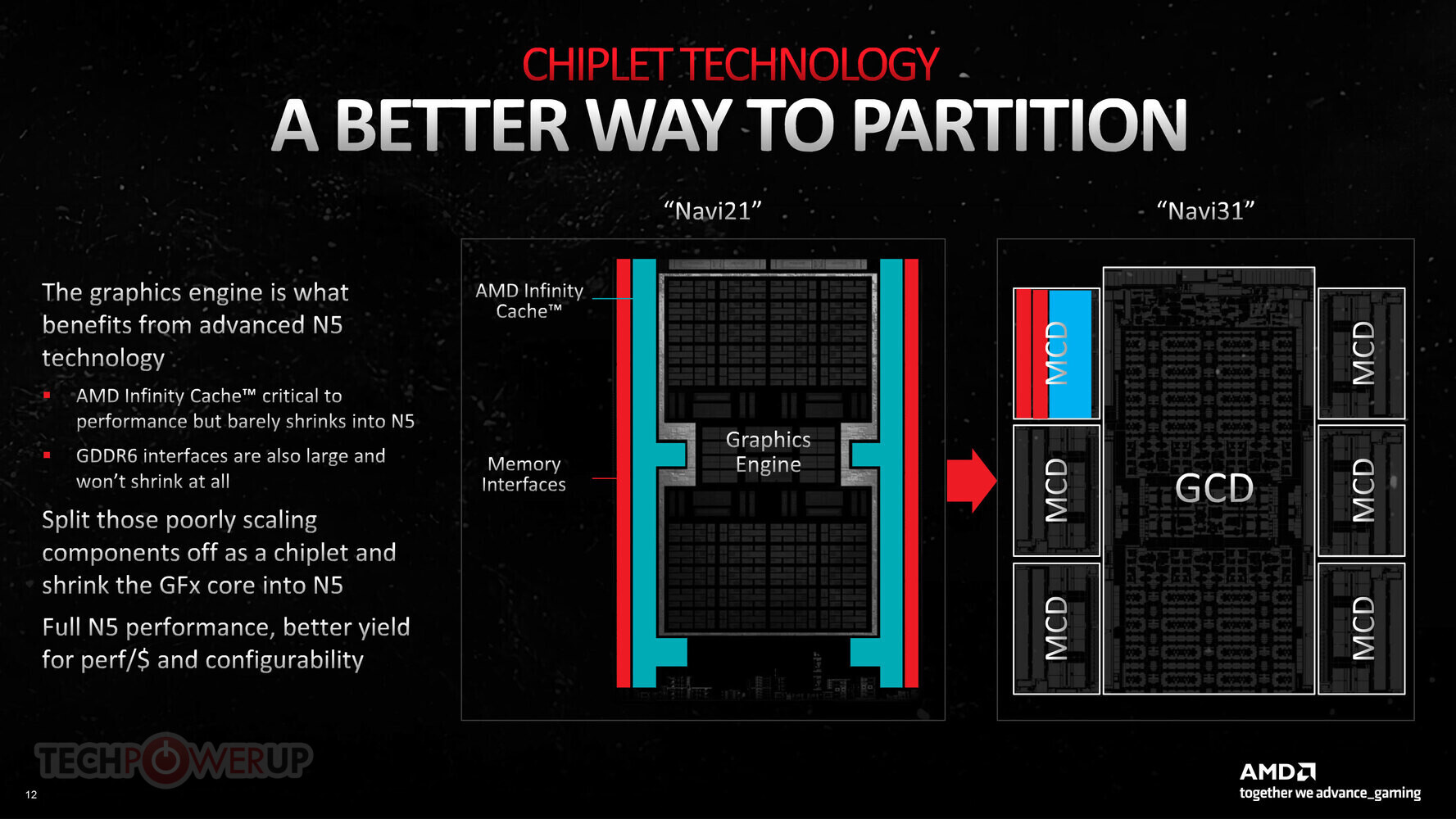
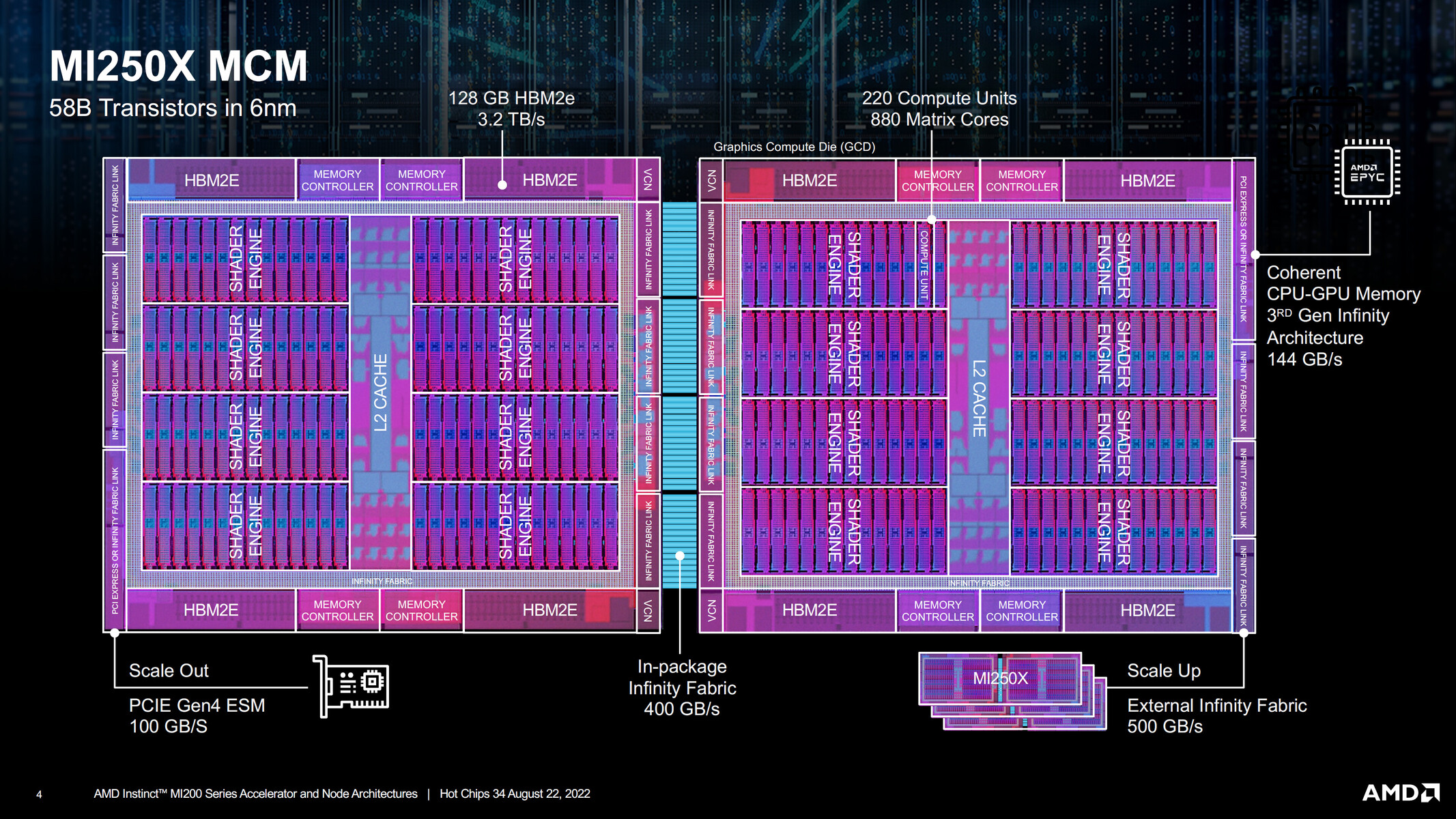
AMD Previews 432 GB HBM4 Instinct MI400 GPUs and Helios Rack‑Scale AI Solution
At its "Advancing AI 2025" event, AMD rolled out its new Instinct MI350 lineup on the CDNA 4 architecture and teased the upcoming UDNA-based AI accelerator. True to its roughly one‑year refresh rhythm, the company confirmed that the Instinct MI400 series will land in early 2026, showcasing a huge leap in memory, interconnect bandwidth, and raw compute power. Each MI400 card features twelve HBM4 stacks, providing a whopping 432 GB of on-package memory and pushing nearly 19.6 TB/s of memory bandwidth. Those early HBM4 modules deliver approximately 1.6 TB/s each, just shy of the 2 TB/s mark. On the compute front, AMD pegs the MI400 at 20 PetaFLOPS of FP8 throughput and 40 PetaFLOPS of FP4, doubling the sparse-matrix performance of today's MI355X cards. But the real game‑changer is how AMD is scaling those GPUs. Until now, you could connect up to eight cards via Infinity Fabric, and anything beyond that had to go over Ethernet.
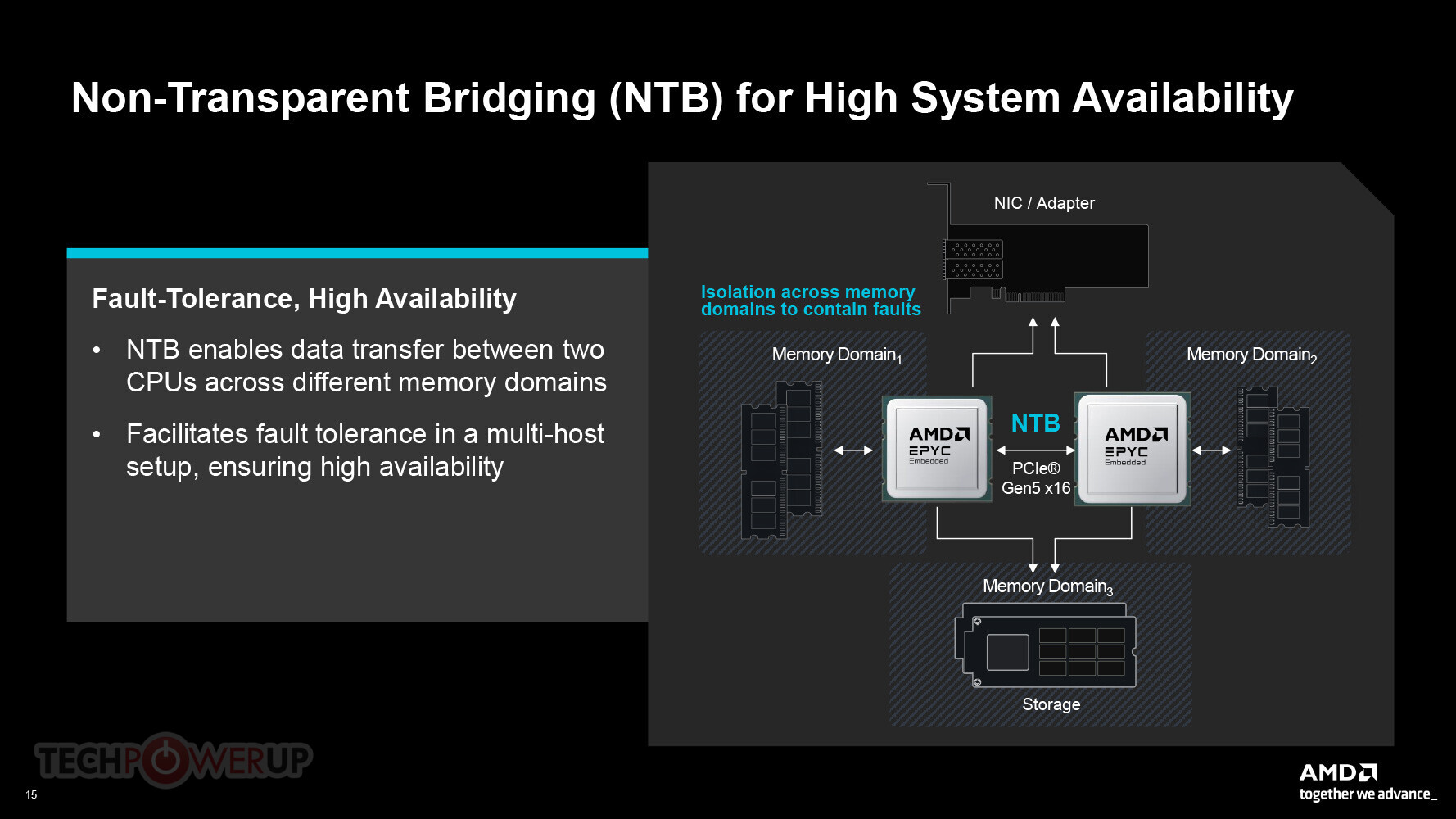
The MI400's upgraded fabric link now offers 300 GB/s, nearly twice the speed of the MI350 series, allowing you to build full-rack clusters without relying on slower networks. That upgrade paves the way for "Helios," AMD's fully integrated AI rack solution. It combines upcoming EPYC "Venice" CPUs with MI400 GPUs and trim-to-fit networking gear, offering a turnkey setup for data center operators. AMD didn't shy away from comparisons, either. A Helios rack with 72 MI400 cards delivers approximately 3.1 ExaFLOPS of tensor performance and 31 TB of HBM4 memory. NVIDIA's Vera Rubin system, slated to feature 72 GPUs and 288 GB of memory each, is expected to achieve around 3.6 ExaFLOPS, with AMD's capabilities surpassing it in both bandwidth and capacity. And if that's not enough, whispers of a beefed‑up MI450X IF128 system are already swirling. Due in late 2026, it would directly link 128 GPUs with Infinity Fabric at 1.8 TB/s bidirectional per device, unlocking truly massive rack-scale AI clusters.



The MI400's upgraded fabric link now offers 300 GB/s, nearly twice the speed of the MI350 series, allowing you to build full-rack clusters without relying on slower networks. That upgrade paves the way for "Helios," AMD's fully integrated AI rack solution. It combines upcoming EPYC "Venice" CPUs with MI400 GPUs and trim-to-fit networking gear, offering a turnkey setup for data center operators. AMD didn't shy away from comparisons, either. A Helios rack with 72 MI400 cards delivers approximately 3.1 ExaFLOPS of tensor performance and 31 TB of HBM4 memory. NVIDIA's Vera Rubin system, slated to feature 72 GPUs and 288 GB of memory each, is expected to achieve around 3.6 ExaFLOPS, with AMD's capabilities surpassing it in both bandwidth and capacity. And if that's not enough, whispers of a beefed‑up MI450X IF128 system are already swirling. Due in late 2026, it would directly link 128 GPUs with Infinity Fabric at 1.8 TB/s bidirectional per device, unlocking truly massive rack-scale AI clusters.