Wednesday, April 8th 2020

x86 Lacks Innovation, Arm is Catching up. Enough to Replace the Giant?
Intel's x86 processor architecture has been the dominant CPU instruction set for many decades, since IBM decided to put the Intel 8086 microprocessor into its first Personal Computer. Later, in 2006, Apple decided to replace their PowerPC based processors in Macintosh computers with Intel chips, too. This was the time when x86 became the only option for the masses to use and develop all their software on. While mobile phones and embedded devices are mostly Arm today, it is clear that x86 is still the dominant ISA (Instruction Set Architecture) for desktop computers today, with both Intel and AMD producing processors for it. Those processors are going inside millions of PCs that are used every day. Today I would like to share my thoughts on the demise of the x86 platform and how it might vanish in favor of the RISC-based Arm architecture.
Both AMD and Intel as producer, and millions of companies as consumer, have invested heavily in the x86 architecture, so why would x86 ever go extinct if "it just works"? The answer is that it doesn't just work. Comparing x86 to Arm
Comparing x86 to Arm
The x86 architecture is massive, having more than a thousand instructions, some of which are very complex. This approach is called Complex Instruction Set Computing (CISC). Internally, these instructions are split into micro-ops, which further complicates processor design. Arm's RISC (Reduced Instruction Set Computing) philosophy is much simpler, and intentionally so. The design goal here is to build simple designs that are easy to manage, with a focus on power efficiency, too. If you want to learn more, I would recommend reading this. It is a simple explanation of differences and what design goals each way achieves. However, today this comparison is becoming pointless as both design approaches copy from each other and use the best parts of each other. Neither architecture is static, they are both constantly evolving. For example Intel invented the original x86, but AMD later added support for 64-bit computing. Various extensions like MMX, SSE, AVX and virtualization have addressed specific requirements for the architecture to stay modern and performing. On the ARM side, things have progressed, too: 64-bit support and floating point math support were added, just like SIMD multimedia instructions and crypto acceleration.
Licensing
Being originally developed by Intel, the x86 ISA is a property of Intel Corporation. To use its ISA, companies such as AMD and VIA sign a licensing agreement with Intel to use the ISA for an upfront fee. Being that Intel controls who can use its technology, they decide who will be able to build an x86 processor. Obviously they want to make sure to have as little competition as possible. However, another company comes into play here. Around 1999, AMD developed an extension to x86, called x86-64 which enables the 64-bit computing capabilities that we all use in our computers. A few years later the first 64-bit x86 processors were released and took the market by storm, with both Intel and AMD using the exact same x86-64 extensions for compatibility. This means that Intel has to license the 64-bit extension from AMD, and Intel licenses the base x86 spec to AMD. This is the famous "cross-licensing agreement" in which AMD and Intel decided to give each other access to technology so both sides have benefits, because it wouldn't be possible to build a modern x86 CPU without both.
Arm's licensing model, on the other hand, is completely different. Arm will allow anyone to use its ISA, as long as that company pays a [very modest] licensing cost. There is an upfront fee which the licensee pays, to gain a ton of documentation and the rights to design a processor based on the Arm ISA. Once the final product is shipped to customers, Arm charges a small percentage of royalty for every chip sold. The licensing agreement is very flexible, as companies can either design their cores from scratch or use some predefined IP blocks available from Arm.
Software Support
The x86 architecture is today's de facto standard for high-performance applications—every developers creates software for it, and they have to, if they want to sell it. In the open source world, things are similar, but thanks to the openness of that whole ecosystem, many developers are embracing alternative architectures, too. Popular Linux distributions have added native support for Arm, which means if you want to run that platform you won't have to compile every piece of software yourself, but you're free to install ready-to-use binary packages, just like on the other popular Linux distributions. Microsoft only recently started supporting Arm with their Windows-on-Arm project that aims to bring Arm-based devices to the hands of millions of consumers. Microsoft already had a project called Windows RT, and its successor, Windows 10 for ARM, which tried to bring Windows 8 editions to Arm CPU.
Performance
The Arm architecture is most popular for low-powered embedded and portable devices, where it can win with its energy-efficient design. That's why high performance has been a problem until recently. For example Marvell Technology Group (ThunderX processors) started out with first-generation Arm designs in 2014. Those weren't nearly as powerful as the x86 alternatives, however, it gave the buyers of server CPUs a sign - Arm processors are here. Today Marvell is shipping ThunderX2 processors that are very powerful and offer comparable performance similar to x86 alternatives (Broadwell and Skylake level performance), depending on the workload of course. Next-generation ThunderX3 processors are on their way this year. Another company doing processor design is Ampere Computing, and they just introduced their Altra CPUs, which should be very powerful as well. What is their secret sauce? The base of every core is Arm's Neoverse N1 server core, designed to give the best possible performance. The folks over at AnandTech have tested Amazon's Graviton2 design which uses these Neoverse N1 cores and came to an amazing conclusion - the chip is incredibly fast and it competes directly with Intel. Something unimaginable a few years ago. Today we already have decent performance needed to compete with Intel and AMD offerings, but you might wonder why it matters so much since there are options already in the form of Xeon and EPYC CPUs. It does matter, it creates competition, and competition is good for everyone. Cloud providers are looking into deploying these processors as they promise to offer much better performance per dollar, and higher power efficiency—power cost is one of the largest expenses for these companies.
What is their secret sauce? The base of every core is Arm's Neoverse N1 server core, designed to give the best possible performance. The folks over at AnandTech have tested Amazon's Graviton2 design which uses these Neoverse N1 cores and came to an amazing conclusion - the chip is incredibly fast and it competes directly with Intel. Something unimaginable a few years ago. Today we already have decent performance needed to compete with Intel and AMD offerings, but you might wonder why it matters so much since there are options already in the form of Xeon and EPYC CPUs. It does matter, it creates competition, and competition is good for everyone. Cloud providers are looking into deploying these processors as they promise to offer much better performance per dollar, and higher power efficiency—power cost is one of the largest expenses for these companies.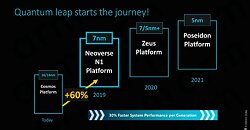 Arm isn't sitting idle, they are doing a lot of R&D on their Neoverse ecosystem with next-generation cores almost ready. Intel's innovation has been stagnant and, while AMD caught up and started to outrun them, it is not enough to keep x86 safe from a joint effort of Arm and startup companies that are gathering incredible talent. Just take a look at Nuvia Inc. which is bringing some of the best CPU architects in the world together: Gerard Williams III, Manu Gulati, John Bruno are all well-known names in the industry, and they are leading the company that is promising to beat everything with its CPU's performance. You can call these "just claims", but take a look at some of the products like Apple's A13 SoC. Its performance in some benchmarks is comparable to AMD's Zen 2 cores and Intel's Skylake, showing how far the Arm ecosystem has come and that it has the potential to beat x86 at its own game.
Arm isn't sitting idle, they are doing a lot of R&D on their Neoverse ecosystem with next-generation cores almost ready. Intel's innovation has been stagnant and, while AMD caught up and started to outrun them, it is not enough to keep x86 safe from a joint effort of Arm and startup companies that are gathering incredible talent. Just take a look at Nuvia Inc. which is bringing some of the best CPU architects in the world together: Gerard Williams III, Manu Gulati, John Bruno are all well-known names in the industry, and they are leading the company that is promising to beat everything with its CPU's performance. You can call these "just claims", but take a look at some of the products like Apple's A13 SoC. Its performance in some benchmarks is comparable to AMD's Zen 2 cores and Intel's Skylake, showing how far the Arm ecosystem has come and that it has the potential to beat x86 at its own game.
Performance-per-Watt disparity between Arm and x86 define fiefdoms between the two. Arm chips offer high performance/Watt in smartphone and tablet form-factors where Intel failed to make a dent with its x86-based "Medfield" SoCs. Intel, on the other hand, consumes a lot more power, to get a lot more work gone at larger form-factors. It's like comparing a high-speed railway locomotive to a Tesla Model X. Both do 200 km/h, but the former pulls in a lot more power, and transports a lot more people. Recent attempts at scaling Arm to an enterprise platform met with limited success. A test server based on a 64-core Cavium ThunderX 2 pulls 800 Watts off the wall, which isn't much different from high core-count Xeons. At least, it doesn't justify the cost for enterprise customers to re-tool their infrastructure around Arm. Enterprise Linux distributions like Novell or RHEL haven't invested too much in scalar Arm-based servers (besides microservers), and Microsoft has no Windows Server for Arm.
Apple & Microsoft
If Apple's plan to replace Intel x86 CPUs in its products realizes, then x86 lost one of the bigger customers. Apple's design teams have proven over the years that they can design some really good cores, the Ax lineup of processors (A11, A12 and most recently A13) is testament to that. The question remains however, how well can they scale such a design and how quickly they can adapt the ecosystem for it. With Apple having a tight grip on its App Store for Mac, it wouldn't be too difficult for them to force developers to ship an Arm-compatible binary, too, if they want to keep their product on App Store.
On the Microsoft Windows side, things are different. There is no centralized Store—Microsoft has tried, and failed. Plenty of legacy software exists that is developed for x86 only. Even major developers of Windows software are currently not providing Arm binaries. For example Adobe's Creative Suite, which is the backbone of the creative industry, is x86 only. Game developers are busy enough learning DirectX 12 or Vulkan, they sure don't want to start developing titles with Arm support, too—in addition to Xbox and Playstation. An exception is the Microsoft Office suite, which is available for Windows RT, and is fully functional on that platform. A huge percentage of Windows users are tied to their software stack for either work or entertainment, so the whole software development industry would need to pay more attention to Arm and offer their software on that platform as well. However, that seems impossible for now. Besides Microsoft Edge, there is not even a 3rd party web-browser available. Firefox is in beta, Google's Chrome has seen some development, but there is no public release. That's probably why Microsoft went with the "emulation" route, unlike Apple. According to Microsoft, applications compiled for the Windows platform can run "unmodified, with good performance and a seamless user experience". This emulation does not support 64-bit applications at this time. Microsoft's Universal Windows Platform (UWP) "Store" apps can easily be ported to run on Arm, because the API was designed for that from the ground up.
Server & Enterprise
The server market is important for x86—it has the best margins, high volume and is growing fast, thanks to cloud computing. Historically, Intel has held more than 95% of server shipments with its Xeon lineup of CPUs, while AMD occupied the rest of that, Arm really played no role here. Recently AMD started the production of EPYC processors that deliver good performance, run power efficient and have good pricing, making a big comeback and gnawing away at Intel's market share. Most of the codebases in that sector should be able to run on Arm, and even supercomputers can use the Arm ISA, where the biggest example is the Fugaku pre-exascale supercomputer. By doing the custom design of Arm CPUs, vendors will make x86 a thing of the past.
Conclusion
Arm-based processors are lower-cost than Intel and AMD based solutions, while having comparable performance, and consuming less energy. At least that's the promise. I think that servers are the first line where x86 will slowly phase away, and consumer products are second, with Apple pursuing custom chips and Microsoft already offering Arm-based laptops.
On the other hand, eulogies of x86 tend to be cyclical. Just when it appears that Arm has achieved enough performance per Watt to challenge Intel in the ultra-compact client-computing segments, Intel pushes back. Lakefield is an ambitious effort by Intel to take on Arm by combining high-efficiency and high-performance cores onto a single chip, along with packaging innovations relevant to ultra-portables. When it comes out, Lakefield could halt Arm in its tracks as it seeks out high-volume client-computing segments such as Apple's MacBooks. Lakefield has the potential to make Apple second-guess itself. It's very likely that Apple's forward-looking decisions were the main reason Intel sat down to design it.
So far, Arm ISA is dominant in the mobile space. Phones manufactured by Samsung, Apple, Huawei and many more feature a processor that has an Arm-based CPU inside. Intel tried to get into the mobile space with its x86 CPUs but failed due to their inefficiency. The adoption rate was low, and some manufacturers like Apple preferred to do custom designs. However, SoftBank didn't pay $31 billion to acquire ARM just so it could eke out revenues from licensing the IP to smartphone makers. The architecture is designed for processors of all shapes and sizes. Right now it takes companies with complete control over their product stack, such as Amazon and Apple, to get Arm to a point where it is a viable choice in the desktop and server space. By switching to Arm, vendors could see financial benefit as well. It is reported that Apple could see reduction in processor prices anywhere from 40% to 60% by going custom Arm. Amazon offers Graviton 2 based instances that are lower-priced compared to Xeon or EPYC based solutions. Of course complete control of both hardware and software comes with its own benefits, as a vendor can implement any feature that users potentially need, without a need to hope that a 3rd party will implement them. Custom design of course has some added upfront development costs, however, the vendor is later rewarded with lower cost per processor.
Both AMD and Intel as producer, and millions of companies as consumer, have invested heavily in the x86 architecture, so why would x86 ever go extinct if "it just works"? The answer is that it doesn't just work.

The x86 architecture is massive, having more than a thousand instructions, some of which are very complex. This approach is called Complex Instruction Set Computing (CISC). Internally, these instructions are split into micro-ops, which further complicates processor design. Arm's RISC (Reduced Instruction Set Computing) philosophy is much simpler, and intentionally so. The design goal here is to build simple designs that are easy to manage, with a focus on power efficiency, too. If you want to learn more, I would recommend reading this. It is a simple explanation of differences and what design goals each way achieves. However, today this comparison is becoming pointless as both design approaches copy from each other and use the best parts of each other. Neither architecture is static, they are both constantly evolving. For example Intel invented the original x86, but AMD later added support for 64-bit computing. Various extensions like MMX, SSE, AVX and virtualization have addressed specific requirements for the architecture to stay modern and performing. On the ARM side, things have progressed, too: 64-bit support and floating point math support were added, just like SIMD multimedia instructions and crypto acceleration.
Licensing
Being originally developed by Intel, the x86 ISA is a property of Intel Corporation. To use its ISA, companies such as AMD and VIA sign a licensing agreement with Intel to use the ISA for an upfront fee. Being that Intel controls who can use its technology, they decide who will be able to build an x86 processor. Obviously they want to make sure to have as little competition as possible. However, another company comes into play here. Around 1999, AMD developed an extension to x86, called x86-64 which enables the 64-bit computing capabilities that we all use in our computers. A few years later the first 64-bit x86 processors were released and took the market by storm, with both Intel and AMD using the exact same x86-64 extensions for compatibility. This means that Intel has to license the 64-bit extension from AMD, and Intel licenses the base x86 spec to AMD. This is the famous "cross-licensing agreement" in which AMD and Intel decided to give each other access to technology so both sides have benefits, because it wouldn't be possible to build a modern x86 CPU without both.
Arm's licensing model, on the other hand, is completely different. Arm will allow anyone to use its ISA, as long as that company pays a [very modest] licensing cost. There is an upfront fee which the licensee pays, to gain a ton of documentation and the rights to design a processor based on the Arm ISA. Once the final product is shipped to customers, Arm charges a small percentage of royalty for every chip sold. The licensing agreement is very flexible, as companies can either design their cores from scratch or use some predefined IP blocks available from Arm.
Software Support
The x86 architecture is today's de facto standard for high-performance applications—every developers creates software for it, and they have to, if they want to sell it. In the open source world, things are similar, but thanks to the openness of that whole ecosystem, many developers are embracing alternative architectures, too. Popular Linux distributions have added native support for Arm, which means if you want to run that platform you won't have to compile every piece of software yourself, but you're free to install ready-to-use binary packages, just like on the other popular Linux distributions. Microsoft only recently started supporting Arm with their Windows-on-Arm project that aims to bring Arm-based devices to the hands of millions of consumers. Microsoft already had a project called Windows RT, and its successor, Windows 10 for ARM, which tried to bring Windows 8 editions to Arm CPU.
Performance
The Arm architecture is most popular for low-powered embedded and portable devices, where it can win with its energy-efficient design. That's why high performance has been a problem until recently. For example Marvell Technology Group (ThunderX processors) started out with first-generation Arm designs in 2014. Those weren't nearly as powerful as the x86 alternatives, however, it gave the buyers of server CPUs a sign - Arm processors are here. Today Marvell is shipping ThunderX2 processors that are very powerful and offer comparable performance similar to x86 alternatives (Broadwell and Skylake level performance), depending on the workload of course. Next-generation ThunderX3 processors are on their way this year. Another company doing processor design is Ampere Computing, and they just introduced their Altra CPUs, which should be very powerful as well.

Performance-per-Watt disparity between Arm and x86 define fiefdoms between the two. Arm chips offer high performance/Watt in smartphone and tablet form-factors where Intel failed to make a dent with its x86-based "Medfield" SoCs. Intel, on the other hand, consumes a lot more power, to get a lot more work gone at larger form-factors. It's like comparing a high-speed railway locomotive to a Tesla Model X. Both do 200 km/h, but the former pulls in a lot more power, and transports a lot more people. Recent attempts at scaling Arm to an enterprise platform met with limited success. A test server based on a 64-core Cavium ThunderX 2 pulls 800 Watts off the wall, which isn't much different from high core-count Xeons. At least, it doesn't justify the cost for enterprise customers to re-tool their infrastructure around Arm. Enterprise Linux distributions like Novell or RHEL haven't invested too much in scalar Arm-based servers (besides microservers), and Microsoft has no Windows Server for Arm.
Apple & Microsoft
If Apple's plan to replace Intel x86 CPUs in its products realizes, then x86 lost one of the bigger customers. Apple's design teams have proven over the years that they can design some really good cores, the Ax lineup of processors (A11, A12 and most recently A13) is testament to that. The question remains however, how well can they scale such a design and how quickly they can adapt the ecosystem for it. With Apple having a tight grip on its App Store for Mac, it wouldn't be too difficult for them to force developers to ship an Arm-compatible binary, too, if they want to keep their product on App Store.
On the Microsoft Windows side, things are different. There is no centralized Store—Microsoft has tried, and failed. Plenty of legacy software exists that is developed for x86 only. Even major developers of Windows software are currently not providing Arm binaries. For example Adobe's Creative Suite, which is the backbone of the creative industry, is x86 only. Game developers are busy enough learning DirectX 12 or Vulkan, they sure don't want to start developing titles with Arm support, too—in addition to Xbox and Playstation. An exception is the Microsoft Office suite, which is available for Windows RT, and is fully functional on that platform. A huge percentage of Windows users are tied to their software stack for either work or entertainment, so the whole software development industry would need to pay more attention to Arm and offer their software on that platform as well. However, that seems impossible for now. Besides Microsoft Edge, there is not even a 3rd party web-browser available. Firefox is in beta, Google's Chrome has seen some development, but there is no public release. That's probably why Microsoft went with the "emulation" route, unlike Apple. According to Microsoft, applications compiled for the Windows platform can run "unmodified, with good performance and a seamless user experience". This emulation does not support 64-bit applications at this time. Microsoft's Universal Windows Platform (UWP) "Store" apps can easily be ported to run on Arm, because the API was designed for that from the ground up.
Server & Enterprise
The server market is important for x86—it has the best margins, high volume and is growing fast, thanks to cloud computing. Historically, Intel has held more than 95% of server shipments with its Xeon lineup of CPUs, while AMD occupied the rest of that, Arm really played no role here. Recently AMD started the production of EPYC processors that deliver good performance, run power efficient and have good pricing, making a big comeback and gnawing away at Intel's market share. Most of the codebases in that sector should be able to run on Arm, and even supercomputers can use the Arm ISA, where the biggest example is the Fugaku pre-exascale supercomputer. By doing the custom design of Arm CPUs, vendors will make x86 a thing of the past.
Conclusion
Arm-based processors are lower-cost than Intel and AMD based solutions, while having comparable performance, and consuming less energy. At least that's the promise. I think that servers are the first line where x86 will slowly phase away, and consumer products are second, with Apple pursuing custom chips and Microsoft already offering Arm-based laptops.
On the other hand, eulogies of x86 tend to be cyclical. Just when it appears that Arm has achieved enough performance per Watt to challenge Intel in the ultra-compact client-computing segments, Intel pushes back. Lakefield is an ambitious effort by Intel to take on Arm by combining high-efficiency and high-performance cores onto a single chip, along with packaging innovations relevant to ultra-portables. When it comes out, Lakefield could halt Arm in its tracks as it seeks out high-volume client-computing segments such as Apple's MacBooks. Lakefield has the potential to make Apple second-guess itself. It's very likely that Apple's forward-looking decisions were the main reason Intel sat down to design it.
So far, Arm ISA is dominant in the mobile space. Phones manufactured by Samsung, Apple, Huawei and many more feature a processor that has an Arm-based CPU inside. Intel tried to get into the mobile space with its x86 CPUs but failed due to their inefficiency. The adoption rate was low, and some manufacturers like Apple preferred to do custom designs. However, SoftBank didn't pay $31 billion to acquire ARM just so it could eke out revenues from licensing the IP to smartphone makers. The architecture is designed for processors of all shapes and sizes. Right now it takes companies with complete control over their product stack, such as Amazon and Apple, to get Arm to a point where it is a viable choice in the desktop and server space. By switching to Arm, vendors could see financial benefit as well. It is reported that Apple could see reduction in processor prices anywhere from 40% to 60% by going custom Arm. Amazon offers Graviton 2 based instances that are lower-priced compared to Xeon or EPYC based solutions. Of course complete control of both hardware and software comes with its own benefits, as a vendor can implement any feature that users potentially need, without a need to hope that a 3rd party will implement them. Custom design of course has some added upfront development costs, however, the vendor is later rewarded with lower cost per processor.
217 Comments on x86 Lacks Innovation, Arm is Catching up. Enough to Replace the Giant?
Except, that is not how it happened: they've evaporated after x86 servers (on the same process!) started beating the crap out of them.
x86 Desktop chips and x86 Server chips have the same core. The x86 Server chips mainly differ in "uncore", the way the chip is tied together (allowing for multi-socket configurations). Because x86 Desktop chips have a high-volume, low-cost part, Intel was able to funnel more effort into R&D to make x86 Desktops more and more competitive. x86 Servers benefited, using a similar core design.
That is to say: x86 Servers achieved higher R&D numbers, and ultimately better performance, thanks to the x86 Desktop market.
--------------
A similar argument could be made for these Apple-ARM chips. Apple has achieved higher R&D numbers compared to Intel (!!), because of its iPad and iPhone market. There's a good chance that Apple's A12 core is superior to Intel's now. We don't know for sure until they scale it up, but it wouldn't be surprising to me if it happened.
Another note: because TSMC handled process tech, while Apple handles architecture, the two halves of chip design have separate R&D Budgets. Intel is competing not only against Apple, but against the combined R&D efforts of TSMC + Apple. TSMC is not only funded through Apple's mask costs, but also through NVidia, AMD, and Qualcomm's efforts. As such, TSMC probably has a higher process-level R&D budget than Intel.
Its a simple issue of volume, and money. The more money you throw into your R&D teams, the faster they work. (assuming competent management).
But once the product comes out, why would anyone pay the same money for a product that's 5% slower? The die-size is the main variable regarding the of the cost of the chip. (The bigger the die, the square of simple errors builds up. It also costs more space on the wafer, leading to far fewer chips sold). The customer would rather have the product that's incrementally better at the same price.
Take NVidia vs AMD, they're really close, but NVidia has a minor improvement in performance/watt, and that's what makes all the difference in marketshare.
It would apply if RISC CPUs were faster, but more expensive. They used to be faster. At some point they have become slower.
I am not buying "but that's because of R&D money" argument.
As for having savings in the server market, by selling desktop chips: heck, just have a look at AMD. The market is so huge, you can have decent R&D while having only tiny fraction of the market.
The whole "RISC beats CISC" was largely based on CISC being much harder to scale up by implementing multiple ops ahead, at once, since instruction set was so rich. But hey, as transistor counts went up, suddenly it was doable, on the other hand, RISCs could not go much further ahead in the execution queue, and, flop, no RISCs.
And, curiously, no EPIC took off either.
www.firstpost.com/tech/news-analysis/the-future-of-pcs-is-in-apples-arms-now-heres-why-8554331.html
;)
VLIW is an interesting niche between SIMD and traditional CPUs. Its got more FLOPs than traditional, but more flexibility than SIMD (but less FLOPs than SIMD). For the most part, today's applications seem to be SIMD-based for FLOPs, or Traditional for flexibility / branching. Its hard to see where VLIW will fit in. But its possible a new niche is carved out in between the two methodologies.
wccftech.com/first-arm-macbook-799-price-tag-macbook-pro-more-expensive/
What SIMD does better is register allocation. You can run a constantly changing execution mask to schedule work, vectors do it in a different way with no-op masks but full thread group wide. I think it is like running a seperate frontend inside the compiler. It is a clever idea to not leave any work to the gpu compiler. If you can run a computer simulation, this is where the hardware needs some resource management. Perhaps, future gpus can automatically unroll such untidy loops to always shuffle more active threads in a thread group to find the best execution mask for a given situation. Scalarization frees you from that. You stop caring about all available threads and look at maximally retired threads.
There is definitely an artistic element to it.
I'm not saying it's impossible, they may lower the price if the laptop requires a couple of these to start: www.engadget.com/apple-braided-thunderbolt-3-cable-129-092133733.html
But opcode 0x1 is "Floating-point 32-bit Add" in GCN 1.2 (aka: Polaris / 400-series / 500-series.)
This sort of change requires a recompile. A summary of the opcode changes between GCN 1.0 and 1.2 can be found here: clrx.nativeboinc.org/wiki2/wiki/wiki/GcnInstrsVop2
This dramatic change in opcodes requires a recompile. Surely the reason you suggest is mistaken. Both AMD and NVidia regularly change the hardware assembly language associated with their GPUs regularly, without much announcement either. Indeed, that's why NVidia has PTX, so that they can have an assembly-like language that retargets many different machines (be it Pascal, Volta, or Turing).
I think making a super-fast ARM will be an issue as it's a complicated business once you get to the very high performance area. However software issues are as much of a pain (i.e. making best use of the hardware someone has). Apple could be helped here by having less combinations.
The x86 instruction set is best thought of as a compressed RISC instruction set, so you get better use out of memory, memory bandwidth and caches. That's a plus. (Although ARM seem to sometimes add new instruction sets on Tuesdays... well -ish.)
ARM is a teeny company, it would be "interesting" if someone unexpected bought them out of petty cash and changed the business model completely (it's not like they make so much money it would be a big dent). BTW I considered using a PA-Risc CPU back in the day, remember them... unfortunate for some... (Apple bought them and killed the CPU line.) I believe Apple has an "Architecture" ARM license, which if open-ended (date-wise) would certainly help with any ARM issues.
It's been a long time since Intel last did anything extremely clever (Pentium 4 BTW). Can they make a big jump again? (Plus this time not be screwed by the process technology not hitting the promised 7-8GHz and taking too much power. Although strictly some parts were double clocked so going that fast.)
Final thought - how much better would it be not to spend a ton of effort on the CPU's internal architecture but to speed everything that's an actual roadblock up, especially the off-chip stuff? ( E.g. more memory and I/O interfaces.) Is having a ton of chip-PCB contacts and a few extra PCB layers that much of an issue at the high end of PCs these days? (Me and Seymour, separated at birth...)
*** Oh, my posts got combined, this was supposed to be a completely separate answer to one thing, sorry...Note I edited the second part of this answer as I wrote it super-quickly and combined some stuff. Hopefully it's more correct now. The stuff above this line hasn't been changed.
x86 used to be CISC. Following some analysis (this is the very short version) of compilers it was found they used very few of the instructions (less true today BTW). So some groups tried to make CPUs just executing those instructions, but doing it very quickly (and often very messily, but that's another story). These out-performed the contemporary CISC CPUs (e.g. 386, 68030). This led to WindowsNT supporting several of them (so you could run full/standard WinNT on a DEC Alpha, for example).
Intel's (really excellent BTW) solution was the 486. This was a RISC-ish x86 (edit IMHO). It worked by reading the CISC instructions from memory and (edit) executing the simple ones in a single clock (I cocked this up in the first pass as I wrote this reply way too quickly and combined two generations, apologies). This boosted x86 processing speed up to the same territory as the RISC chips, who declined after that. Also WinNT became x86 only.
Aside - I was looking at designing a board using the Fairchild Clipper RISC chip. (IMHO the only one with a complete and sophisticated architecture - the patents made a lot of money for many years after the chips stopped production, as everyone used the technology.) This beat-up the previous Intel 386 chip very well, but the 486 came along and was a problem for it, so the project died (probably a good idea, O/S licencing for RISC was a nightmare back then). (The Clipper also suffered from Fairchild's process technology, with the caches in separate chips.)
Anyway all x86 for a long time have RISC cores (edit, but the next big change was somewhat later converting all instructions to micro-ops) and basically use the x86 instruction set as a compressed instruction set, so you can store more work in less bytes of memory, requiring less memory fetches and less cache space to store the same amount of functionality. The RISC chips would need more space all through the system due to using larger instruction (BTW ARM's later Thumb set of alternate instructions was intended to shrink the instruction size). As processor speed gets so far ahead of external memory speed (where is can take vast numbers of clocks to do a memory fetch) this is even more important. Of course the catch is you need some very clever instruction decoders for x86, but that has had vast amounts of work optimising it.
The original ARM CPU was mostly interesting as, following on from path of the Mostek 6502, Acorn designed a simple instruction set (with some annoyances) and used a minimal number of transistors in the design, when most others were using lots more. This kept the chip price well down, plus also allowed a low enough complexity for them to actually design a working CPU. (The 6502 was probably the biggest early home computing CPU, it was an 8-bit microprocessor designed with a lot less transistors than its competition, so was noticeably cheaper back when CPUs were really expensive - Acorn, the A in ARM, used the 6502 in their BBC and Electron computers.)
The big problem with the ARM CPUs was, IMHO, the instruction set wasn't great, so they've been adding assorted stuff ever since (e.g. Thumb, basically a complete different set of instructions).
The brilliant thing about ARM (over time) is they licensed it cheaply and at levels down to the gates, the synthesis files or the architecture (no-one else would give you that sort of stuff - well, Intel let AMD make exact x86 copies for a while back when the market was a lot smaller). People loved it. The down-side is they weren't making billions selling chips so are a much much smaller company, even now, than most people realise. (It is a bit of a risk that someone awkward could buy them.)
CPUs themselves are not really RISC because the ISA you are using is x86 which is classically CISC. However, the stuff happening in execution units is not (always) x86 instructions but a different set of operations that is much closer to RISC. Much closer because there are clearly some operations in hardware that would not fit the classical RISC definitions for being too complex.
A hybrid, much like everything these days. At the same time, ARM has been extended considerably over the years and would likely not completely fit in the classical narrow RISC definition. For example think about any extended instruction sets like VFP or Neon.
Edit:
So, why keep x86? All the existing software is definitely one thing. x86 itself is another - it is a stable and mature ISA. You could think of x86 CPUs today as a sort of virtual machines - they take in x86 instructions and execute them however they want while outputting stuff you'd expect from x86. This is probably not feasible in the exact described way by interpreting or translating instructions (Transmeta comes to mind from while ago and ARM x86 layers from recent times) because of the huge performance hit but when that change is embedded in the microarchitecture itself, if there even is any speed penalty it does not outweigh the mature ISA and ready-made software.
By the way, Nvidia is doing something similar in GPU space. All the close-to-metal stuff like drivers use PTX ISA that purportedly is the one GPUs execute. That... just is not the case. PTX is a middle layer between hardware and anything else and PTX is translated into whatever GPU actually does. I bet that is exactly what is behind their relatively stable drivers as well.
A good video to watch shedding some light from the architect point would be Lex Fridman interviewing the man Jim Keller.
Keller is clear of speech ,direct and intellectually stimulating and has an engineer's way with words, he makes it quite clear what the realities of it are.
"Microcode" is far more complex than RISC or CISC. I dare say the RISC vs CISC issue is dead, neither ARM, x86, nor RISC-V (ironically) follow RISC or CISC concepts anymore. ARM has highly specialized instructions like AES-encode. Heck, all architectures do. All instruction sets have single-uops that cover very complicated SIMD concepts.
From x86's perspective: the only thing that "microcode" does these days is convert x86's register-memory architecture into a load/store architecture. PEXT / PDEP on Intel are single microops (executing in one clock tick). I guess division and vgather remain as a sequence of microcode... but the vast majority of x86's instruction set is implemented in one uop.
Case in point: the entire set of x86 "LEA" instructions is implemented as a singular micro-op (I dare you to tell me that LEA is RISC). Furthermore, some of x86's instruction pairs are converted into one uop. (Ex: cmp / jz pairs are converted into one uop). Mind you, ARM follows in x86's footsteps here. (AESE / AESMC are fused together in most ARM cores today: two instructions become one uop for faster performance)
----------
Load/Store is the winner, which is a very small piece of the RISC vs CISC debate. The CISC concept of creating new instructions whenever you want to speed up applications (PDEP, PEXT on x86. ARM's AESE, AESD. SIMD-instructions. AVX512. Etc. etc.) is very much alive today. Modern cores have take the best bits of RISC (which as far as I can tell, is just the load/store architecture), as well as many concepts from CISC.
Case in point: FJCVTZS leads to far faster Javascript code on ARM systems. (Floating point Javascript convert to Signed Fixed Point). Yeah, an instruction invented to literally make Javascript code faster. And lets not forget about ARM/Jazelle either (even though no one uses Jazelle anymore, it was highly popular in the 00s on ARM devices. Specific instructions that implement Java's bytecode machine, speeding up Java code on ARM)
This is weird, as I didn't think the 486 being a RISC core executing decoded CISC instructions (edit - note this only applies to the simple instructions, not the whole instruction set) was news to anyone...
The performance step from 386 to 486 was very large due to this, 2 clock instructions down to 1.
Pentium Pro was the next big step as it was super-scalar (well, to a modest degree, plus that means whoever owned the Clipper patents then made a few more bob) and allowed out-of-order instruction execution, with in-order retirement. Also registers ceased to be physical. In the P54C (its predecessor, ran at 100MHz) the EAX register was a particular bunch of flip-flops. In the P6 it could be any one of a pool of registers at a particular time and somewhere else a fraction of a second later.
I was amazed they could make that level of complexity work. Although at only 60-66MHz. Also quite pleased that my P54C board was usually faster than my colleagues P6 board. (Partly as you needed the compilers optimised for the P6, which they weren't.)
arxiv.org/pdf/1804.06826.pdf
This article gives you an idea of what Volta's actual assembly language is like. Its pretty different from Pascal. Since NVidia changes the assembly language very few generations, its better to have compilers target PTX, and then have PTX recompile to the specific assembly language of a GPU.
It has never been addressed. Actually, quite the opposite - Intel pursues ultra power with the hungry 10900KS, 9900KS, etc, with 200-watt and higher power consumption.
Today, you can use a smartphone with negligible power consumption and running on its battery for days, instead of a power-hungry office PC.