup advantage and how serial windows boot is.
Buying quality nand that has sustainable performance is far more important to me than setting benchmark records for things I will never see in daily usage.
I can't wait for micron to release some 3dxpoint consumer products at more reasonable price points than optane.
Bring me faster Q1 performance intel, then we talk."No need to wait, just have to not use a removed known buggy UEFI that is significantly older than the rom they used on the Intel board.
The pulled rom used and older Agesa. It's like IO die firmware could effect... IO. No, couldn't be the case, you must be right, no reason fraudulent shamed journalist used a pulled rom.
In the mean time, AMD has PCIe Gen 4 and Intel does not, therefore AMD products offer 100% more bandwidth than Intel products.As far as I understand why is because of the nature of SRAM (cache memory) is that a larger amount increases the latency and is more difficult to clock higher. AMD decided with Ryzen to decrease the L1 but also reduce its latency and not run into a MHz limitation, and to increase the L2 and reduce the latency of the L2, then strap on a massive L3. This was all part of the Zen architecture, and as always trade-offs come into play.
Then of course AMD essentially perfected Zen 1 with the Zen+ refresh which reduced the cache latencies all round even further.
I do not know what AMD plans with the Zen 4 architecture at the low level, right now I am keeping an eye out for the Zen 3+ CPU's, which I am hoping will bring a much faster memory controller like they have on the already shipping "Cezanne" APU architecture.
wccftech.com/amd-ryzen-5000g-8-core-cezanne-zen-3-apu-tested-b550-platform-ddr4-4400/
People have since hit 4,800MHz but it was not stable. If AMD can bring 4,266MHz RAM to Zen 3+ CPU's I will buy one and upgrade to a 500 series chipset as I have no plans to buy any DDR-5 system until the 2nd generation once things have been tweaked and RAM prices are sensible (remember that AMD is using the Tick-Tock concept), so I will be looking to get Zen 3+ then Zen 4+, or perhaps even Zen 5, but a lot of this depends on what happens in reality and what happens with the RAM prices.
Interesting in the computer sphere as always :D
If you mean practical performance, then that's exactly what Renoir already brought to the table. 1:1 at DDR4-4400 should be widely doable for most 6- and 8-core Renoirs, mine does 4400 @ 1.2V. Not to mention that Renoir has the better memory controller - Renoir posts better read/write/copy/latency performance. And when you decouple Infinity Fabric on Renoir, the memory controller can already hit speeds far above the 4800MT/s that you stated. From all indications it doesn't appear that AMD changed anything significant with Cezanne's memory controller, so Cezanne might be to Renoir what Vermeer is to Matisse.
The problem when you want to play in the high memory speed arena is that even with Renoir, you will run into other limits far before you max out the K17.6 memory controller. If you have poorly binned B-die or B-die that is (unfortunately) on an A0 PCB (me), you will run into that first. Even with good B-die, you will run into your limits before 5000MT/s, because B-die isn't really the IC of choice for raw freq. Then assuming you run on a decent 6-layer ATX or 8-layer ITX, you'll start maxing that out in around the 5000MT/s range.
And so it really doesn't depend at all on the memory controller, it's way past that. What's needed is Infinity Fabric to scale to those speeds, and I don't even know if that's doable.
duckduckgo.com/?q=amd+tick+tock&t=chromentp&ia=webWell yes, there are a host of other issues, the motherboard being one of them, but the primary problem is the memory controller, even in Zen 3 CPU's because people are hitting high RAM speeds on the same desktop boards with APU's that they are not hitting with the CPU's, hence why my real hope for Zen 3+ is a better memory controller.
My 3600 will run 4,000MHz RAM, but obviously not at 1:1:1, (my RAM incidentally is capable of 4,266) but after a fair bit of testing and tweaking my RAM is operating as fast as it will go (in real world use) with my 3600 and my X470 motherboard running a 3,400MHz @ 14:14:14 timings.
If AMD's Zen 3+ doesn't support faster RAM, I expect that I will wait for Zen 4, or get a Threadripper 3000 series when they plummet in price, I will wait and see what happens, many options, but going to Intel is almost certainly not one of them.
The inevitable drawback of using chiplets is memory latency and interconnect performance, so as long as AMD sticks to its high core count philosophy and current I/O + 2 CCD design, you can forget about having monolithic APU memory performance ever, even if somehow they drop the APU UMC into the desktop I/O die (unlikely, no reason for them to do so).
Even Matisse's UMC is seriously good enough (arguably was already better than Intel IMC, though kinda apples to oranges) - you just can't leverage its full potential in daily use because Infinity Fabric is a cockblock.
I have now a Samsung 1TB
980 ProPM9A1 (OEM version of the 980 Pro), and it gives a huge boost in load times, and a 10% boost would be noticeable.But as this world shocking news is brought to us by Ryan the Cherry-picker, I take this news with a shovel of salt, and wait till I see trustworthy benchmarks from TPU or any other tech site that I trust.Uhhh, the speed of ''random read speed'' is mostly depending on latency!Yeah that guy made him self one hell of a joke. ^_^
But maybe he is doing internally a hell of a job, but somehow doubt that to. LOLNot really just typical Intel behaviour, Apple, Nvidia, John Deere, Big Pharma, when they have the power they all do it, and they go as far is what they can get away with!Seek time from SSDs are just as far from HDDs, as SSDs are from dram, Intel has put billions in R&D for XPoint to replace flash.Yes you have sort of 3 teams, but they are not leapfrogging each other, it's the same as with building a chemical plant, team 1 is an architect team, team 2 is an engineering team, and team 3 are the workers that lay down the pipes and cables.
- Team 1 is a small group of idea people that does things like fundamental research and think of new concepts, how to make a faster CPU, some of them do fundamental R&D, and some of that work is unknown in which generation it will actually be ready to be used, and others do more practical R&D and have a targeted generation of use.
- Team 2 is a little bigger group that works with team 1, and start how to implement those ideas in to the silicon, and the further they get on, the more people from team 1 leave and start planing and working on the next generation CPU, at the same time the better people from team 3 start laying the main structure working close with team 2.
- Team 3 in the end is making the connections and need less and less input from team 2, at the same time, team 1 is working with people from team 2 that left the current project, and start on the next generation.
Basically depending on their role, people work on differed phases of the project, and when they are done with their part, they go to the next project/generation, usually they are working on 3 to 4 generations at the same time.
When we hear about the Zen 3+ technical details, we might get a glimpse into some of the updates for Zen 4 as I expect they will be ironing out the kinks and putting to use their updated tech before Zen 4. Also, I fully expect that AMD will be using the same tech (Infinity Fabric assumed) to connect together their chiplet based GPU's that are upcoming, I doubt very much that AMD would use different tech to connect their graphics silicon together than for their CPU silicon, and whichever one is out first will show us what they will do on the other.