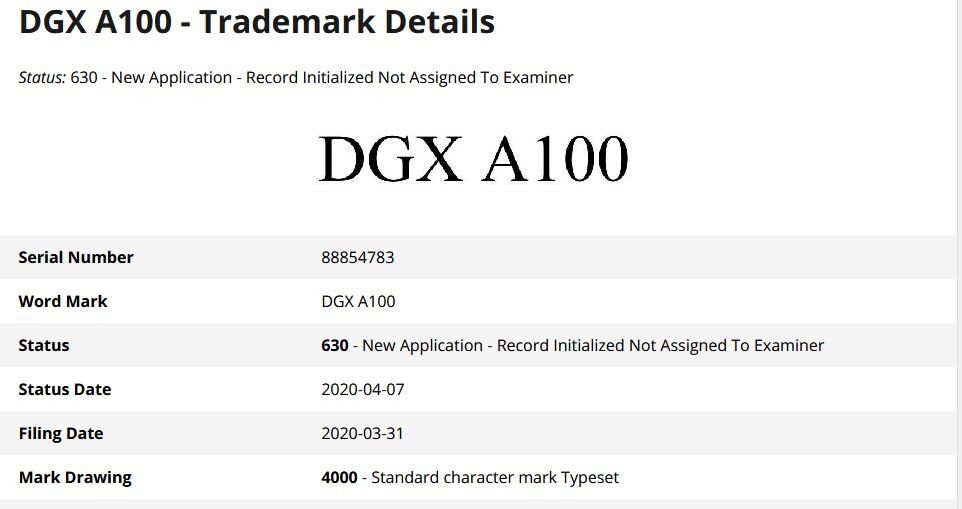
Samsung Expands its Foundry Capacity with A New Production Line in Pyeongtaek
Samsung Electronics Co., Ltd., a world leader in advanced semiconductor technology, today announced plans to boost its foundry capacity at the company's new production line in Pyeongtaek, Korea, to meet growing global demand for cutting-edge extreme ultraviolet (EUV) solutions.
The new foundry line, which will focus on EUV-based 5 nanometer (nm) and below process technology, has just commenced construction this month and is expected to be in full operation in the second half of 2021. It will play a pivotal role as Samsung aims to expand the use of state-of-the-art process technologies across a myriad of current and next generation applications, including 5G, high-performance computing (HPC) and artificial intelligence (AI).
The new foundry line, which will focus on EUV-based 5 nanometer (nm) and below process technology, has just commenced construction this month and is expected to be in full operation in the second half of 2021. It will play a pivotal role as Samsung aims to expand the use of state-of-the-art process technologies across a myriad of current and next generation applications, including 5G, high-performance computing (HPC) and artificial intelligence (AI).