Tuesday, March 22nd 2022

NVIDIA H100 is a Compute Monster with 80 Billion Transistors, New Compute Units and HBM3 Memory
During the GTC 2022 keynote, NVIDIA announced its newest addition to the accelerator cards family. Called NVIDIA H100 accelerator, it is the company's most powerful creation ever. Utilizing 80 billion of TSMC's 4N 4 nm transistors, H100 can output some insane performance, according to NVIDIA. Featuring a new fourth-generation Tensor Core design, it can deliver a six-fold performance increase compared to A100 Tensor Cores and a two-fold MMA (Matrix Multiply Accumulate) improvement. Additionally, new DPX instructions accelerate Dynamic Programming algorithms up to seven times over the previous A100 accelerator. Thanks to the new Hopper architecture, the Streaming Module structure has been optimized for better transfer of large data blocks.
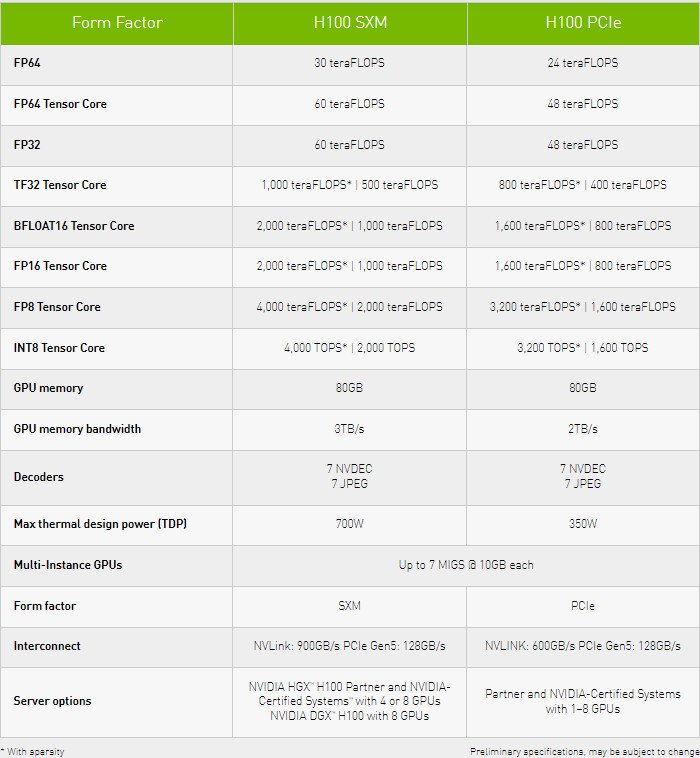
The full GH100 chip implementation features 144 SMs, and 128 FP32 CUDA cores per SM, resulting in 18,432 CUDA cores at maximum configuration. The NVIDIA H100 GPU with SXM5 board form-factor features 132 SMs, totaling 16,896 CUDA cores, while the PCIe 5.0 add-in card has 114 SMs, totaling 14,592 CUDA cores. As much as 80 GB of HBM3 memory surrounds the GPU at 3 TB/s bandwidth. Interestingly, the SXM5 variant features a very large TDP of 700 Watts, while the PCIe card is limited to 350 Watts. This is the result of better cooling solutions offered for the SXM form-factor. As far as performance figures are concerned, the SXM and PCIe versions provide two distinctive figures for each implementation. You can check out the performance estimates in various precision modes below. You can read more about the Hopper architecture and what makes it special in this whitepaper published by NVIDIA.

The full GH100 chip implementation features 144 SMs, and 128 FP32 CUDA cores per SM, resulting in 18,432 CUDA cores at maximum configuration. The NVIDIA H100 GPU with SXM5 board form-factor features 132 SMs, totaling 16,896 CUDA cores, while the PCIe 5.0 add-in card has 114 SMs, totaling 14,592 CUDA cores. As much as 80 GB of HBM3 memory surrounds the GPU at 3 TB/s bandwidth. Interestingly, the SXM5 variant features a very large TDP of 700 Watts, while the PCIe card is limited to 350 Watts. This is the result of better cooling solutions offered for the SXM form-factor. As far as performance figures are concerned, the SXM and PCIe versions provide two distinctive figures for each implementation. You can check out the performance estimates in various precision modes below. You can read more about the Hopper architecture and what makes it special in this whitepaper published by NVIDIA.

29 Comments on NVIDIA H100 is a Compute Monster with 80 Billion Transistors, New Compute Units and HBM3 Memory
1. Turing
2. Ampere
3. Lovelace
4. Hopper
Lovelace is 5nm.
Anyway, something something Crysis.
is this a fucking joke at this point?????????????????
I really hate the increase in TDP but it isn't only Nvidia it seems to be industry wide due to process advancements.
Regarding Ada Lovelace i expect the $499-$449 (cut down AD104 5nm) part to have around +15% performance/W vs Navi 33 (6nm)
I read somewhere that AD106 & AD107 is 6nm not 5nm but i don't know if it's true.
Edit : it seems too big for 4nm (only -6% vs 5nm logic density scaling) for only 80 billion transistors, I'm way off with my calculations, I'm nearly 100mm² off, enough to house 240MB L3 cache, surely I'm doing something wrong.
Damn, I'll bet this performance monster can do 8K with no problem. I'm sure that the high end cards will also be reassuringly unaffordable, making any reviews academic.
Huge number crunchers built for massively parallel tasks. Not much to balance as with gaming GPUs. Just take the biggest die and cram as much as you can into it.