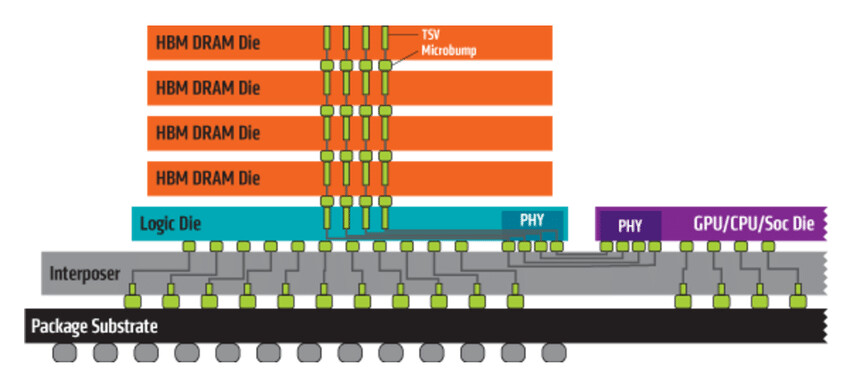
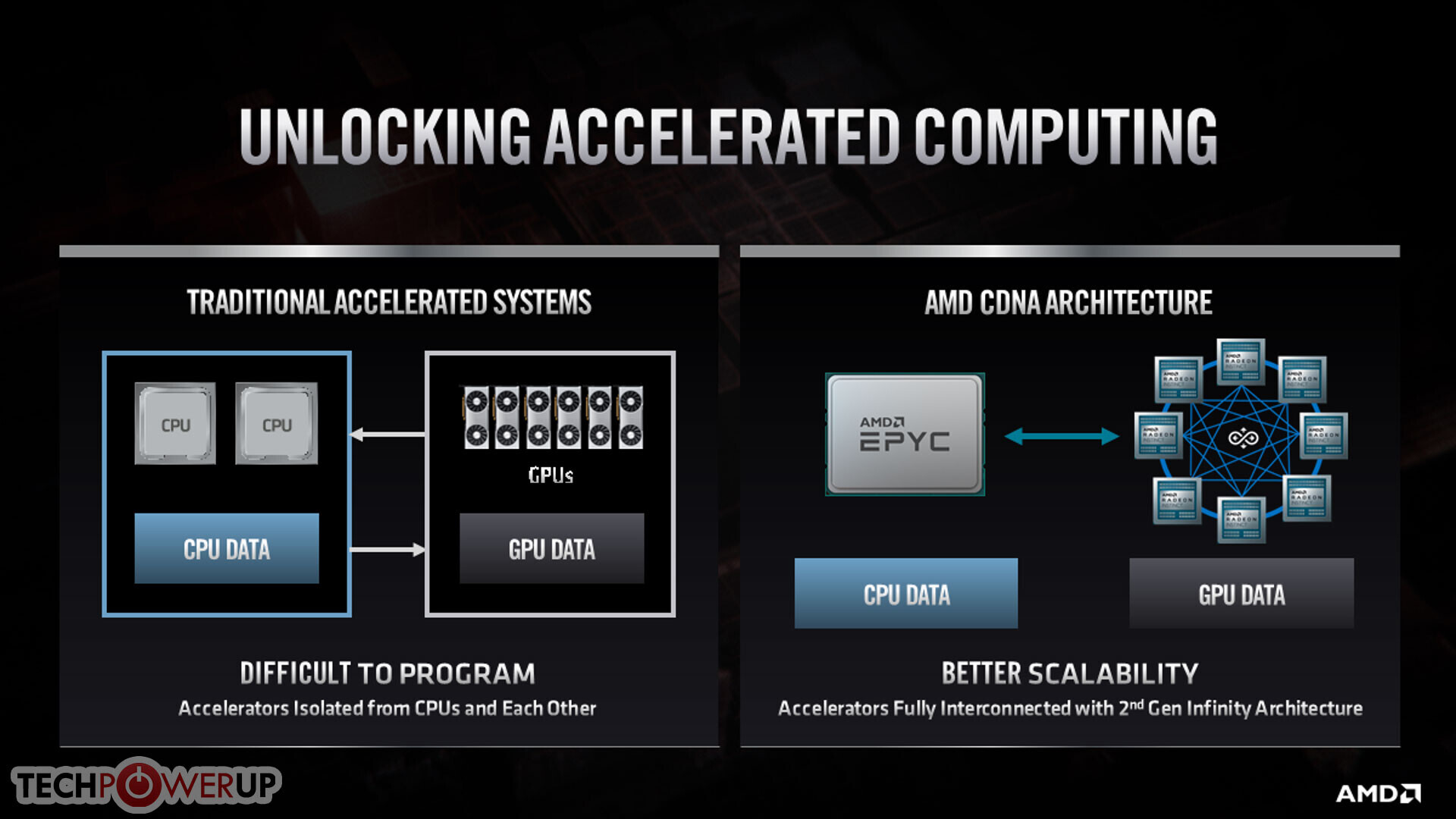
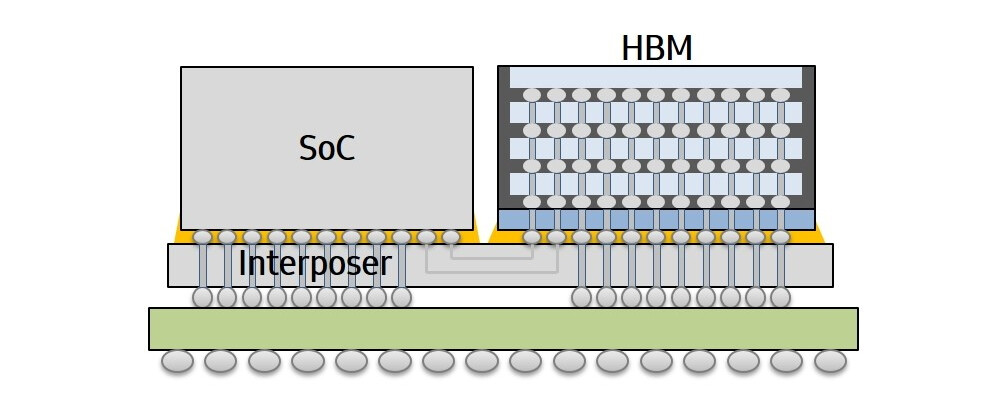
Intel Teases "Big Daddy" Xe-HP GPU
The Intel Graphics Twitter account was on fire today, because they posted an update on the development of the Xe graphics processor, mentioning that samples are ready and packed up in quite an interesting package. The processor in question was discovered to be a Xe-HP GPU variant with an estimated die size of 3700 mm², which means we sure are talking about a multi-chip package here. How we concluded that it is the Xe-HP GPU, is by words of Raja Koduri, senior vice president, chief architect, general manager for Architecture, Graphics, and Software at Intel. He made a tweet, which was later deleted, that says this processor is a "baap of all", meaning "big daddy of them all" when translated from Hindi.
Mr. Koduri previously tweeted a photo of the Intel Graphics team at India, which has been working on the same "baap of all" GPU, which suggests this is a Xe-HP chip. It seems that this is not the version of the GPU made for HPC workloads (this is reserved for the Xe-HPC GPU),this model could be a direct competitor to offers like NVIDIA Quadro or AMD Radeon Pro. We can't wait to learn more about Intel's Xe GPUs, so stay tuned. Mr. Koduri has confirmed that this GPU will be used only for Data Centric applications as it is needed to "keep up with the data we are generating". He has also added that the focus for gaming GPUs is to start off with better integrated GPUs and low power chips above that, that could reach millions of users. That will be a good beginning as that will enable software preparation for possible high-performance GPUs in future.
Update May 2: changed "father" to "big daddy", as that's the better translation for "baap".
Update 2, May 3rd: The GPU is confirmed to be a Data Center component.


Mr. Koduri previously tweeted a photo of the Intel Graphics team at India, which has been working on the same "baap of all" GPU, which suggests this is a Xe-HP chip. It seems that this is not the version of the GPU made for HPC workloads (this is reserved for the Xe-HPC GPU),
Update May 2: changed "father" to "big daddy", as that's the better translation for "baap".
Update 2, May 3rd: The GPU is confirmed to be a Data Center component.