Tuesday, March 12th 2024

Qualcomm Snapdragon X Elite Benchmarked Against Intel Core Ultra 7 155H
Qualcomm Snapdragon X Elite is about to make landfall in the ultraportable notebook segment, powering a new wave of Windows 11 devices powered by Arm, capable of running even legacy Windows applications. The Snapdragon X Elite SoC in particular has been designed to rival the Apple M3 chip powering the 2024 MacBook Air, and some of the "entry-level" variants of the 2023 MacBook Pros. These chips threaten the 15 W U-segment and even 28 W P-segment of x86-64 processors from Intel, such as the Core Ultra "Meteor Lake," and Ryzen 8040 "Hawk Point." Erdi Özüağ, prominent tech journalist from Türkiye, has access to a Qualcomm-reference notebook powered by the Snapdragon X Elite X1E80100 28 W SoC. He compared its performance to an off-the-shelf notebook powered by a 28 W Intel Core Ultra 7 155H "Meteor Lake" processor.
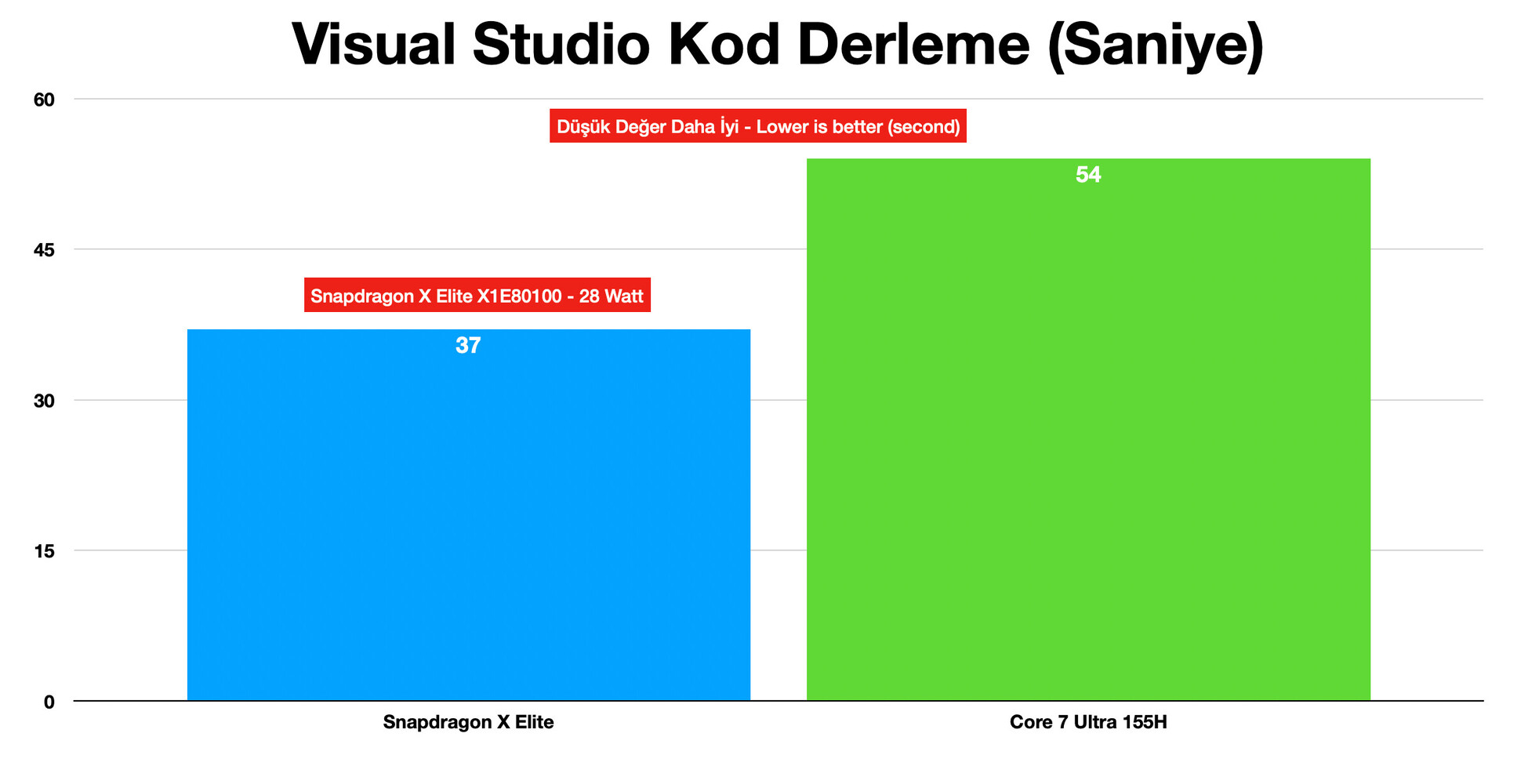
There are three tests that highlight the performance of the key components of the SoCs—CPU, iGPU, and NPU. A Microsoft Visual Studio code compile test sees the Snapdragon X Elite with its 12-core Oryon CPU finish the test in 37 seconds; compared to 54 seconds by the Core Ultra 7 155H with its 6P+8E+2LP CPU. In the 3DMark test, the Adreno 750 iGPU posts identical performance numbers to the Arc Graphics Xe-LPG of the 155H. Where the Snapdragon X Elite dominates the Intel chip is AI inferencing. The UL Procyon test sees the 45 TOPS NPU of the Snapdragon X Elite score 1720 points compared to 476 points by the 10 TOPS AI Boost NPU of the Core Ultra. The Intel machine is using OpenVINO, while the Snapdragon is using Qualcomm SNPE SDK for the test. Don't forget to check out the video review by Erdi Özüağ in the source link below.



Source:
Erdi Özüağ (YouTube)
There are three tests that highlight the performance of the key components of the SoCs—CPU, iGPU, and NPU. A Microsoft Visual Studio code compile test sees the Snapdragon X Elite with its 12-core Oryon CPU finish the test in 37 seconds; compared to 54 seconds by the Core Ultra 7 155H with its 6P+8E+2LP CPU. In the 3DMark test, the Adreno 750 iGPU posts identical performance numbers to the Arc Graphics Xe-LPG of the 155H. Where the Snapdragon X Elite dominates the Intel chip is AI inferencing. The UL Procyon test sees the 45 TOPS NPU of the Snapdragon X Elite score 1720 points compared to 476 points by the 10 TOPS AI Boost NPU of the Core Ultra. The Intel machine is using OpenVINO, while the Snapdragon is using Qualcomm SNPE SDK for the test. Don't forget to check out the video review by Erdi Özüağ in the source link below.



55 Comments on Qualcomm Snapdragon X Elite Benchmarked Against Intel Core Ultra 7 155H
Otherwise I don't know what's up with that 7856w celeron J :D.
Still the power graph don't show Apple silicon. Or I'm blind.