Tuesday, November 7th 2023

Intel "Emerald Rapids" 8592+ and 8558U Xeon CPUs with 64C and 48C Configurations Spotted
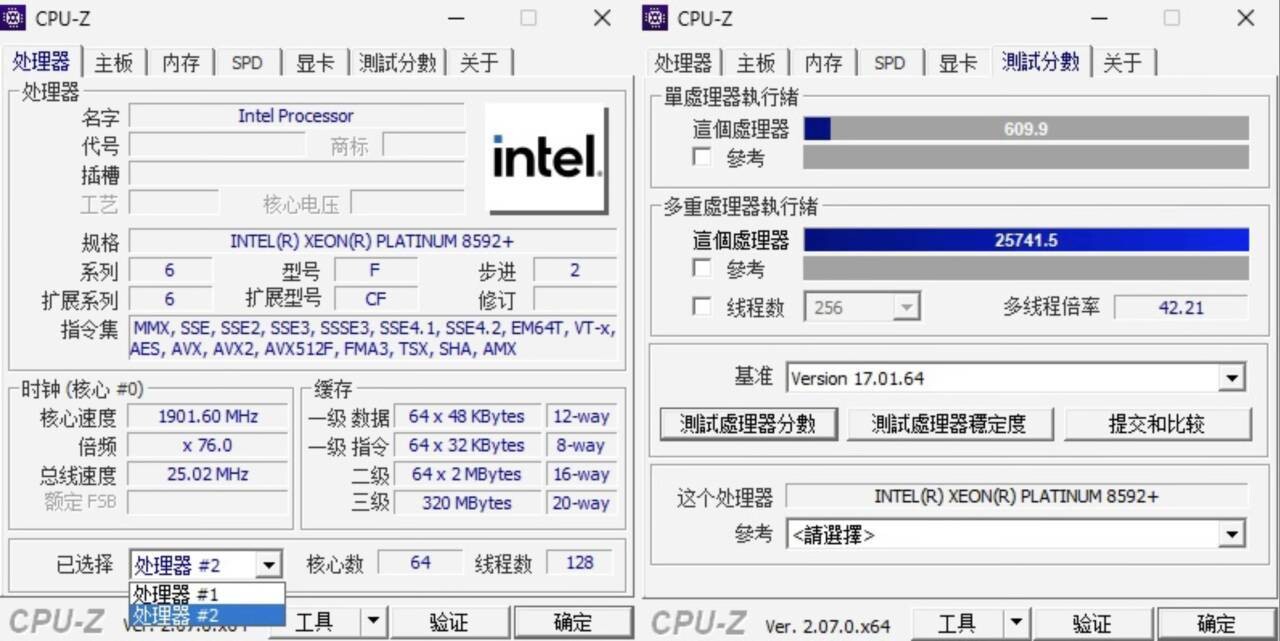
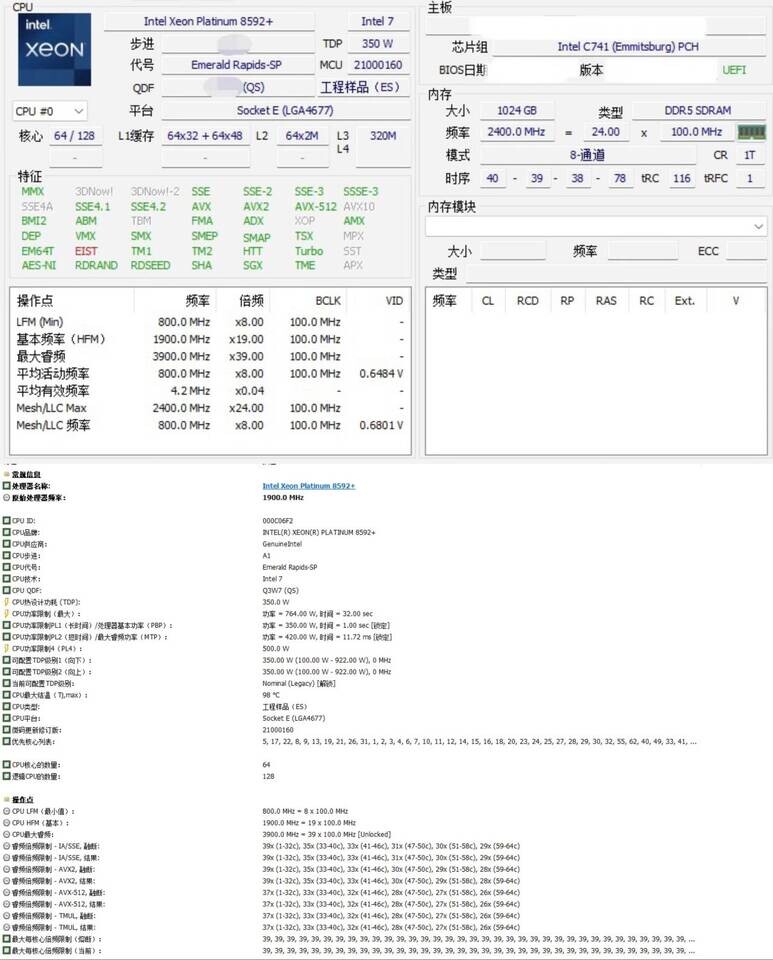
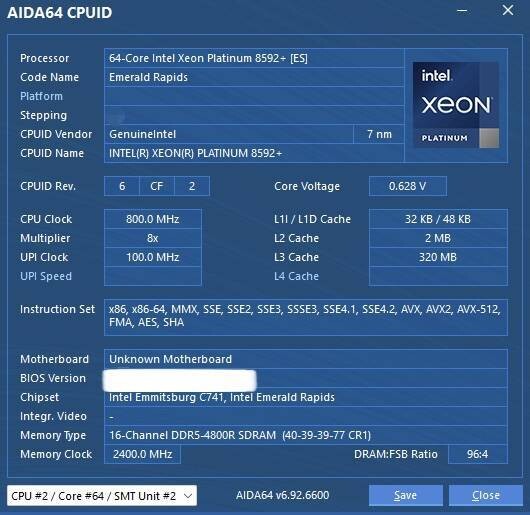
Intel's next-generation Emerald Rapids Xeon lineup is just around the corner, and we are now receiving more leaks as the launch nears. Today, we get to see leaks of two models: a 64-core Xeon 8592+ Platinum and a 48-core Xeon 8558U processor. First is the Xeon 8592+ Platinum, which is possibly Intel's top-end design with 64 cores and 128 threads. Running at the base frequency of 1.9 GHz, the CPU can boost up to 3.9 GHz. This SKU carries 488 MB of total cache, where 120 MB is dedicated to L2 and 320 MB is there for L3. With a TDP of 350 Watts, the CPU can even be adjusted to 420 Watts.
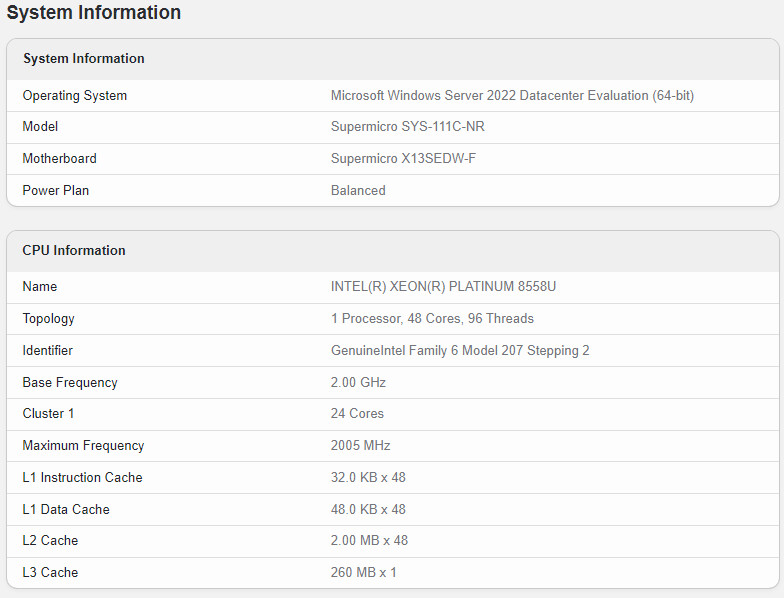
Next up, we have the Xeon 8558U processor, which has been spotted in Geekbench. The Xeon 8558U is a 48-core, 96-threaded CPU with a 2.0 GHz base clock whose boost frequency has yet to be shown or enabled, likely because it is an engineering sample. It carries 96 MB of L2 cache and 260 MB of L3 cache, making for a total of 356 MB of cache (which includes L1D and L1I as well). Both of these SKUs should launch with the remaining models in the Emerald Rapids family, dubbed 5th generation Xeon Scalable, on December 14 this year.




Sources:
@792123a (X/Twitter), Geekbench, via VideoCardz
Next up, we have the Xeon 8558U processor, which has been spotted in Geekbench. The Xeon 8558U is a 48-core, 96-threaded CPU with a 2.0 GHz base clock whose boost frequency has yet to be shown or enabled, likely because it is an engineering sample. It carries 96 MB of L2 cache and 260 MB of L3 cache, making for a total of 356 MB of cache (which includes L1D and L1I as well). Both of these SKUs should launch with the remaining models in the Emerald Rapids family, dubbed 5th generation Xeon Scalable, on December 14 this year.

19 Comments on Intel "Emerald Rapids" 8592+ and 8558U Xeon CPUs with 64C and 48C Configurations Spotted
By now, its not impossible Intel is combining 1st gen P-cores based IMC with 2nd gen and 2nd gen+ in one series.
120 + 320 = 440
Besides it’s probably a misreport on the L2 cache which should be 2MB per core for 128 total. So we are looking at 448 MB of total L2+L3 cache in the 64 core part.
Edit: Look like 80 KB of L1 Cache per core
128+320+5= 453 MB total cache
As for your comment, usually the amounts of cache shown in CPUz is the amount available to the OS and applications. I am not aware of any overhead, provisioning or otherwise hidden cache.
Edit: I should mention that @AleksanderK only made one typo. The 488 should say 448. The 120 typo is carried over from a typo in the original Videocardz article.
INTEL(R) XEON(R) PLATINUM 8558U / 48 Cores, 96 Threads
More seriously, the "U" apparently means a processor without UPI interprocessor links, at least in Sapphire Rapids generation, therefore not able to work in multiprocessor systems.Static RAM, or dynamic RAM for that matter, can't be compared to NAND, which wears out with use. Any defects in RAM must be detected in the chip testing phase, and worked around once and for all, if at all possible. It is not known how Intel and others correct the defects. Maybe they make use of redundant cache lines. The other option is to just tag the defective cache lines and exclude them from use, so you get 35.992 MiB of L3 for the price of 36 MiB. The OS and applications know nothing about that, it's only the cache controller's business.
But ... if there are several defects in the L3 area, it means that there are defects everywhere, and it's nearly impossible for the rest of the chip to be defect-free. So, while it's useful to have a little bit of redundancy and save some nice costly chips from recycling, it's not useful to have a lot of it.
I'm pretty sure the Epyc would be overall better due to it's more efficient design. the sapphire has bin plagued.