Friday, September 15th 2023

Apple A17 Pro SoC Within Reach of Intel i9-13900K in Single-Core Performance
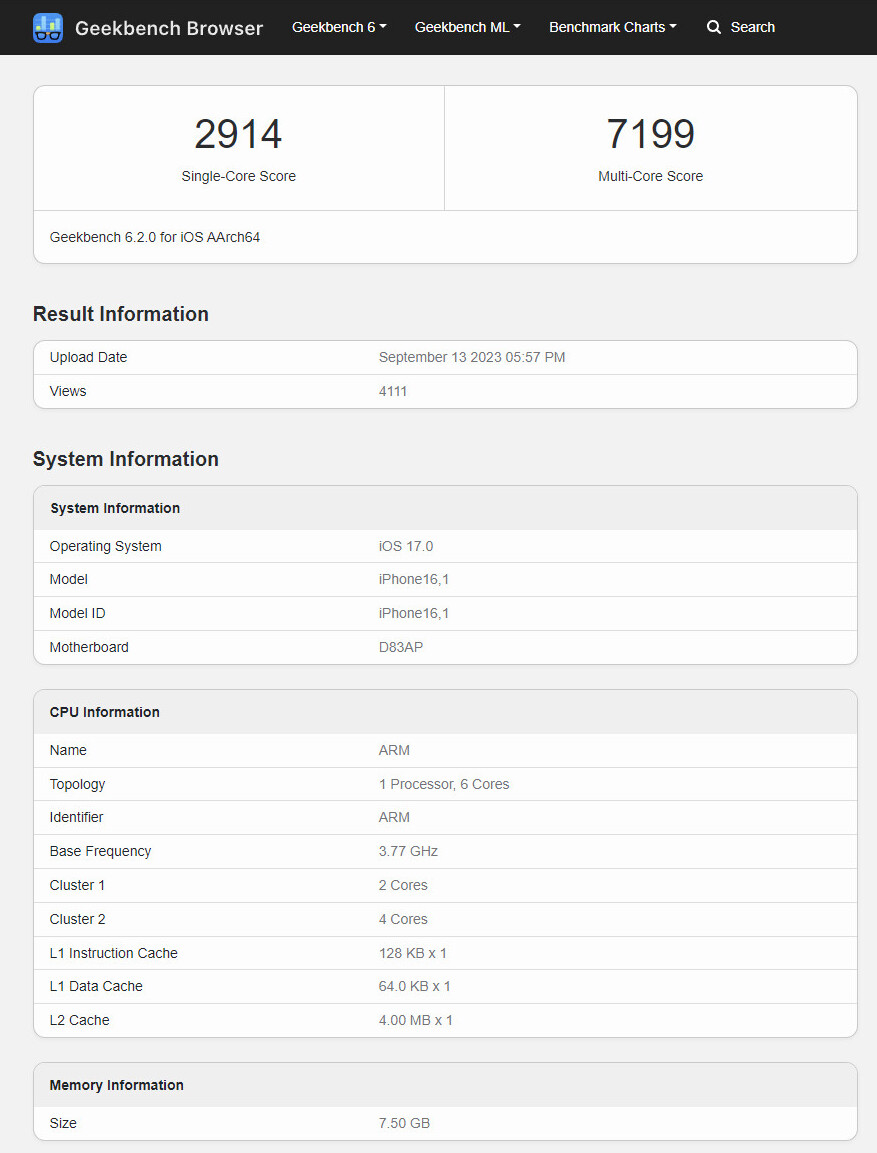
An Apple "iPhone16,1" was put through the Geekbench 6.2 gauntlet earlier this week—according to database info this pre-retail sample was running a build of iOS 17.0 (currently in preview) and its logic board goes under the "D83AP" moniker. It is interesting to see a unit hitting the test phase only a day after the unveiling of Apple's iPhone 15 Pro and Max models—the freshly benched candidate seems to house an A17 Pro system-on-chip. The American tech giant has set lofty goals for said flagship SoC, since it is "the industry's first 3-nanometer chip. Continuing Apple's leadership in smartphone silicon, A17 Pro brings improvements to the entire chip, including the biggest GPU redesign in Apple's history. The new CPU is up to 10 percent faster with microarchitectural and design improvements, and the Neural Engine is now up to 2x faster."
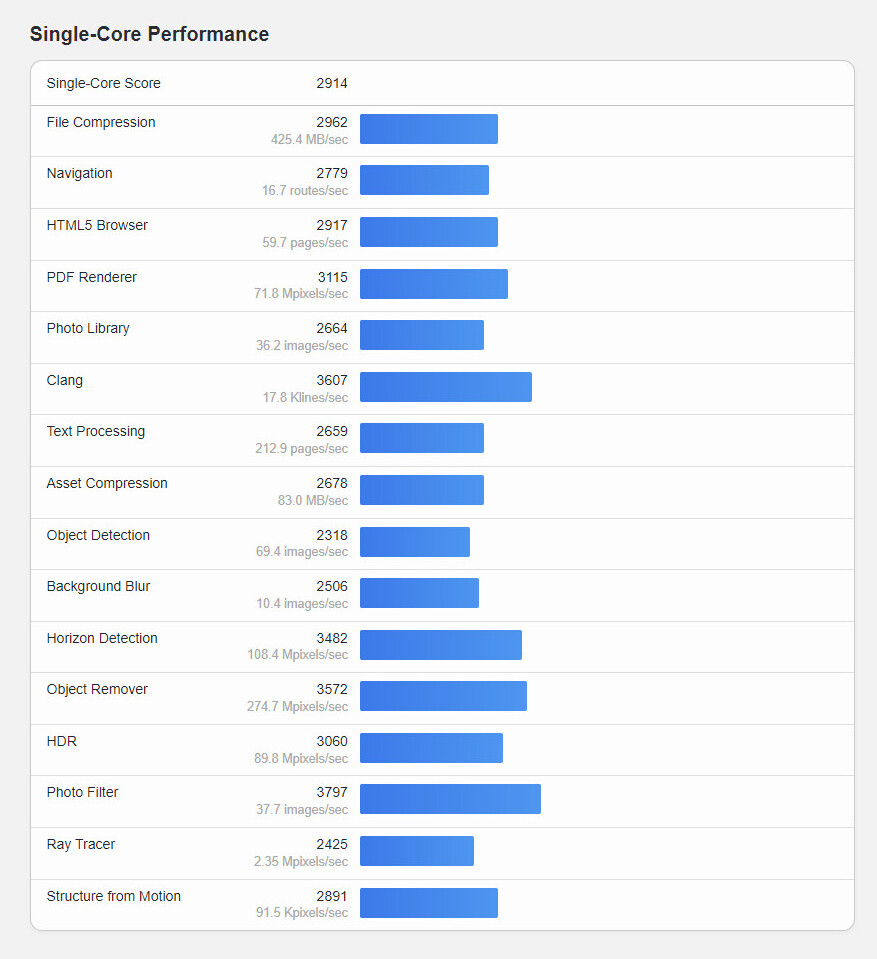
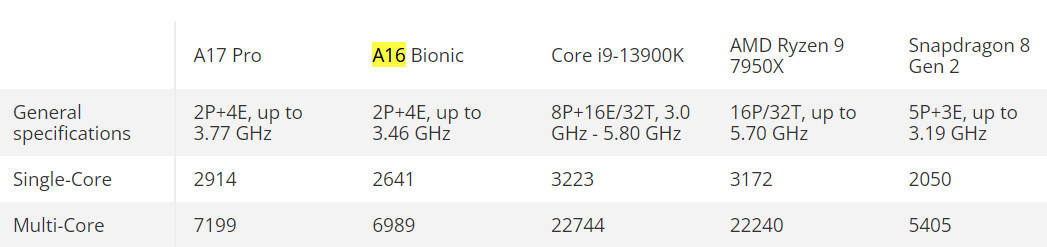
Tech news sites have pored over the leaked unit's Geekbench 6.2 scores—its A17 Pro chipset (TSMC N3) surpasses the previous generation A16 Bionic (TSMC N4) by 10% in single-core stakes. Apple revealed this performance uplift during this week's iPhone "Wonderlust" event, so the result is not at all surprising. The multi-score improvement is a mere ~3%, suggesting that only minor tweaks have been made to the underlying microarchitecture. The A17 Pro beats Qualcomm's Snapdragon 8 Gen 2 in both categories—2914 vs. 2050 (SC) and 7199 vs. 5405 (MC) respectively. Spring time leaks indicated that the "A17 Bionic" was able to keep up with high-end Intel and AMD desktop CPUs in terms of single-core performance—the latest Geekbench 6.2 entry semi-confirms those claims. The A17 Pro's single-threaded performance is within 10% of Intel Core i9-13900K and Ryzen 9 7950X processors. Naturally, Apple's plucky mobile chip cannot put up a fight in the multi-core arena, additionally Tom's Hardware notes another catch: "A17 Pro operates at 3.75 GHz, according to the benchmark, whereas its mighty competitors work at about 5.80 GHz and 6.0 GHz, respectively."



Sources:
Tom's Hardware, Geekbench, Techspot, Wccftech
Tech news sites have pored over the leaked unit's Geekbench 6.2 scores—its A17 Pro chipset (TSMC N3) surpasses the previous generation A16 Bionic (TSMC N4) by 10% in single-core stakes. Apple revealed this performance uplift during this week's iPhone "Wonderlust" event, so the result is not at all surprising. The multi-score improvement is a mere ~3%, suggesting that only minor tweaks have been made to the underlying microarchitecture. The A17 Pro beats Qualcomm's Snapdragon 8 Gen 2 in both categories—2914 vs. 2050 (SC) and 7199 vs. 5405 (MC) respectively. Spring time leaks indicated that the "A17 Bionic" was able to keep up with high-end Intel and AMD desktop CPUs in terms of single-core performance—the latest Geekbench 6.2 entry semi-confirms those claims. The A17 Pro's single-threaded performance is within 10% of Intel Core i9-13900K and Ryzen 9 7950X processors. Naturally, Apple's plucky mobile chip cannot put up a fight in the multi-core arena, additionally Tom's Hardware notes another catch: "A17 Pro operates at 3.75 GHz, according to the benchmark, whereas its mighty competitors work at about 5.80 GHz and 6.0 GHz, respectively."

46 Comments on Apple A17 Pro SoC Within Reach of Intel i9-13900K in Single-Core Performance
I feel so small in comparison with those brilliant engineers that work on such projects.
knowing that it's out since some time now ... less than 900pts more single core, while clocked .57mhz higher, is a bit "yawn" but +1794pts in multi is not bad tho ... (not that it's needed in a phone ... the SD8G2 feel already overkill :laugh:
edit, 3.19? the std SD8G2 is 3.2 on the X3 (3.36 in the "For Galaxy" variant) bah, not that 0.01ghz is an issue :laugh:
Not a slight toward the chip at all, rather the process (the mobile-leaning density over speed improvement); That's pretty awful. I'm sure N3E will help eek out the required generational performance (twice the clock improvement of n3b at the cost of some density) but one has to factor in the cost/fab space and question for how many products it will truly be worth it (at least until the price comes down or fab allocation becomes less of an issue).
Look at TSMC's press release for N4X, which claims "4% improvement over N4P at 1.2v", which, to save you some time, implies N4X can hit 3600mhz at 1.2v with the capability of being driven even harder. How hard, I don't know know, but I would imagine at least 1.3v (think of chips [cpus/RV790] in the past that were ~1.3125v) isn't out of the question, maybe even 1.35v (which appears to be the Fahrenheit 451 for this type of use case; think about AMD's SOC voltage problems).
Personally, I always think back to ~1.325v being the sweet spot for many chips over several different nodes and generations. Ye ole' 4.7ghz that Intel and AMD were stuck at for some time, granted that's anecdotal.
It's also worth noting, while it has often been lost in the shuffle of the news cycles, that it has been said N4X has been able to achieve higher clockspeeds than N3B, which we now have some context. So probably between ~3.7-4.0ghz. It could potentially perform very similar to n3e just with worse density and power characteristics.
So, just think about that for a hot second. I know this is a space for talking about Apple and the A17, but I will be that guy that interjects about other uses.
Think about N31/N32, running at 1.1v and 1.15v respectively on N5, or nVIDIA's tuning/amalgamation of the process (that probably is denser but limited to ~1.08v for optimal leakage scaling on N5) and their intended power/clock constraints (which I will grant some have circumvented for N31 and the 7700xt can some-what do within it's allowable max TDP).
At some point I just have to wonder if N3E is worth it at any point in the near future. I say this because if you look at something like N32, which I would argue is bandwidth balanced at ~2900/20000, you could very realistically (if AMD can fix whatever gaming clockspeed problems exist in RDNA3) jack that up to ~3500/24000 on N4X and literally replace the 7900xt/compete with the 4080; not a bad place to be cost/performance-wise even if they lose some power efficiency. The argument I will continue to make is that once a card is greater than 225w (one 8-pin connector, easy to cool, cheap PCBs/caps/etc can be used) you may as well use the headroom up to at least 300w, if not 375w, which N32 currently does not. If would be one thing if these cards were shorter/thinner like mid-range cards of yore, but many of them are engineered to the level of a 7900-level card already, with hot spots not exceeding 80c. That gives them ~20% heat headroom assuming the same designs. Assuming N4X can scale well to those higher voltages, it appears a no-brainer IMHO.
N31 is a little more nuanced, as 24gbps memory probably would probably limit the card below 3300mhz and still play second-fiddle to 4090, even if it halves the gap. What they need in that case (regardless of memory used) is to double up the ∞$ to make it similar to nvidia's L2 bandwidth. While I have no idea if they plan to continue to use MCDs going forward into the far future, two things remain true: the cache can and needs to be doubled, and it should transition to 4nm when economically feasible. Even on 6nm, the (16MB+MC) MCD is 37.5mm2. The 64MB on X3D CPUs is ~36mm2. This implies they could add 16MB of cache while staying within the parameters of why the design makes sense. That is to say, a MCD has to be less than the smallest chip with that size bus (ex: 256-bit and <200mm2; hence a MCD should be less than 50mm2). I understand the rumors have always pointed to stacking (and maybe GDDR6W), but wonder if that's truely necessary. With that amount of cache they could even use cheaper memory, as theoretically doubling the L3 alone should allow it to scale to the limits of the process. It could be a true 4090 competitor. Sure, it'd probably use a metric ton of power by virtue of 18432/16384 at lower voltage/clocks will always be twice the proportional efficiency than 12288 at higher, but we are living in a world with a freaking 600W power cable (+75w from the slot). 3 8-pin is also 675w. If that's where we're going, we might as well freaking do it. Nobody will force you buy it, but one thing is for sure...It would be a hell of a lot cheaper up-front.
That's it. That's my spiel. I know we keep hearing about N43/44 (and perhaps being monolithic), and that's fine. Maybe they are (similar to) the things I ponder, maybe they aren't. But in a world where a 4090 is at least $1600, a 4080 $1100, and a 4070ti $800, while the competing stack (7900xtx/7800xt/7700xt) is/will be soon literally half the price, I certainly wouldn't mind a refresh on the later to compete with the former. It may sound incredibly strange, but it's absolutely possible, as it could be AMD doing what AMD does: competing one tier up the stack for their price. EX: a 4090 competitor for the price of a 4080, a 4080 competitor for the price of a 4070ti (whatever those prices are by the time those products could launch).
In a world where an ~7800xt will probably power the PS5 pro, which appears to content most people (~4k60), and that will last us another 3-5 years, and the PS6 maybe 2-2.25x that (perhaps similar/a little faster than a 4090) lasting another 4-8 years AFTER THAT, I have to ask if we truly need a $2000 3nm nvidia part, whatever it's capabilities...or do we need what I described; the smallest 256-bit/384-bit parts that can achieve their highest performance potential at the most economical price if they are in the realm of achieving that level of performance. Because of the slowing of process tech, the idea of long-term future-proofing at the high-end, just like the 'mid-range' with the 7800xt, at a relatively cheaper price isn't completely out of the question if one of the companies (which won't be nVIDIA) decides to make it so.
Source: N4X press release: pr.tsmc.com/english/news/2895
Yeah sure, the ProRes video recording takes A LOT of power and gaming might also use a lot of power. But still.....
source: www.notebookcheck.net/M2-Max-vs-R9-7945HX_14975_14936.247596.0.html
But the i9-13900k if it is tested on iOS (I know it won't work but just to compare performance) then it will blow the A17 Pro , note the 13900k is tested on Windows AND apple make the CHIP and IOS so the A17 Pro are 100% optimized for iOS. And the same goes for A17 PRO let say it works on windows then you will see way way less of a score.
chipsandcheese.com/2023/09/06/hot-chips-2023-characterizing-gaming-workloads-on-zen-4/
While they're probably not as renowned as AT even 2 decades back, but from whatever I can understand their analysis is top notch!