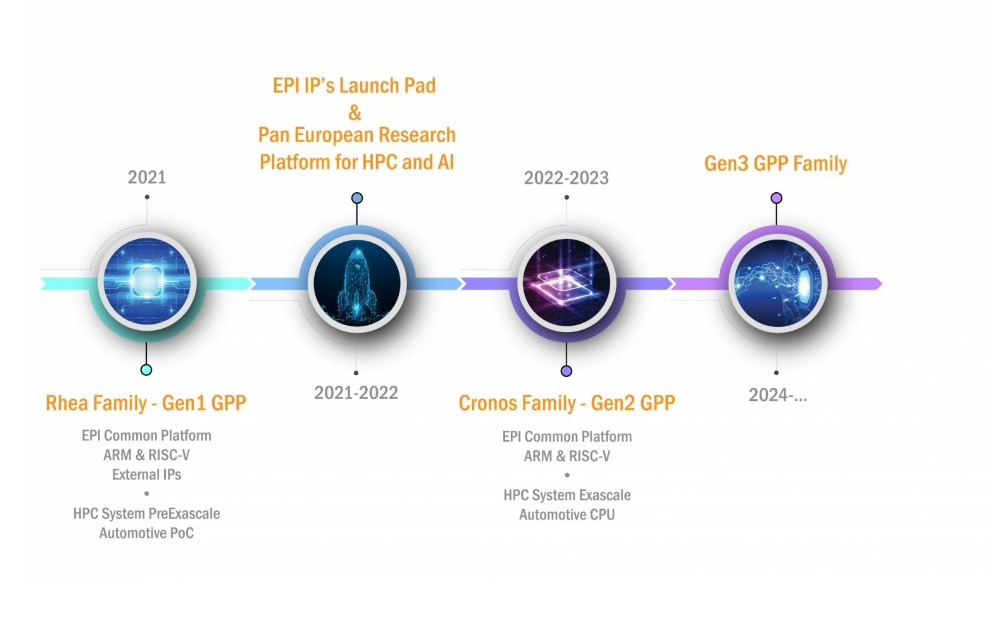
NVIDIA Brings CUDA to ARM, Enabling New Path to Exascale Supercomputing
NVIDIA today announced its support for Arm CPUs, providing the high performance computing industry a new path to build extremely energy-efficient, AI-enabled exascale supercomputers. NVIDIA is making available to the Arm ecosystem its full stack of AI and HPC software - which accelerates more than 600 HPC applications and all AI frameworks - by year's end. The stack includes all NVIDIA CUDA-X AI and HPC libraries, GPU-accelerated AI frameworks and software development tools such as PGI compilers with OpenACC support and profilers. Once stack optimization is complete, NVIDIA will accelerate all major CPU architectures, including x86, POWER and Arm.
"Supercomputers are the essential instruments of scientific discovery, and achieving exascale supercomputing will dramatically expand the frontier of human knowledge," said Jensen Huang, founder and CEO of NVIDIA. "As traditional compute scaling ends, power will limit all supercomputers. The combination of NVIDIA's CUDA-accelerated computing and Arm's energy-efficient CPU architecture will give the HPC community a boost to exascale."
"Supercomputers are the essential instruments of scientific discovery, and achieving exascale supercomputing will dramatically expand the frontier of human knowledge," said Jensen Huang, founder and CEO of NVIDIA. "As traditional compute scaling ends, power will limit all supercomputers. The combination of NVIDIA's CUDA-accelerated computing and Arm's energy-efficient CPU architecture will give the HPC community a boost to exascale."