Monday, October 2nd 2023

NVIDIA Chief Scientist Reaffirms Huang's Law
In a talk, now available online, NVIDIA Chief Scientist Bill Dally describes a tectonic shift in how computer performance gets delivered in a post-Moore's law era. Each new processor requires ingenuity and effort inventing and validating fresh ingredients, he said in a recent keynote address at Hot Chips, an annual gathering of chip and systems engineers. That's radically different from a generation ago, when engineers essentially relied on the physics of ever smaller, faster chips.
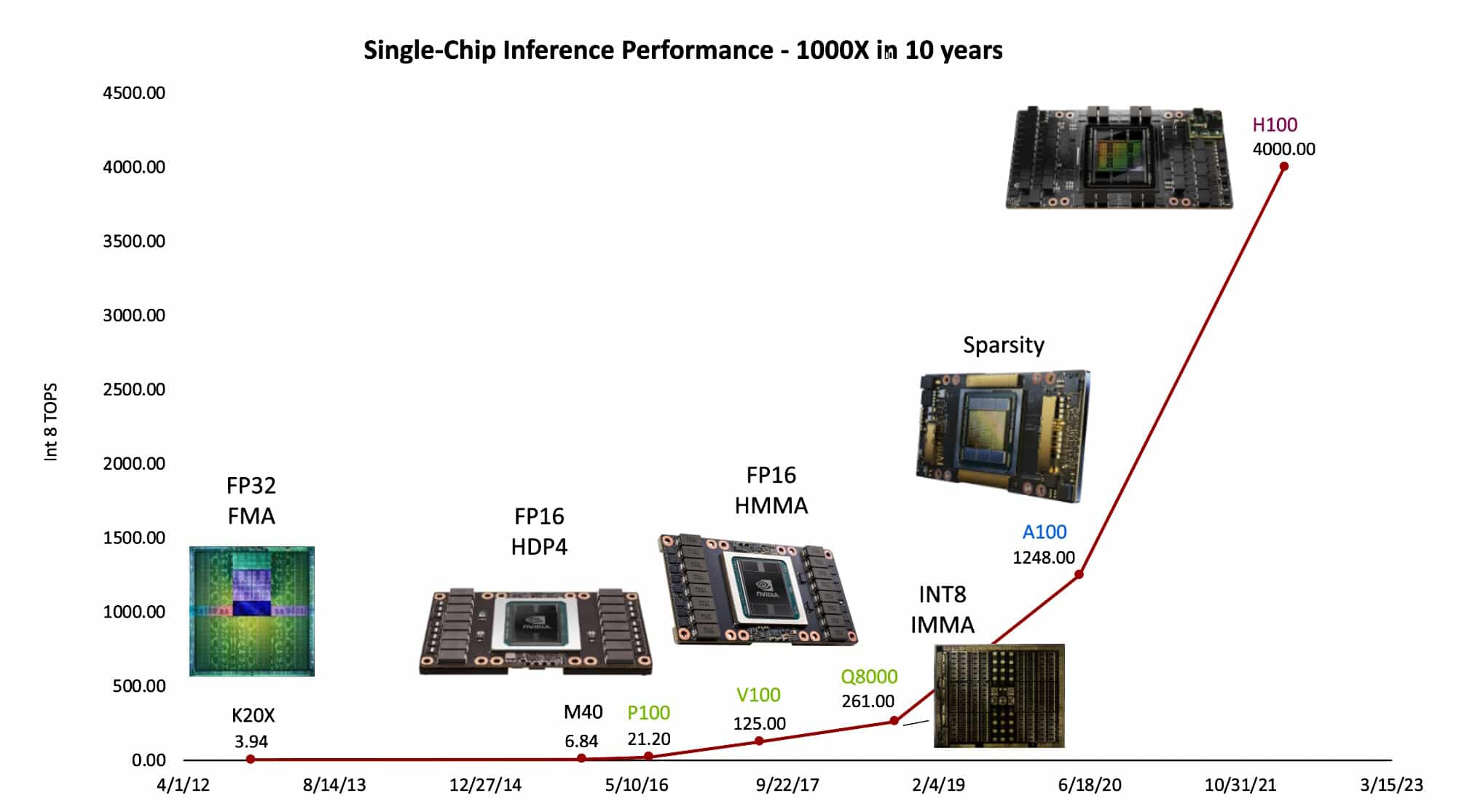
The team of more than 300 that Dally leads at NVIDIA Research helped deliver a whopping 1,000x improvement in single GPU performance on AI inference over the past decade (see chart below). It's an astounding increase that IEEE Spectrum was the first to dub "Huang's Law" after NVIDIA founder and CEO Jensen Huang. The label was later popularized by a column in the Wall Street Journal.
 The advance was a response to the equally phenomenal rise of large language models used for generative AI that are growing by an order of magnitude every year. "That's been setting the pace for us in the hardware industry because we feel we have to provide for this demand," Dally said.
The advance was a response to the equally phenomenal rise of large language models used for generative AI that are growing by an order of magnitude every year. "That's been setting the pace for us in the hardware industry because we feel we have to provide for this demand," Dally said.
In his talk, Dally detailed the elements that drove the 1,000x gain. The largest of all, a sixteen-fold gain, came from finding simpler ways to represent the numbers computers use to make their calculations.
The New Math
The latest NVIDIA Hopper architecture with its Transformer Engine uses a dynamic mix of eight- and 16-bit floating point and integer math. It's tailored to the needs of today's generative AI models. Dally detailed both the performance gains and the energy savings the new math delivers.
Separately, his team helped achieve a 12.5x leap by crafting advanced instructions that tell the GPU how to organize its work. These complex commands help execute more work with less energy. As a result, computers can be "as efficient as dedicated accelerators, but retain all the programmability of GPUs," he said.
In addition, the NVIDIA Ampere architecture added structural sparsity, an innovative way to simplify the weights in AI models without compromising the model's accuracy. The technique brought another 2x performance increase and promises future advances, too, he said. Dally described how NVLink interconnects between GPUs in a system and NVIDIA networking among systems compound the 1,000x gains in single GPU performance.
No Free Lunch
Though NVIDIA migrated GPUs from 28 nm to 5 nm semiconductor nodes over the decade, that technology only accounted for 2.5x of the total gains, Dally noted.
That's a huge change from computer design a generation ago under Moore's law, an observation that performance should double every two years as chips become ever smaller and faster.
Those gains were described in part by Denard scaling, essentially a physics formula defined in a 1974 paper co-authored by IBM scientist Robert Denard. Unfortunately, the physics of shrinking hit natural limits such as the amount of heat the ever smaller and faster devices could tolerate.
An Upbeat Outlook
Dally expressed confidence that Huang's law will continue despite diminishing gains from Moore's law.
For example, he outlined several opportunities for future advances in further simplifying how numbers are represented, creating more sparsity in AI models and designing better memory and communications circuits.
Because each new chip and system generation demands new innovations, "it's a fun time to be a computer engineer," he said.
Dally believes the new dynamic in computer design is giving NVIDIA's engineers the three opportunities they desire most: to be part of a winning team, to work with smart people and to work on designs that have impact.
Source:
NVIDIA Blog
The team of more than 300 that Dally leads at NVIDIA Research helped deliver a whopping 1,000x improvement in single GPU performance on AI inference over the past decade (see chart below). It's an astounding increase that IEEE Spectrum was the first to dub "Huang's Law" after NVIDIA founder and CEO Jensen Huang. The label was later popularized by a column in the Wall Street Journal.

In his talk, Dally detailed the elements that drove the 1,000x gain. The largest of all, a sixteen-fold gain, came from finding simpler ways to represent the numbers computers use to make their calculations.
The New Math
The latest NVIDIA Hopper architecture with its Transformer Engine uses a dynamic mix of eight- and 16-bit floating point and integer math. It's tailored to the needs of today's generative AI models. Dally detailed both the performance gains and the energy savings the new math delivers.
Separately, his team helped achieve a 12.5x leap by crafting advanced instructions that tell the GPU how to organize its work. These complex commands help execute more work with less energy. As a result, computers can be "as efficient as dedicated accelerators, but retain all the programmability of GPUs," he said.
In addition, the NVIDIA Ampere architecture added structural sparsity, an innovative way to simplify the weights in AI models without compromising the model's accuracy. The technique brought another 2x performance increase and promises future advances, too, he said. Dally described how NVLink interconnects between GPUs in a system and NVIDIA networking among systems compound the 1,000x gains in single GPU performance.
No Free Lunch
Though NVIDIA migrated GPUs from 28 nm to 5 nm semiconductor nodes over the decade, that technology only accounted for 2.5x of the total gains, Dally noted.
That's a huge change from computer design a generation ago under Moore's law, an observation that performance should double every two years as chips become ever smaller and faster.
Those gains were described in part by Denard scaling, essentially a physics formula defined in a 1974 paper co-authored by IBM scientist Robert Denard. Unfortunately, the physics of shrinking hit natural limits such as the amount of heat the ever smaller and faster devices could tolerate.
An Upbeat Outlook
Dally expressed confidence that Huang's law will continue despite diminishing gains from Moore's law.
For example, he outlined several opportunities for future advances in further simplifying how numbers are represented, creating more sparsity in AI models and designing better memory and communications circuits.
Because each new chip and system generation demands new innovations, "it's a fun time to be a computer engineer," he said.
Dally believes the new dynamic in computer design is giving NVIDIA's engineers the three opportunities they desire most: to be part of a winning team, to work with smart people and to work on designs that have impact.
41 Comments on NVIDIA Chief Scientist Reaffirms Huang's Law
what’s the law? I didn’t see the quote.
About replacing Moore's law. I'd personally look forward to them researching using graphene instead of silicon. We still need faster metal eventually.
Man says it's my law now but it's a secret.
I say f#@£ o££ you T#@7.
Your law is shite you egotistical Muppet.
“. Each new processor requires ingenuity and effort inventing and validating fresh ingredients, he said in a recent keynote address at Hot Chips, an annual gathering of chip and systems engineers. That's radically different from a generation ago, when engineers essentially relied on the physics of ever smaller, faster chips.”
I look at the graph and the 1000x performance.
Hmmmm
I think a better graph would be performance per transistor normalized to a specific frequency to highlight actual “ingenuity/architectural “ improvements.
The gains are initial IMHO so OF course exponential.
You talk new ingredients, such as.
Making an ASIC any ASIC is a balance of area and features, verses cost, they hype up Tesla cores but in reality most of these things are a evolution of something pre existing.
All that's made now in silicon is built on the shoulders of giants, who already did the ingenuity bit.
Again IMHO
A lot of the so called AI that's becoming popular today is using variations of the transformer model Google open sourced in 2017, nvidia now made a chip optimized for that model and is claiming an insane performance increase, very cool, let's wait then to measure this when someone decides to use a different model and see how their new "law" gets completely crushed. Or even simpler, let's give this fixed function hardware a couple generations and see how their performance improves.
Huang's so called law was a stupid market ploy to try to justify the rapid increase in prices and hopefully it continues to be ridiculled for the bullshit that it is, no matter how many times they try to bring it up and claim it's a thing.
In GPUs the gain was at a similar level, but it is much easier to notice this advance in the form of fps in games, most will not notice or take advantage of the raw power we have today in CPUs.
And... Can anyone explain what Huang's law is? "The more you buy, the more you save"? "It just works"? :p
en.m.wikipedia.org/wiki/Huang's_law
Meh, It's a comparison of oranges vs. apples. But in short, it seems like it's just a fragile, bland and generic theory propagated by some speculative journalist based on a speech Huang made a few years ago. Well, we will put this theory to the test in the coming years as lithographs are struggling to advance. My bet is GPUs with a TDP of 1000w+ next year.
In graphene electronics, we are using the same type energy in a material more fit for handling electricity. We may see less watt consumption and higher clocks.
Well, the "geniuses" will get fired when the bubble pops.
One of the main uses for PHOTONICS in certain electronic areas will simply be to talk between MODULES rather than run copper traces long distances. There's some discussion of using one or more in a desktop PC (i.e. talk direct to the I/O of the CPU from the Graphics card VRAM bus rather than through the traces on the motherboard). So for this usage very little changes in terms of CPU/GPU design. There are MANY uses of photonics in electronics. Some make a lot of sense. Some, are pointless. I would expect the traditional silicon TRANSISTOR approach to be around for decades to come, albeit with modifications such as carbon as you suggest, as well as a 3D approach to design but the basic on/off switch isn't going anywhere. "Photonic" transistors IMO don't make sense as a replacement for a CPU or GPU but probably make sense for simplified processing with few switches such as ROUTERS.
Multiplying all the speedups gives 10.3 which isn't too far off the multi-threaded performance increase for CPUs in that time. Anandtech's CPU bench can be used to compare the 4770k and the 7950X. There are common applications where the 7950X is as much as 9 times faster than the 4770K and these applications don't leverage any instructions unique to the newer processor such as AVX-512. I haven't used the 13900K because their database doesn't have numbers for any Intel CPUs faster than the 12900K.
Rather than blaming CPU designers, you should be asking game engine developers why their engines are unable to utilize these CPUs efficiently.
I'm saddened that Bill Dally is misrepresenting TSMC's contribution to these gains. The 28nm to 5 nm transition isn't worth only a 2.5 times increase in GPU resources. From the Titan X to AD102, clock speeds have increased by nearly 2.5 times and the GPU has 6 times more FP32 flops per clock. That is a 15 fold increase in compute solely related to the process. We shouldn't ignore the work done by Nvidia's engineers, but if we take his claim at face value, then a 28 nm 4090 would be only 2.5 times slower than the actual 4090 which is patently ridiculous.
The top Ivy bridge Xeon chips topped out at 12 cores, so again vastly lower.
The video with the clown's law:
But even if you account for the market niche and multi-die CPUs (which really are multiple CPUs in one package), I don't think IPC hasn't gone up a full 10x from Haswell to Raptor Cove (2013-2023). Operating frequencies increased greatly in the interim as well.
Core counts went from 18 (Haswell-EP) to basically around 128, so not a full 10x increase. IPC must have gone up around 6 times higher, and also an extra GHz on average, but I guess that's about it.
Might have if you compare Piledriver to Zen 4 but AMD CPUs were hopeless garbage until Ryzen came out. Could be worth looking at sometime with some real data, but we all remember how 1st gen Core i7 CPUs made sport of FX.
Still GPUs have easily outpaced this growth. GK110 to AD102 is one hell of a leap.Ah, yes, I'm sure "nGreedia" engineers are just jumping at the opportunity to work at better companies, such as AMD, perhaps? :kookoo:You're also accounting shipping products (and at a relatively low weight class) to normalize for performance, the comparison in progress should IMHO be done comparing fully enabled and endowed processors that are configured for their fullest performance, perhaps normalized for frequency to accurately measure improvements at an architectural level. We don't even have such a product available to the public for Ada Lovelace yet.