Samsung Electronics Announces Second Quarter 2023 Results
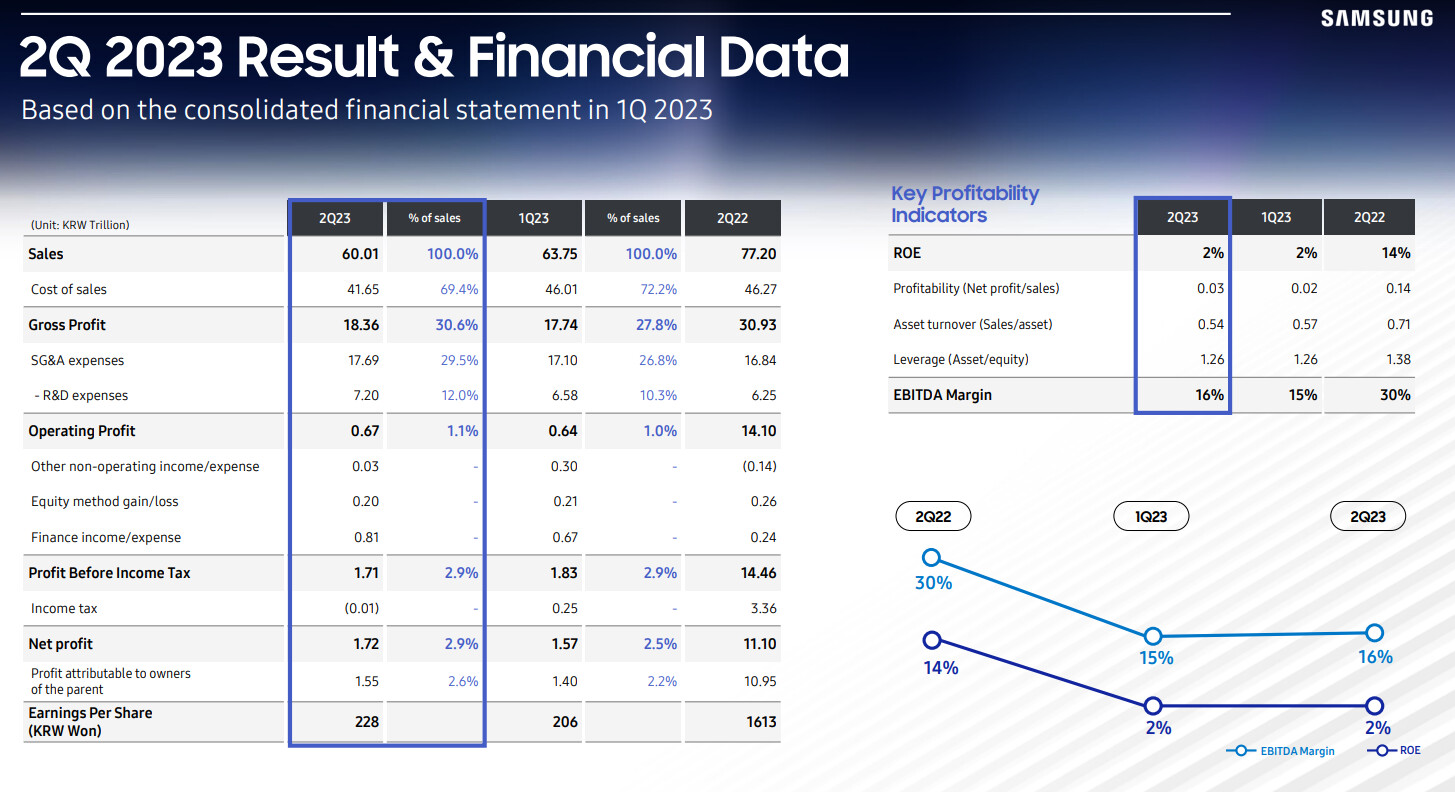
Samsung Electronics today reported financial results for the second quarter ended June 30, 2023. The Company posted KRW 60.01 trillion in consolidated revenue, a 6% decline from the previous quarter, mainly due to a decline in smartphone shipments despite a slight recovery in revenue of the DS (Device Solutions) Division. Operating profit rose sequentially to KRW 0.67 trillion as the DS Division posted a narrower loss, while Samsung Display Corporation (SDC) and the Digital Appliances Business saw improved profitability.
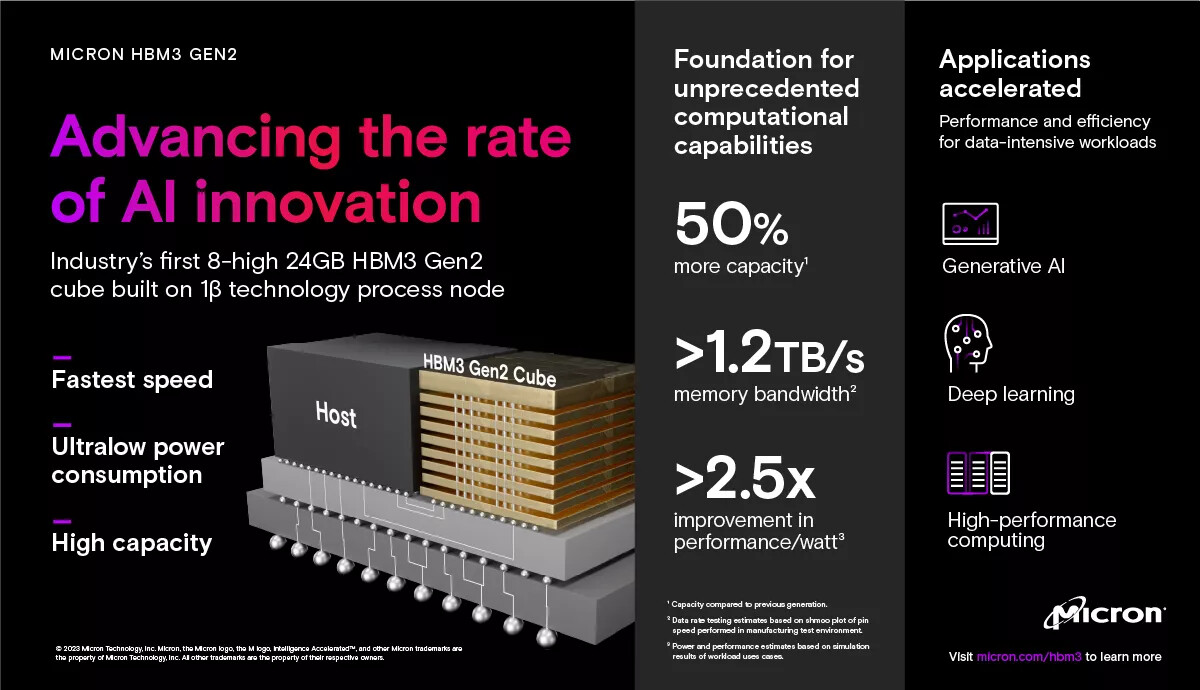
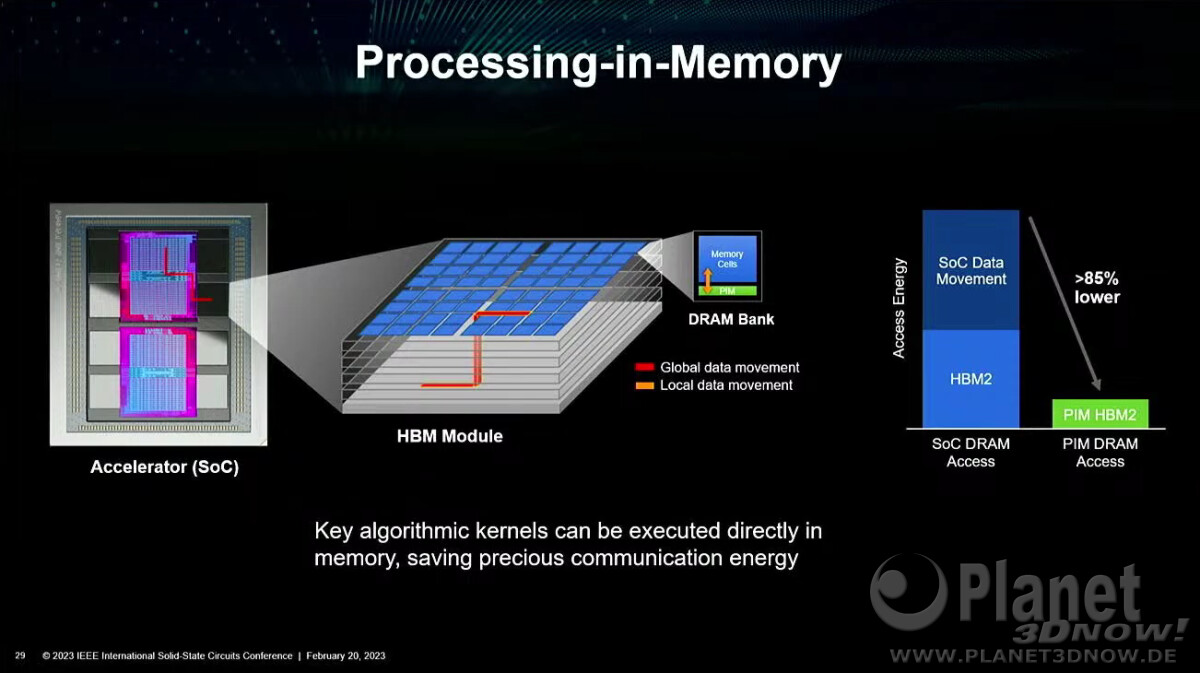
The Memory Business saw results improve from the previous quarter as its focus on High Bandwidth Memory (HBM) and DDR5 products in anticipation of robust demand for AI applications led to higher-than-guided DRAM shipments. System semiconductors posted a decline in profit due to lower utilization rates on weak demand from major applications.



The Memory Business saw results improve from the previous quarter as its focus on High Bandwidth Memory (HBM) and DDR5 products in anticipation of robust demand for AI applications led to higher-than-guided DRAM shipments. System semiconductors posted a decline in profit due to lower utilization rates on weak demand from major applications.