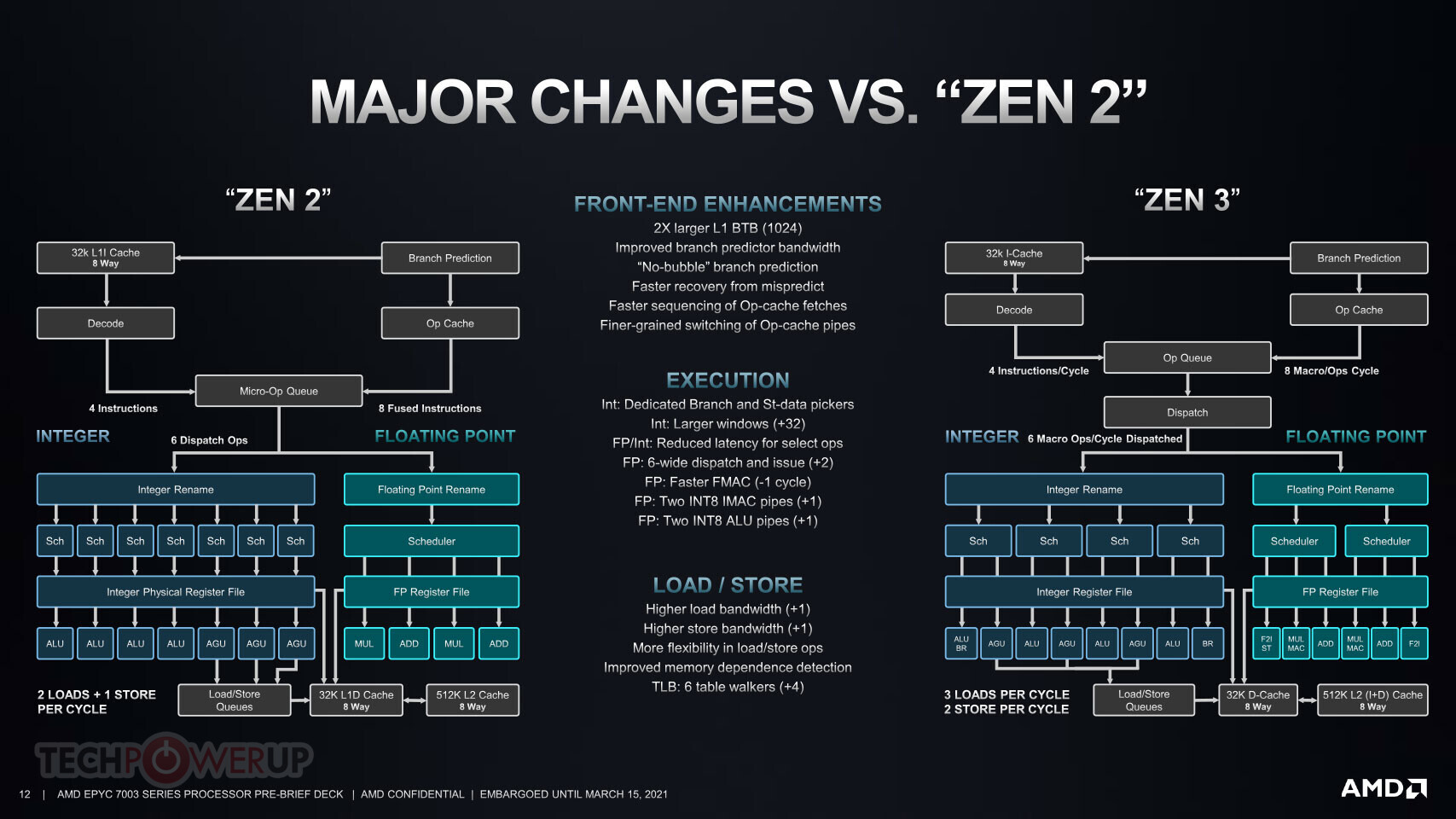
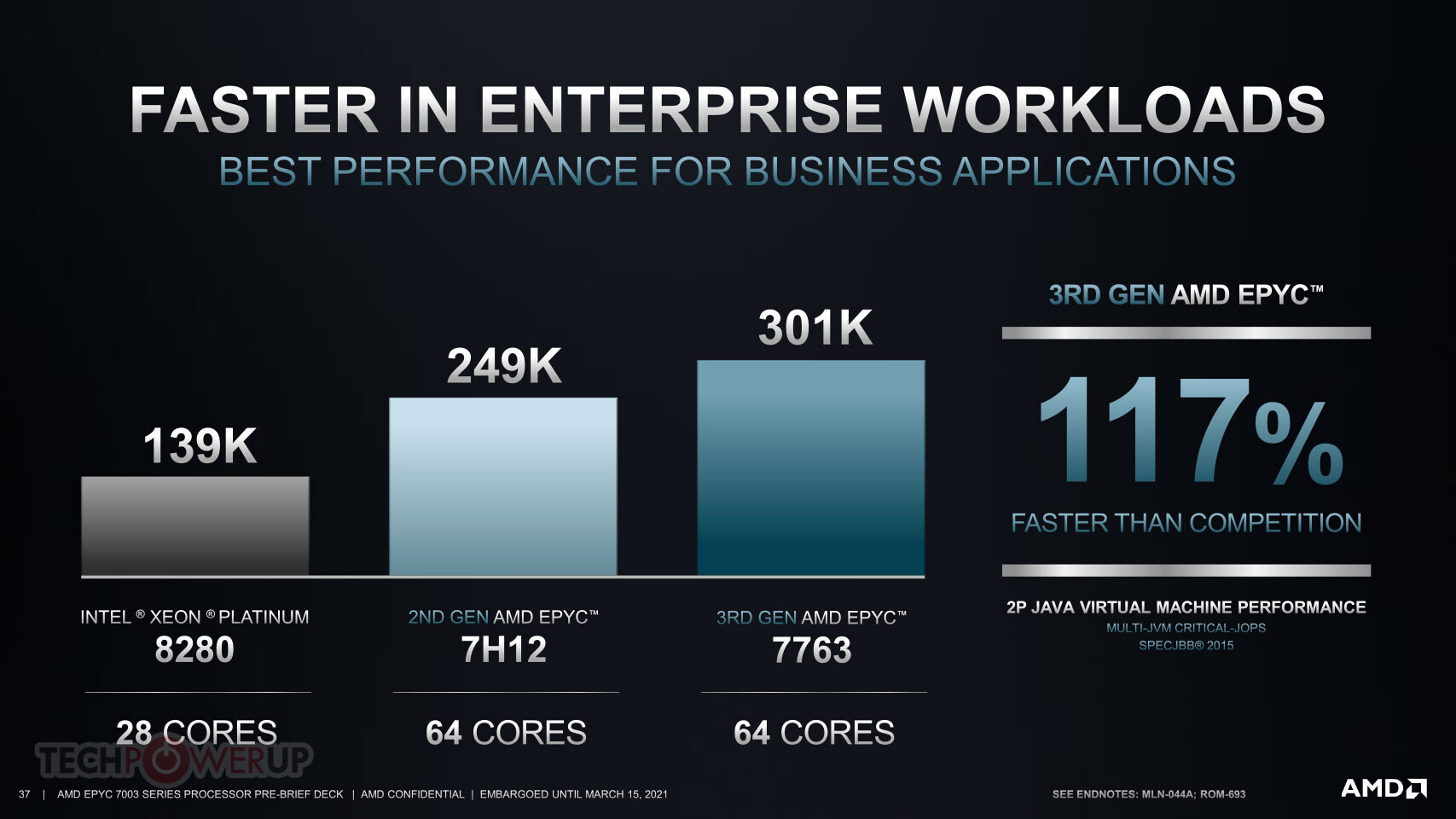
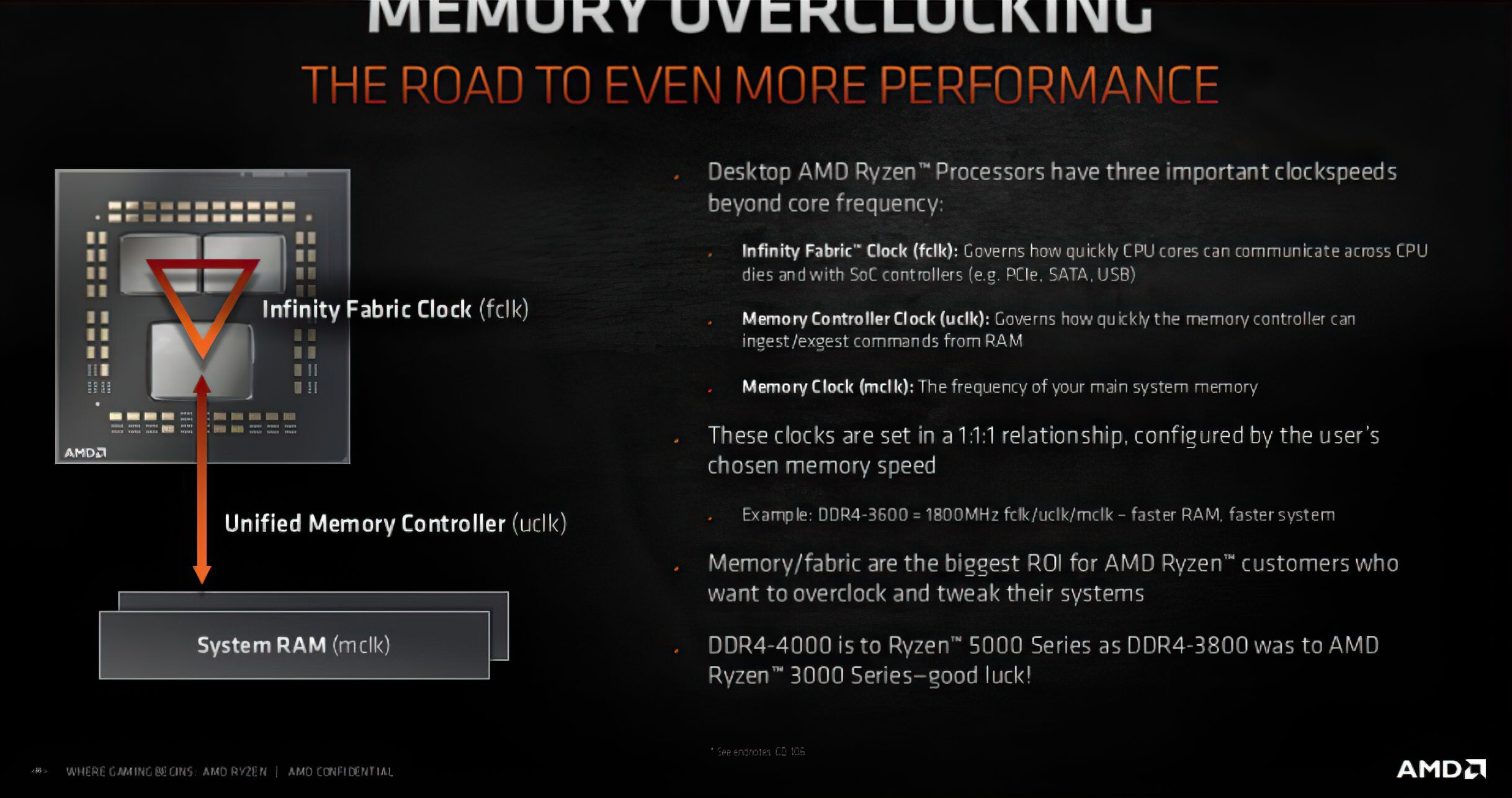
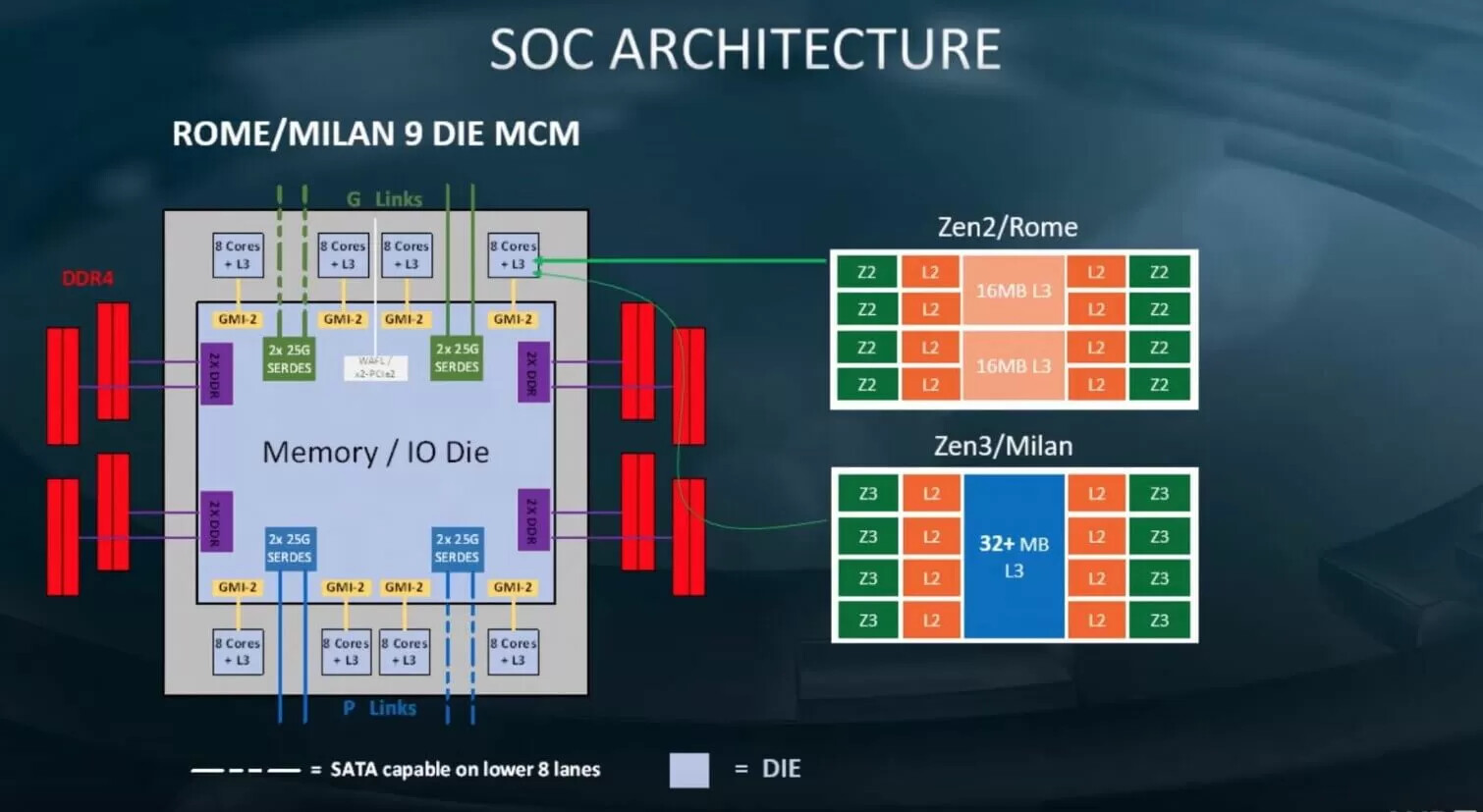
AMD EPYC "Genoa" Zen 4 Processor Multi-Chip Module Pictured
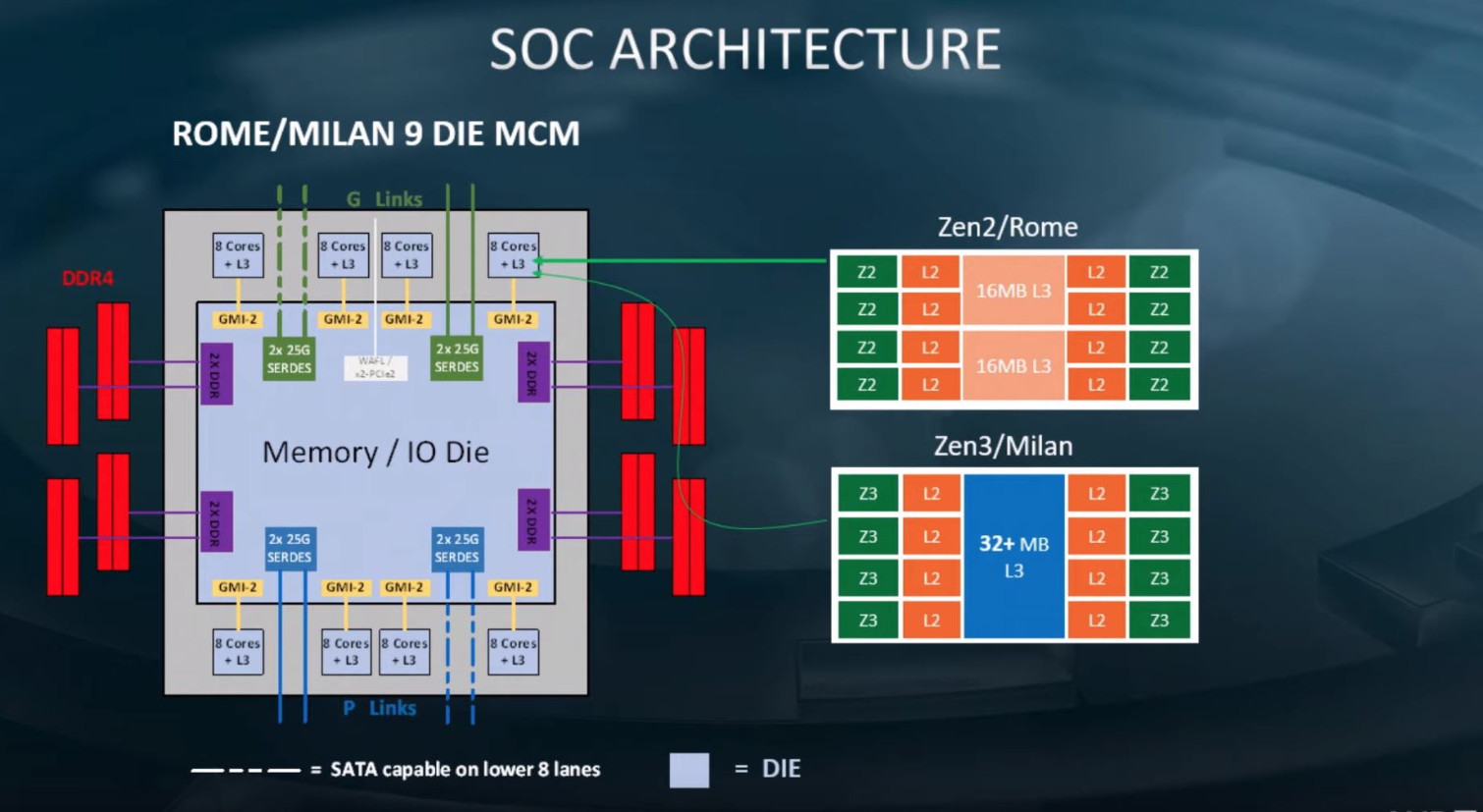
Here is the first picture of a next-generation AMD EPYC "Genoa" processor with its integrated heatspreader (IHS) removed. This is also possibly the first picture of a "Zen 4" CPU Complex Die (CCD). The picture reveals as many as twelve CCDs, and a large sIOD silicon. The "Zen 4" CCDs, built on the TSMC N5 (5 nm EUV) process, look visibly similar in size to the "Zen 3" CCDs built on the N7 (7 nm) process, which means the CCD's transistor count could be significantly higher, given the transistor-density gained from the 5 nm node. Besides more number-crunching machinery on the CPU core, we're hearing that AMD will increase cache sizes, particularly the dedicated L2 cache size, which is expected to be 1 MB per core, doubling from the previous generations of the "Zen" microarchitecture.
Each "Zen 4" CCD is reported to be about 8 mm² smaller in die-area than the "Zen 3" CCD, or about 10% smaller. What's interesting, though, is that the sIOD (server I/O die) is smaller in size, too, estimated to measure 397 mm², compared to the 416 mm² of the "Rome" and "Milan" sIOD. This is good reason to believe that AMD has switched over to a newer foundry process, such as the TSMC N7 (7 nm), to build the sIOD. The current-gen sIOD is built on Global Foundries 12LPP (12 nm). Supporting this theory is the fact that the "Genoa" sIOD has a 50% wider memory I/O (12-channel DDR5), 50% more IFOP ports (Infinity Fabric over package) to interconnect with the CCDs, and the mere fact that PCI-Express 5.0 and DDR5 switching fabric and SerDes (serializer/deserializers), may have higher TDP; which together compel AMD to use a smaller node such as 7 nm, for the sIOD. AMD is expected to debut the EPYC "Genoa" enterprise processors in the second half of 2022.
Each "Zen 4" CCD is reported to be about 8 mm² smaller in die-area than the "Zen 3" CCD, or about 10% smaller. What's interesting, though, is that the sIOD (server I/O die) is smaller in size, too, estimated to measure 397 mm², compared to the 416 mm² of the "Rome" and "Milan" sIOD. This is good reason to believe that AMD has switched over to a newer foundry process, such as the TSMC N7 (7 nm), to build the sIOD. The current-gen sIOD is built on Global Foundries 12LPP (12 nm). Supporting this theory is the fact that the "Genoa" sIOD has a 50% wider memory I/O (12-channel DDR5), 50% more IFOP ports (Infinity Fabric over package) to interconnect with the CCDs, and the mere fact that PCI-Express 5.0 and DDR5 switching fabric and SerDes (serializer/deserializers), may have higher TDP; which together compel AMD to use a smaller node such as 7 nm, for the sIOD. AMD is expected to debut the EPYC "Genoa" enterprise processors in the second half of 2022.