Thursday, November 2nd 2023

AMD Introduces Ryzen 5 and Ryzen 3 Mobile Processors with "Zen 4c" Cores
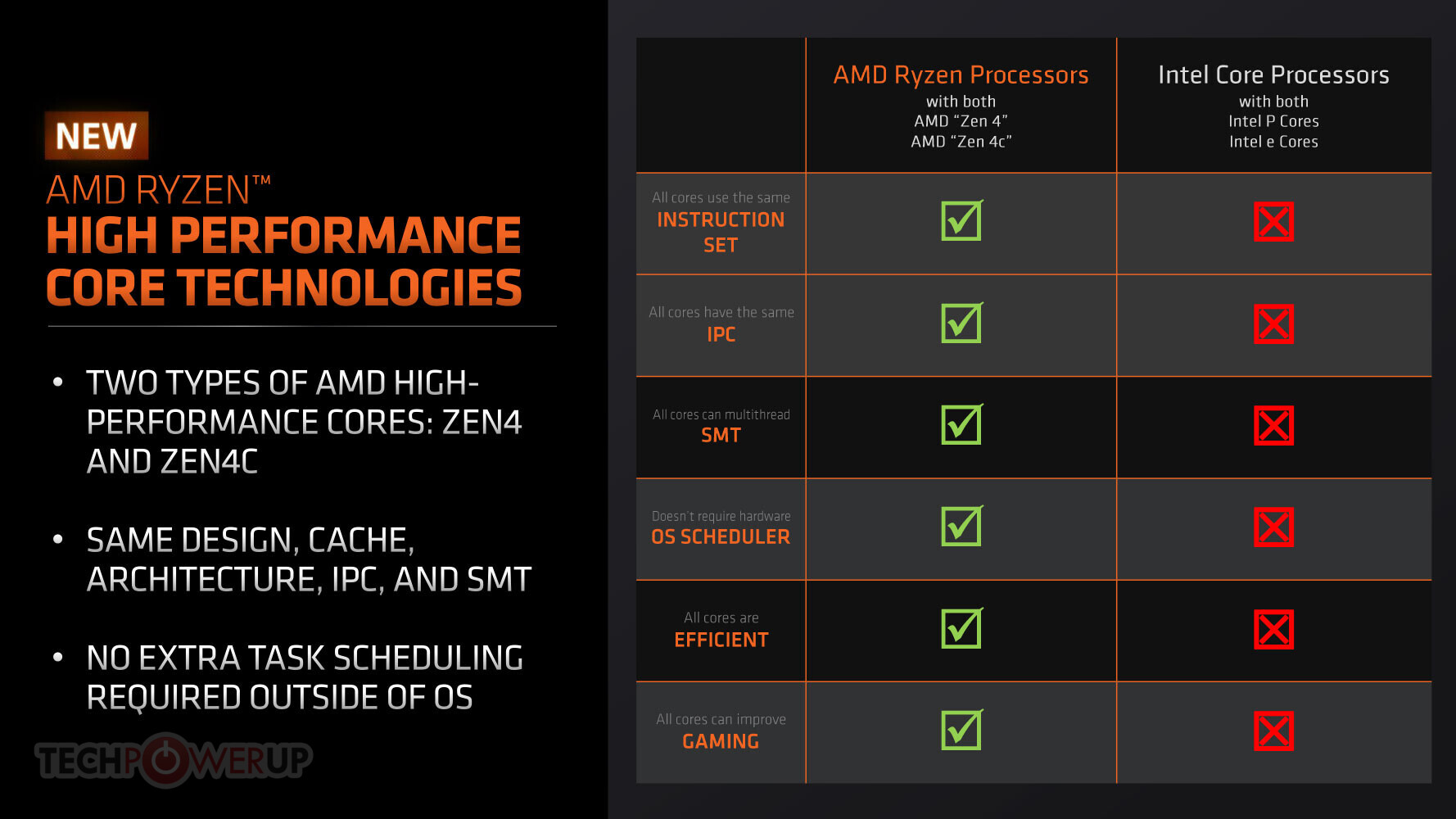
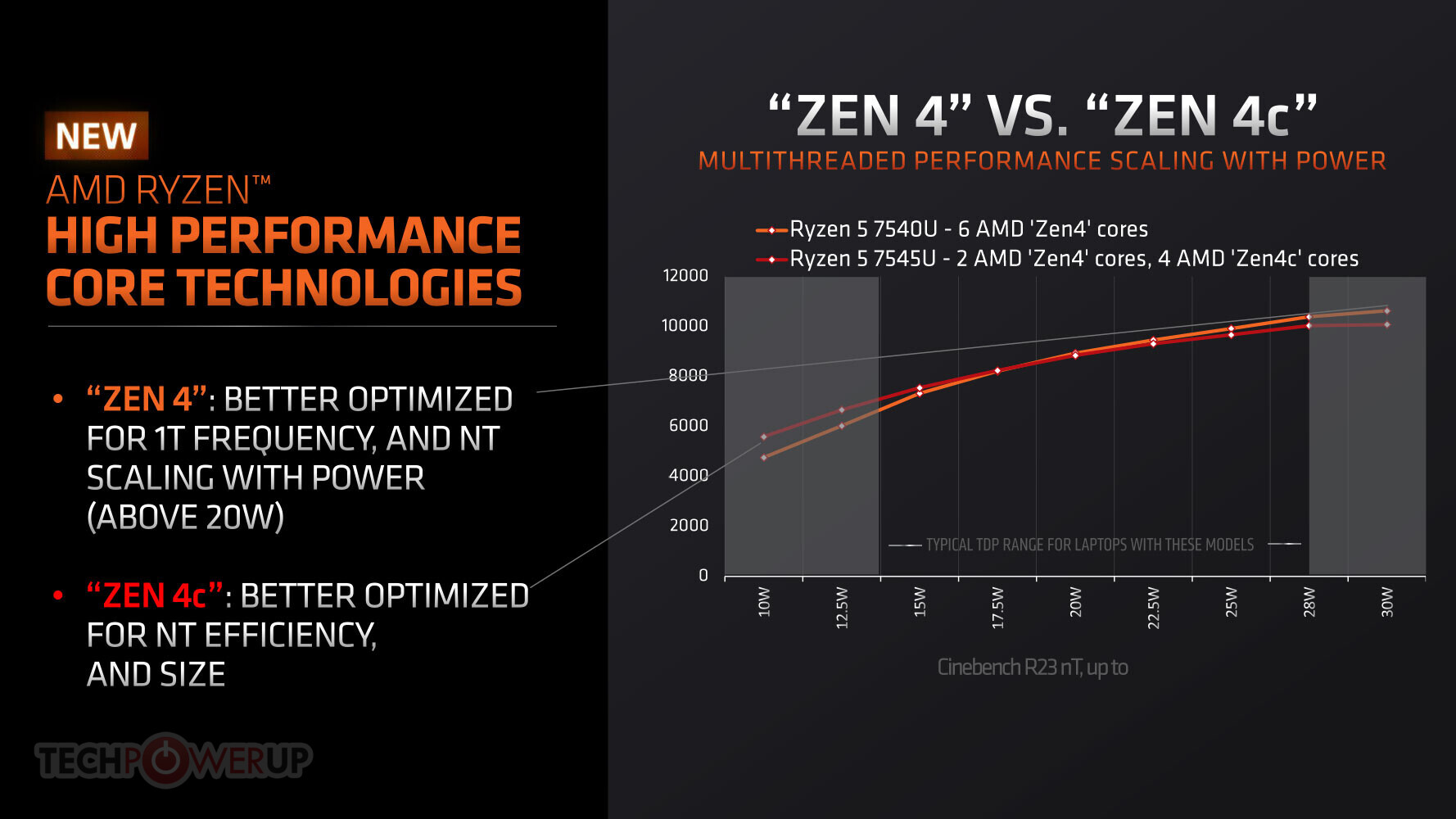
AMD today launched its first client processors that feature the compact "Zen 4c" CPU cores, with the Ryzen 5 7545U and Ryzen 3 7440U mobile processors for thin-and-light notebooks. The "Zen 4c" CPU core is a compacted version of the "Zen 4" core without the subtraction of any hardware components, but rather a high density arrangement of them on the 4 nm silicon. A "Zen 4c" core is around 35% smaller in area on the die than a regular "Zen 4" core. Since none of its components is removed, the core features an identical IPC (single thread performance) to "Zen 4," as well as an identical ISA (instruction set). "Zen 4c" also supports SMT or 2 threads per core. The trade-off here is that "Zen 4c" cores are generally clocked lower than "Zen 4" cores, as they can operate at lower core voltages. This doesn't, however, make the "Zen 4c" comparable to an E-core by Intel's definition, these cores are still part of the same CPU clock speed band as the "Zen 4" cores, at least in the processors that's being launched today.
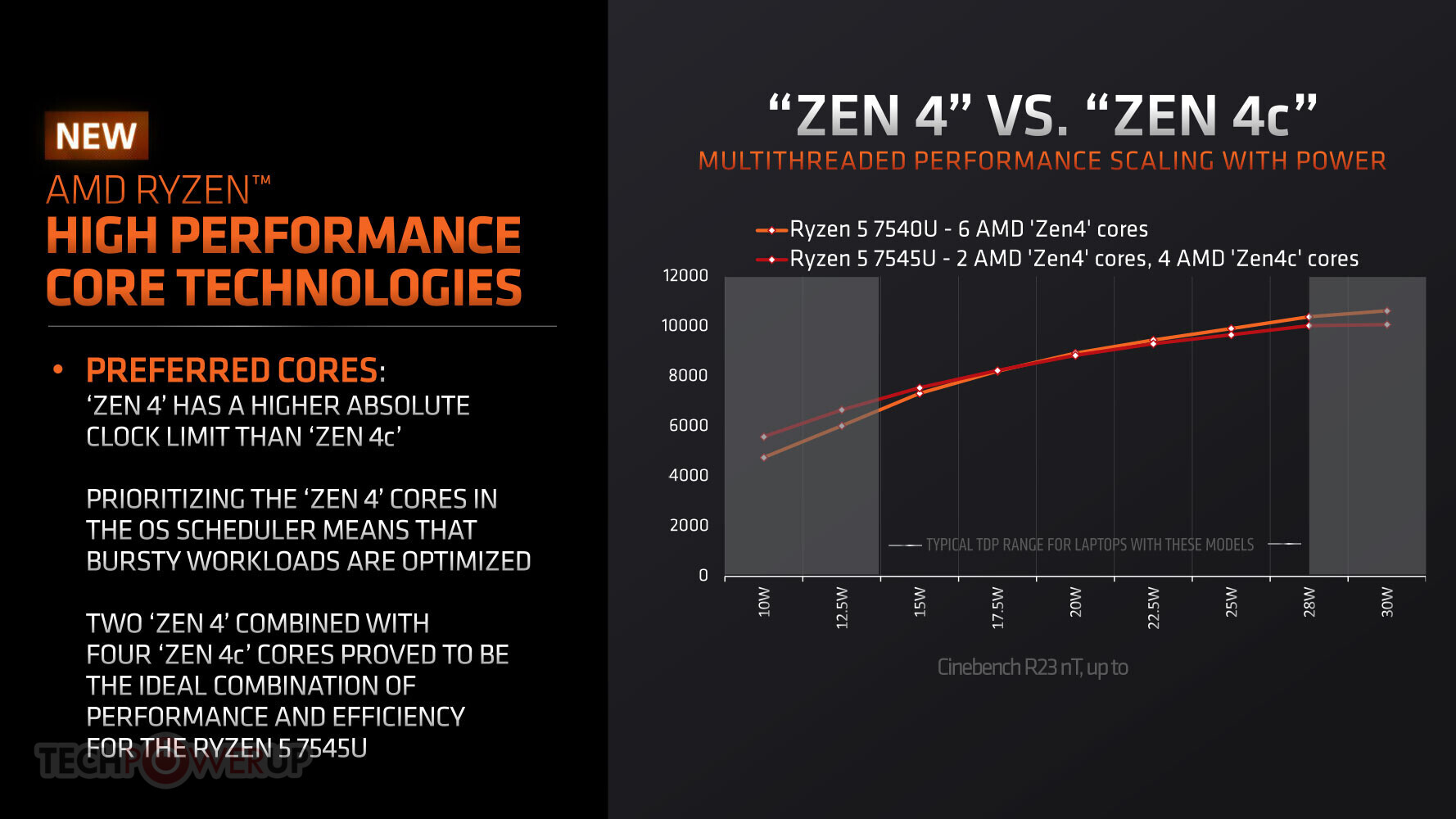
The Ryzen 5 7545U and Ryzen 3 7440U mobile processors formally debut the new 4 nm "Phoenix 2" monolithic silicon. This chip is AMD's first hybrid processor, in that it has a mixture of two regular "Zen 4" cores, and four compact "Zen 4c" cores. The six cores share an impressive 16 MB of L3 cache. All six cores feature 1 MB of dedicated L2 cache. There is no complex hardware-based scheduler involved, but a software based solution that's deployed by AMD's Chipset Software, which tells the Windows scheduler to see the "Zen 4" cores as UEFI CPPC "preferred cores," and prioritize traffic to them, as they can hold on to higher boost frequency bins. The "Phoenix 2" silicon inherits much of the on-die power-management feature-set from the "Phoenix" and "Rembrandt" chips, and so are capable of a high degree of power savings with underutilized CPU cores and iGPU compute units.


 The iGPU of "Phoenix 2" is based on the latest RDNA3 graphics architecture, however it is not exactly built for gaming, it has just enough muscle for a modern Windows 11 experience with animated UI, complex web-pages, and streaming video based on the latest AV1 and HEVC formats. The iGPU packs 4 compute units that add up to 256 stream processors. There are also AI accelerators that are intrinsic to the RDNA3 compute units. A big change with "Phoenix 2" is that it lacks the 16 TOPS XDNA accelerator, and hence both the processor models being launched today lack Ryzen AI.
The iGPU of "Phoenix 2" is based on the latest RDNA3 graphics architecture, however it is not exactly built for gaming, it has just enough muscle for a modern Windows 11 experience with animated UI, complex web-pages, and streaming video based on the latest AV1 and HEVC formats. The iGPU packs 4 compute units that add up to 256 stream processors. There are also AI accelerators that are intrinsic to the RDNA3 compute units. A big change with "Phoenix 2" is that it lacks the 16 TOPS XDNA accelerator, and hence both the processor models being launched today lack Ryzen AI.
As for the chips themselves, the Ryzen 5 7545U maxes out the "Phoenix 2" silicon, enabling all two "Zen 4" and all four "Zen 4c" cores; along with 16 MB of L3 cache, 22 MB of "total cache" (L2+L3), a CPU clock speed of 3.20 GHz base, and 4.90 GHz boost; and a TDP band of 15 W to 30 W. The Ryzen 3 7440U, on the other hand, is a quad-core chip, enabling both "Zen 4" cores, and two out of the four available "Zen 4c" cores. The shared L3 cache is reduced to 8 MB, and hence the total cache is down to 12 MB. The CPU is clocked at 3.00 GHz, with 4.70 GHz maximum boost. The TDP band remains 15 W to 30 W. Both models max out the iGPU with its available 4 compute units; which has the branding Radeon 740M.


 Notebooks based on the Ryzen 5 7545U and Ryzen 3 7440U should begin rolling out now, the two chips mostly cater to entry/mainstream variants of existing thin-and-lights, including some notebooks with mainstream thickness.
Notebooks based on the Ryzen 5 7545U and Ryzen 3 7440U should begin rolling out now, the two chips mostly cater to entry/mainstream variants of existing thin-and-lights, including some notebooks with mainstream thickness.
The complete press-deck follows.


The Ryzen 5 7545U and Ryzen 3 7440U mobile processors formally debut the new 4 nm "Phoenix 2" monolithic silicon. This chip is AMD's first hybrid processor, in that it has a mixture of two regular "Zen 4" cores, and four compact "Zen 4c" cores. The six cores share an impressive 16 MB of L3 cache. All six cores feature 1 MB of dedicated L2 cache. There is no complex hardware-based scheduler involved, but a software based solution that's deployed by AMD's Chipset Software, which tells the Windows scheduler to see the "Zen 4" cores as UEFI CPPC "preferred cores," and prioritize traffic to them, as they can hold on to higher boost frequency bins. The "Phoenix 2" silicon inherits much of the on-die power-management feature-set from the "Phoenix" and "Rembrandt" chips, and so are capable of a high degree of power savings with underutilized CPU cores and iGPU compute units.



As for the chips themselves, the Ryzen 5 7545U maxes out the "Phoenix 2" silicon, enabling all two "Zen 4" and all four "Zen 4c" cores; along with 16 MB of L3 cache, 22 MB of "total cache" (L2+L3), a CPU clock speed of 3.20 GHz base, and 4.90 GHz boost; and a TDP band of 15 W to 30 W. The Ryzen 3 7440U, on the other hand, is a quad-core chip, enabling both "Zen 4" cores, and two out of the four available "Zen 4c" cores. The shared L3 cache is reduced to 8 MB, and hence the total cache is down to 12 MB. The CPU is clocked at 3.00 GHz, with 4.70 GHz maximum boost. The TDP band remains 15 W to 30 W. Both models max out the iGPU with its available 4 compute units; which has the branding Radeon 740M.


The complete press-deck follows.



54 Comments on AMD Introduces Ryzen 5 and Ryzen 3 Mobile Processors with "Zen 4c" Cores
Check out the picture below as well:
They removed the specific boundaries between certain areas - reducing dead space. The lower heat and the reduced interference from reduced clocks makes that easier, but it is mostly just taking a page from the ARM design book. An area where extremely reduced power budgets and thermal constraints are common - servers and smartphones.
They also reduced the SRAM size by using a different type of cell, at the potential cost of bandwidth or latency.
Source: www.semianalysis.com/p/zen-4c-amds-response-to-hyperscale
Incidentally, it appears that the L3 cache per core is actually the same as a standard Zen 4 APU.
Its essentially a big re-floorplanning using a new library with cells, rules, memory compilers (which is what creates the SRAM being used, that can be pulled from Library) all being designed with higher density in mind.
L3 cache for Zen4c core is 1MB, vs 2MB on a normal Zen4, tho correcting what i said, i dont think L3 sits in a Zen core so it wouldnt contribute to area reductions
Capacity for L2/L1 didnt change but the memory design for it did which coinsides with library updates
The high-density layout library means lower maximum clock speeds but also lower power consumption.
During development Zen 4 was divided into many sections so that each team could work on a section without running into another team's space, hence some of the deadspace Zen 4c can eliminate.
The blurring together of sections makes me think that Zen 4c can't start development until Zen 4 is almost finished. If that holds true for Zen 5c and Zen 5, then Zen 5 will beat Zen 5c to market, which means the first products to market can't have a hybrid architecture.
Usually top level floorplan is put together from initial designs (netlists) and shapes of everything and where eveyrthing goes is set with a target total area. Everything then gets fit into that area and all the teams work within the parameters they are given (which is usually a rectilinear shape that their design fits into). The initial floorplanning usually provides margin for anything that could take of area down the line. There is no way for a team to "run into anothers space"
When and if efforts to reduce area are done, then all the worst offenders are usually the ones targeted first for reductions, especially those with extra space, and shapes of hardmacs, etc change to cut area.
There is also possibilities of things being taken out of the hardmacs and put into the top level instead, but that rarely happens.Did the "boundaries" get removed, or did the shapes of specific parts of the design change to fit into the smaller die area better? Just from experience im inclined to think its the latter. Its possible a lot of the previously hardmacro designs were moved/added to another hardmac that was already there, and then the shape adjusted to fit into the area.
Since Raptor Lake, both cores have equivalent instruction sets (and were intended to in Alder as well), and a hardware thread scheduler improves performance: it's a disadvantage for AMD that they do not have one.
Dishonest marketing for a dishonest company, but people will always excuse them...
At same clock, Zen 4 and Zen 4c cores are identical in performance.
At same clock, Intel P-cores and E-cores are not identical in performance.
That's the difference and why Intel needed the Thread Director.
Windows could automatically assign works to highest frequency cores where it assumes to be the highest performance.
It was never applicable against Raptor Lake to begin with.Frequency is not the crux of the matter here but rather topology.They are not identical in performance because of the cache size mismatch. A thread director would be useful even for hybrid chips like the 7950X3D which currently rely on a custom scheduler driver.
Intel's E-cores are derived from a completely different architecture, yes.
The only practical difference is the clockspeed. This is identical to setting preferred CPU cores, like standard desktop models.
I doubt Zen 4c will ever make it to desktop, but maybe Zen 5c will.
I just hope they never use this in CPUs with 8 cores or fewer on desktop.
Take both gaming and productivity crowns with a 48-thread desktop CPU.
The lineage of Intel and AMD's cores is probably why Intel has a dedicated E-core architecture and AMD does not. Bulldozer, Saltwell, Sandy Bridge, and Bobcat; long ago the four CPU microarchitectures lived together in harmony. But everything changed when Sandy Bridge came to market. Bobcat was AMD's first generation little core, the second generation was Jaguar. But when the time came for a third generation AMD had a tiny development budget and the Bulldozer line was going into cheaper and cheaper devices, so the last microarchitecture in its line, Excavator, was actually lean enough to replace the Bobcat line, which AMD did with the release of the Stony Ridge APU.
Since then AMD's Zen line has always had to fill the needs of every CPU AMD sells. But Intel has been updating their little microarchitecture this whole time, so Intel has the flexibility to use both big and little cores. In fact I think the big and little cores Intel used in Lakefield were probably in development before Intel decided to make Lakefield. AMD has only one core today but the density-optimized layout reminds me of Excavator, so AMD's fastest way to make a little core was to density-optimize Zen 4. The fact that TSMC makes AMD processors and ARM processors probably means that AMD has access to better density-optimizing tools than Intel does.
But this could all change tomorrow. Intel is building processors for ARM customers, so Intel has to be investing into better density-optimizing tools. And AMD has more than enough money to build dedicated big and little cores. In the future their approach to big and little cores may look more alike the other.