Monday, October 13th 2008

Core i7 940 Review Shows SMT and Tri-Channel Memory Let-down
As the computer enthusiast community gears up for Nehalem November, with reports suggesting a series of product launches for both Intel's Core i7 processors and compatible motherboards, Industry observer PC Online.cn have already published an in-depth review of the Core i7 940 2.93 GHz processor. The processor is based on the Bloomfield core, and essentially the Nehalem architecture that has been making news for over an year now. PC Online went right to the heart of the matter, evaluating the 192-bit wide (tri-channel) memory interface, and the advantage of HyperThreading on four physical cores. In the tests, the 2.93 GHz Bloomfield chip was pitted against a Core 2 Extreme QX9770 operating at both its reference speed of 3.20 GHz, and underclocked to 2.93 GHz, so a clock to clock comparison could be brought about.
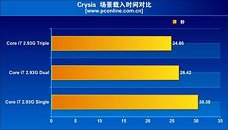
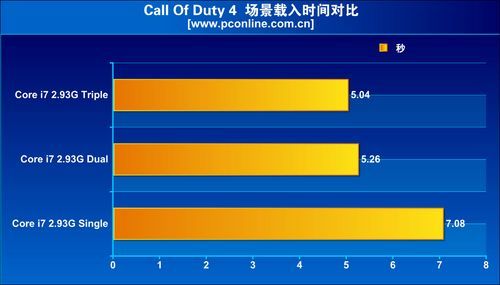
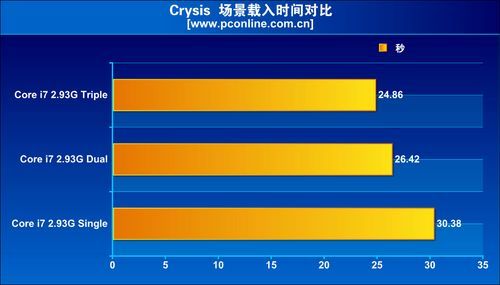
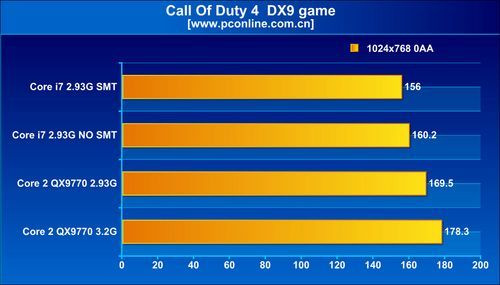
The evaluation found that the performance increments tri-channel offers over dual-channel memory, in real world applications and games, are just about insignificant. Super Pi Mod 1.4 shows only a fractional lead for tri-channel over dual-channel, and the trend continued with Everest Memory Benchmark. On the brighter side, the integrated memory controller does offer improvements over the previous generation setup, with the northbridge handling memory. Even in games such as Call of Duty 4 and Crysis, tri-channel memory did not shine.


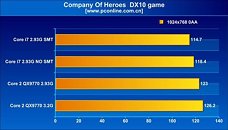
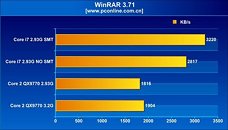
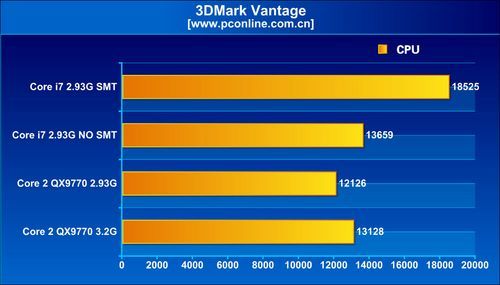
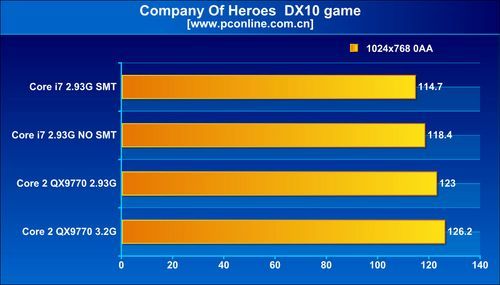
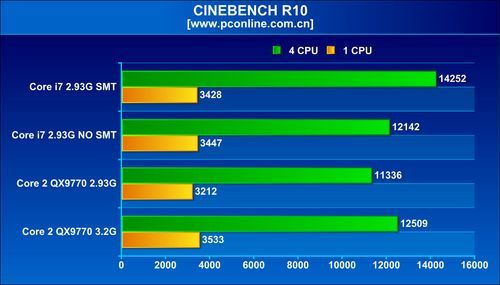
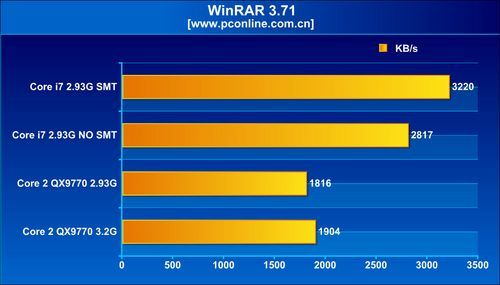
 As for the other architectural change, simultaneous multi-threading, that makes its comeback on the desktop scene with the Bloomfield processors offering as many as eight available logical processors for the operating system to talk to, it appears to be a mixed bag, in terms of performance. The architecture did provide massive boosts in WinRAR and Cinebench tests Across tests, enabling SMT brought in performance increments of roughly 10~20% with general benchmarks that included Cinebench, WinRAR, TMPGEnc, and Fritz Chess. With 3DMark Vantage, SMT provided a very significant boost to the scores, with about 25% increments. It didn't do the same, to current generation games such as Call of Duty 4, World in Conflict and Company of Heroes. What's more, the games didn't seem to benefit from Bloomfield in the first place. The QX9770 underclocked at 2.93 GHz, outperformed i7 940, both with and without SMT, in some games.
As for the other architectural change, simultaneous multi-threading, that makes its comeback on the desktop scene with the Bloomfield processors offering as many as eight available logical processors for the operating system to talk to, it appears to be a mixed bag, in terms of performance. The architecture did provide massive boosts in WinRAR and Cinebench tests Across tests, enabling SMT brought in performance increments of roughly 10~20% with general benchmarks that included Cinebench, WinRAR, TMPGEnc, and Fritz Chess. With 3DMark Vantage, SMT provided a very significant boost to the scores, with about 25% increments. It didn't do the same, to current generation games such as Call of Duty 4, World in Conflict and Company of Heroes. What's more, the games didn't seem to benefit from Bloomfield in the first place. The QX9770 underclocked at 2.93 GHz, outperformed i7 940, both with and without SMT, in some games.



Source:
PC Online
The evaluation found that the performance increments tri-channel offers over dual-channel memory, in real world applications and games, are just about insignificant. Super Pi Mod 1.4 shows only a fractional lead for tri-channel over dual-channel, and the trend continued with Everest Memory Benchmark. On the brighter side, the integrated memory controller does offer improvements over the previous generation setup, with the northbridge handling memory. Even in games such as Call of Duty 4 and Crysis, tri-channel memory did not shine.



91 Comments on Core i7 940 Review Shows SMT and Tri-Channel Memory Let-down
As a side note, do you think triple channel would come in handy on lower speed modules? Say, DDR3 1066 cas7?
Maybe the IMC/memory has little to do with poor Nehalem game performance which reminds me of something else. Nehalem's architecture has strong ties to Pentium 4 w/ Hyperthreading more so than Core 2 architecture. We all remember how Athlon 64 was the better gamer but Pentium 4 w/ Hyperthreading took the cake in terms of multimedia. That pretty much explains everything.
This is how I think it works, just from the clock being use perspective:
Consider the input the external clock generator.
- In DDR a spike is created for every rising and falling edge.
- QDR would create 4 spikes. I don't know how, that's what I'm being asking all the time.
- Note how GDDR5's input clock is twice as fast. A completely different thing would be if the input was 100Mhz and it was doubled inside the memory itself and not externally. That is what I said it would be pointless IMO.
Some references here:
en.wikipedia.org/wiki/Agp
en.wikipedia.org/wiki/Quadruple_data_rate
I can summarize it here though:
SDR = transmits data on the rising edge of each clock
DDR = transmits data on the rising and falling edge of each clock
QDR = uses 2 clock generators, same frequency, one is 90° ahead (or behind) of the other (e.g. clock #1 has a rising edge, then halfway before its falling edge clock #2 has a rising edge). Transmits data on the rising and falling edge of both clocks.
In practice you wouldn't actually use 2 generators but instead delay the second signal by 90° somehow but you get the idea. ODR follows the same sort of pattern except you're using 4 clocks instead of 2.
The 2 clocks 90° apart thing can be hard to visualize so if I have time I'll draw a picture later today. Another way to think of it (maybe easier) is that the falling edge of the clock could be considered to be a clock signal that is 180° behind the original clock. In that case:
SDR = 1 clock 0°
DDR = 2 clocks, 0° and 180°
QDR = 4 clocks, 0°, 90°, 180°, and 270°
ODR = 8 clocks, 0°, 45°, 90°, 135°, etc.
* One of the requirements to convince me is that the advantage of using QDR is not use for memory cell/bank parallelization (like in GDDR5) as that wouldn't be a good solution for main memory.
Anyway IMC indeed helps my point. As I understand it IMC allows for much faster inerconnects between the CPU and the memory, so whenever faster memory (by any method) is available, the bus should be made faster instead of using "multiple instances" of the same one. Am I right or not?
Anyway, why would that matter? As I see it, it doesn't. It would be like saying that in a chain montage, you can't have a product every second because it takes 4 hours to each of them to go from start to finish. It's the production rate which matters, and unless I'm missing something important the same happens in electronics. Besides clock speed limits are constituted by much slower elements, such as the gate's (NAND, NOR...) state change delay, or the delay in transistors state change (one depends on the other really). Following the analogy, we can compare that to the time it takes to fullfill the trailers that will carry the goods to another place.
I understand there are limitations on clock speed, but considering the speeds at which GDDR5 runs, doubling what we have in our mobos several times wouldn't be a problem yet.