SiPearl to Manufacture its 72-Core Rhea HPC SoC at TSMC Facilities
SiPearl has this week announced their collaboration with Open-Silicon Research, the India-based entity of OpenFive, to produce the next-generation SoC designed for HPC purposes. SiPearl is a part of the European Processor Initiative (EPI) team and is responsible for designing the SoC itself that is supposed to be a base for the European exascale supercomputer. In the partnership with Open-Silicon Research, SiPearl expects to get a service that will integrate all the IP blocks and help with the tape out of the chip once it is done. There is a deadline set for the year 2023, however, both companies expect the chip to get shipped by Q4 of 2022.
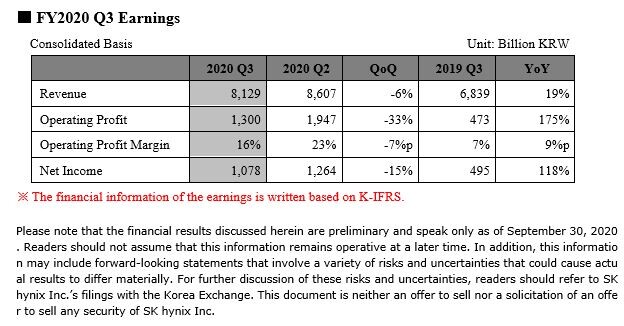
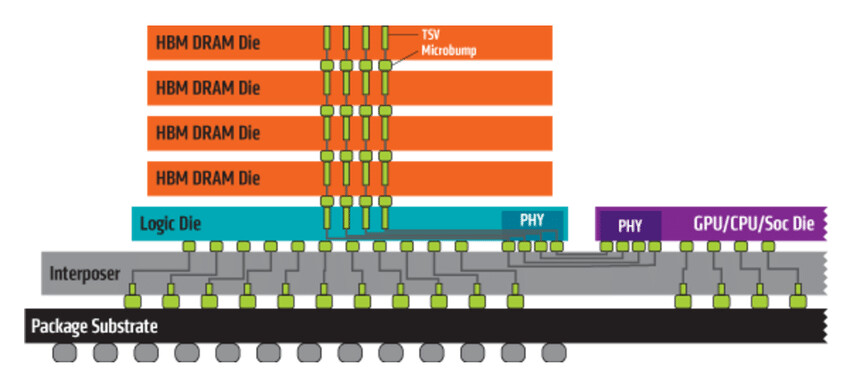
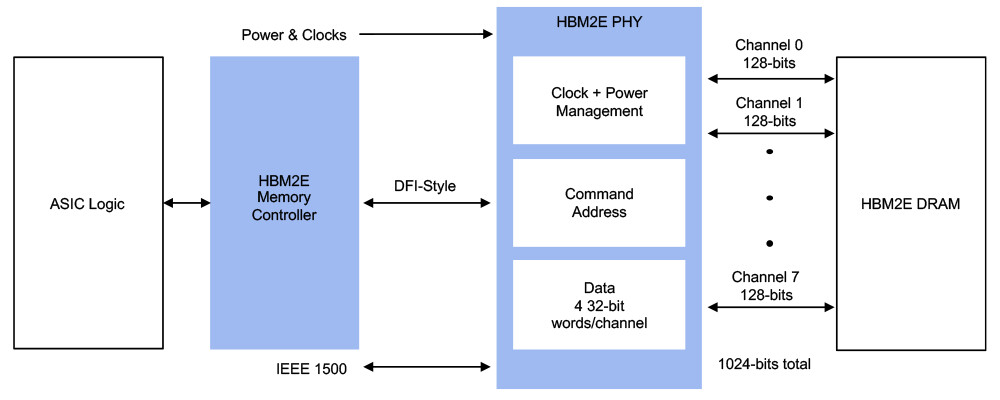
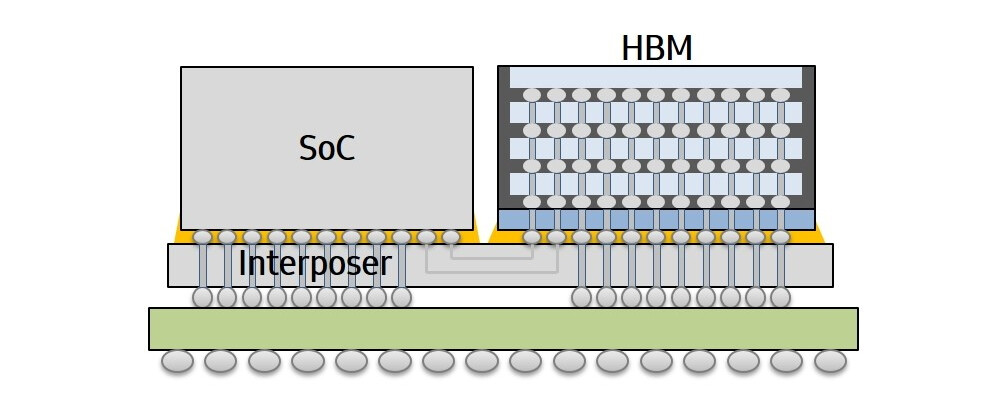
When it comes to details of the SoC, it is called Rhea and it will be a 72-core Arm ISA based processor with Neoverse Zeus cores interconnected by a mesh. There are going to be 68 mesh network L3 cache slices in between all of the cores. All of that will be manufactured using TSMC's 6 nm extreme ultraviolet lithography (EUV) technology for silicon manufacturing. The Rhea SoC design will utilize 2.5D packaging with many IP blocks stitched together and HBM2E memory present on the die. It is unknown exactly what configuration of HBM2E is going to be present. The system will also see support for DDR5 memory and thus enable two-level system memory by combining HBM and DDR. We are excited to see how the final product looks like and now we wait for more updates on the project.
When it comes to details of the SoC, it is called Rhea and it will be a 72-core Arm ISA based processor with Neoverse Zeus cores interconnected by a mesh. There are going to be 68 mesh network L3 cache slices in between all of the cores. All of that will be manufactured using TSMC's 6 nm extreme ultraviolet lithography (EUV) technology for silicon manufacturing. The Rhea SoC design will utilize 2.5D packaging with many IP blocks stitched together and HBM2E memory present on the die. It is unknown exactly what configuration of HBM2E is going to be present. The system will also see support for DDR5 memory and thus enable two-level system memory by combining HBM and DDR. We are excited to see how the final product looks like and now we wait for more updates on the project.